AI场景
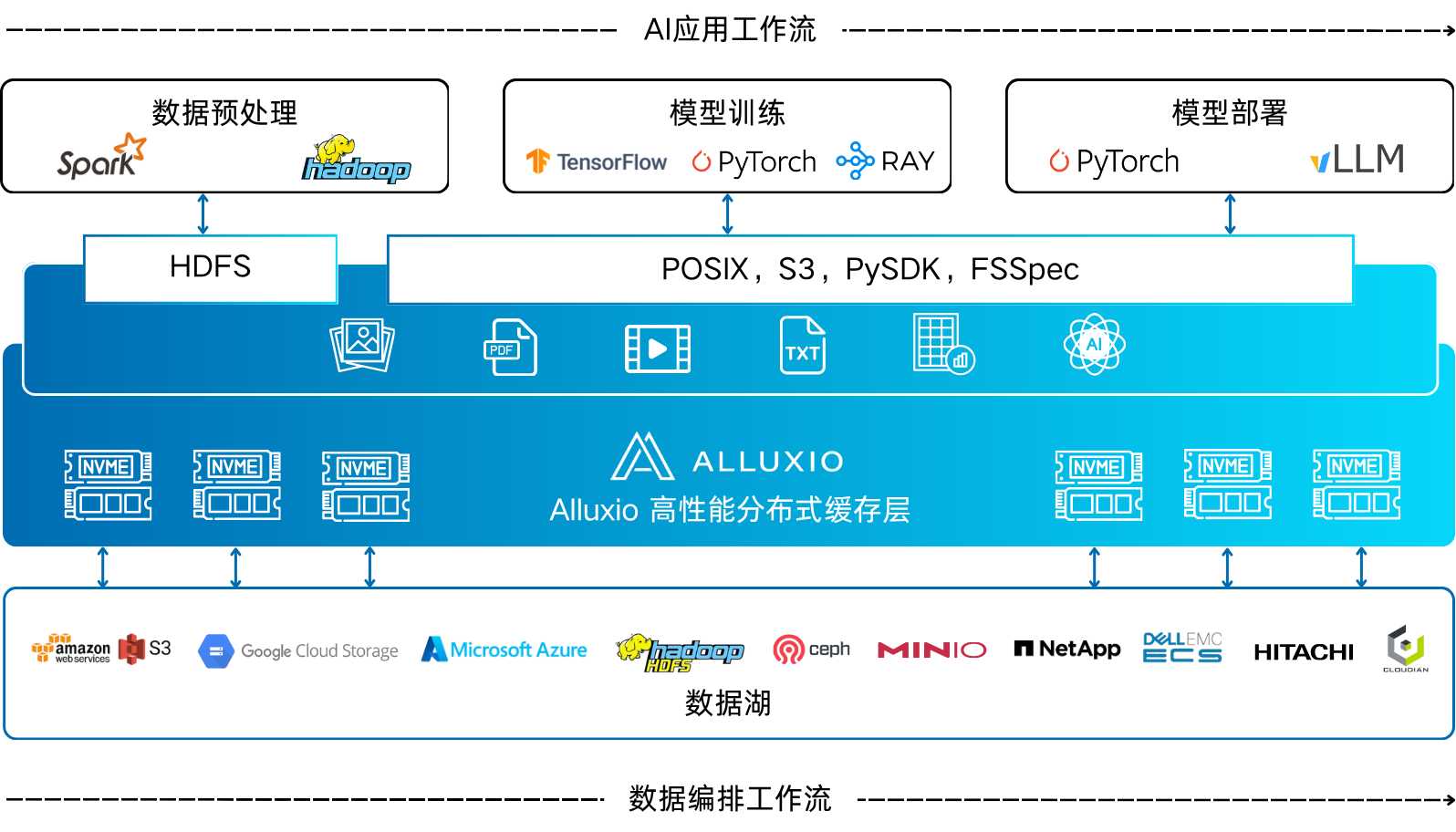
显著优化从数据预处理、模型训练到模型部署等整个数据管道的I/O效率
Alluxio可以和GPU节点混合部署,介于GPU和对象存储之间,利用GPU节点的CPU、NVMe资源,提供以下能力:
统一数据视图:Alluxio能够整合分布在对象存储、HDFS等不同存储系统中的数据,提供一个统一的访问入口 。这简化了数据管理,让算法和标注人员无需关心数据的具体物理位置。
突破数据读取瓶颈:训练框架通过Alluxio提供的POSIX、S3或Python API接口访问数据 。Alluxio将训练数据集缓存在GPU集群本地,实现高吞吐、低延迟的数据供给,从而将GPU利用率提升至90%以上,避免昂贵GPU因等待数据而闲置 。
加速Checkpoint:模型训练需要定期保存检查点,这是一个写入密集型的操作。Alluxio可以对此进行优化:先将Checkpoint以内存或磁盘速度写入本地缓存,然后异步上传到远端持久化存储。这种方式可以大幅缩短GPU等待写入完成的时间,加快训练迭代速度 。
加速模型分发:Alluxio可以作为高性能的模型分发层,将训练好的模型文件缓存到推理服务器附近。与直接从小文件众多的对象存储中加载模型相比,通过Alluxio模型部署速度最高可达对象存储的10倍以上 。