





我们利用GPU本身的SSD硬盘来搭建Alluxio集群,并且通过Alluxio的多副本特性来解决跨机器、跨AZ拉取文件的问题,不仅能够对带宽带来极大的减少,还能降低对文件存储的Burst流量,让直接文件读取效率提升了85%。
我们已在双集群的百节点部署了Alluxio,整体可用性达到99.95%,缓存命中超过95%+,支持着PB级百亿海量文件的的千卡训练集群规模,为鉴智机器人的大规模AI视觉训练提供了高性能、高可靠、低成本的加速方案,成为自动驾驶技术迭代的“数据引擎”。
Alluxio的缓存机制通过内存级数据加速,大幅降低了我们数据访问延迟,提升了训练效率,并充分发挥了GPU算力价值,利用率提升超过10%,训练任务端到端用时减少了20-30%。
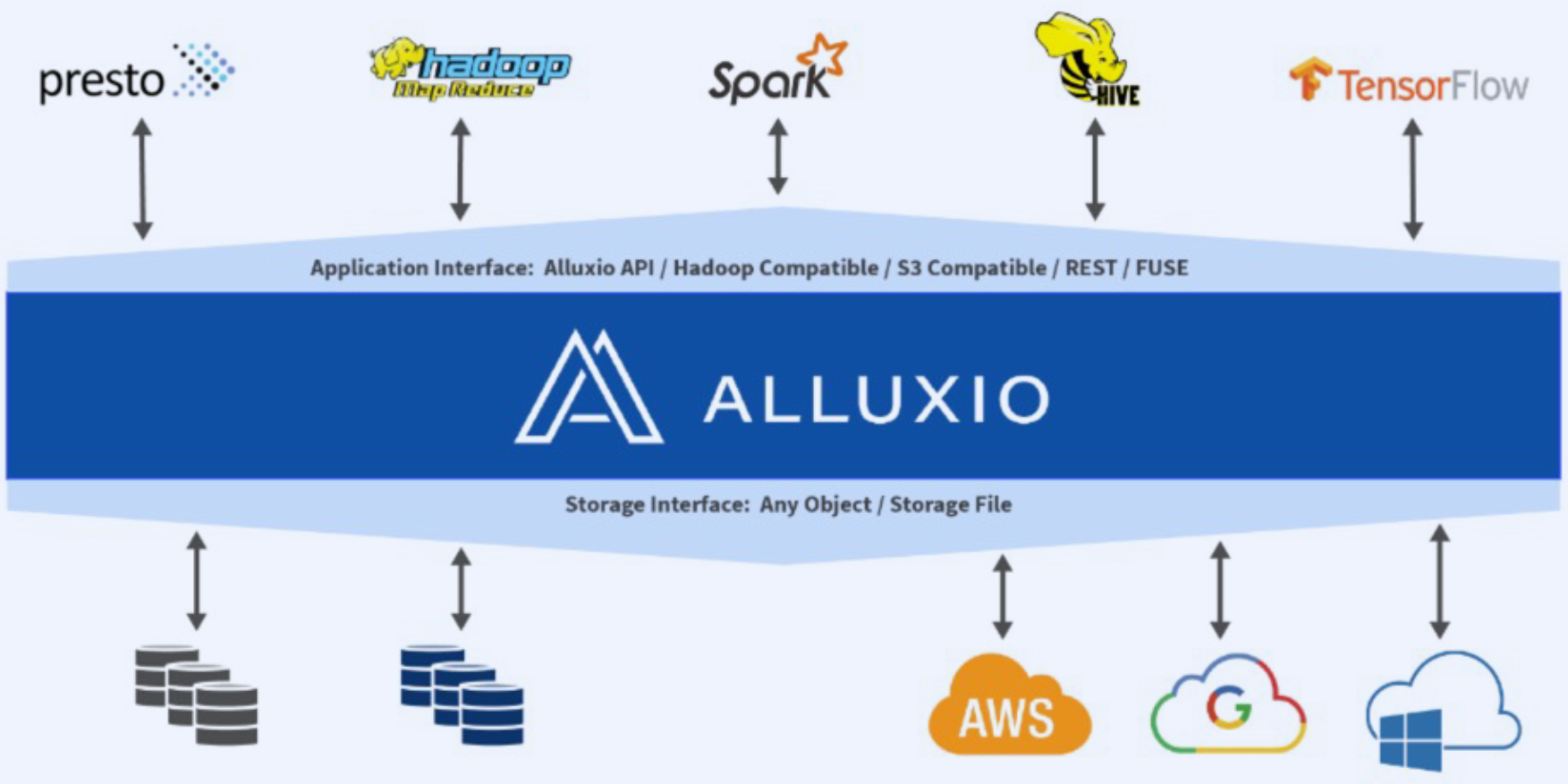
Alluxio 无论是在多机还是单节点的训练和推理上,完全都可以通过分布式的缓存高效加载我们需要的数据,并且alluxio worker 节点非常容易扩容。目前我们底层的存储如HDFS,Ceph和SeaweedFS都是通过Alluxio进行访问。
Alluxio作为我们基础模型训练架构中的数据加速层,不仅显著提升了训练效率,也为我们的商业化落地提供了坚实的支撑。基础模型训练速度提升高达35%。"这一提升直接转化为更快的产品迭代和更低的研发成本。
“在引入 Alluxio 之前,我们每周都要花费数小时来手动管理模型分发 pipeline 和冷启动时间。借助 Alluxio 的分布式缓存,我们彻底消除了冷启动延迟,原本需要数小时的任务现在只需几分钟即可完成。该解决方案能无缝适应我们的业务增长,让工程团队得以专注于功能开发,而无需耗费大量精力维护基础设施。”
“借助 Alluxio,我们成功为机器学习交易模型打造了必要的低延迟特征存储。它将我们离线特征存储的多表连接查询延迟降低至两位数毫秒级,让我们得以在15分钟的交易窗口内处理超过10万个模型。”
 京公网安备 11010802040260号
京公网安备 11010802040260号



