作者简介

陈寿纬
Alluxio软件工程师,在Alluxio主要负责数据湖方案结合、结构化数据与高可用性优化等相关工作。陈寿纬博士毕业于罗格斯大学电子与计算机工程系,专业方向是大规模分布式系统的性能与稳定性优化。

王北南
Alluxio软件工程师,也是PrestoDB的committer。加入Alluxio之前,北南博士是Twitter Presto团队的技术负责人,并为Twitter的数据平台构建了大规模分布式SQL系统。他在性能优化、分布式缓存和大数据方面有12年的工作经验。王北南博士毕业于雪城大学计算机工程专业,专业方向是对分布式系统进行信号模型检测和运行验证。
活动回顾
在【Iceberg + Alluxio 助力加速数据通道】系列活动中,本次主题演讲将分享开源分布式存储系统Alluxio与Iceberg的基本概念、集成方案与未来的结合方向。
本次活动中我们还分享了我们近期在Presto社区中Iceberg的一些工作与未来的计划。
(以下为本次活动的演讲实录)
Alluxio概览

Alluxio是2014年在伯克利 AMPLab孵化的一个项目,那时候名叫Tachyon,是跟Spark同一期孵化的分布式存储项目。截止到今天为止,我们这个社区里已经有超过1000名的contributor参与搭建了社区代码和各种活动,在Slack committee里面已经有5000以上的 member进行互动,大家也把技术广泛应用在各种开源场景里面。在去年的时候,我们也被谷歌评选为最具影响力的十大 Java-based的开源社区项目,如果大家对这个项目感兴趣的话,欢迎扫描二维码加入我们 slack社区,跟我们进行讨论。


现在Alluxio项目已经广泛地应用在各种不同的大厂和小厂里面,包括互联网企业,云计算的提供商,也包括银行、不同的通讯行业的企业,如果大家感兴趣的话,我们也会进行更多的分享,邀请大家来一起做技术分享,搭建基于Alluxio的技术平台。Alluxio是一个数据编排层,它不仅服务于数据analytics,也服务于AI,我们最主要的场景也是基于cloud的场景。

Alluxio第一个功能是可以使用Alluxio去连接所有的计算引擎和存储系统,如果你上面的系统搭载了 Presto、Spark、 MapReduce、Hive这一类的系统,你可以通过Alluxio去访问下面所有的存储引擎,包括但不仅限于我在这里列的HDFS,S3、GCS、Azure和NFS等,我们有更全面的支持,包括上层的计算引擎和下层的存储系统。
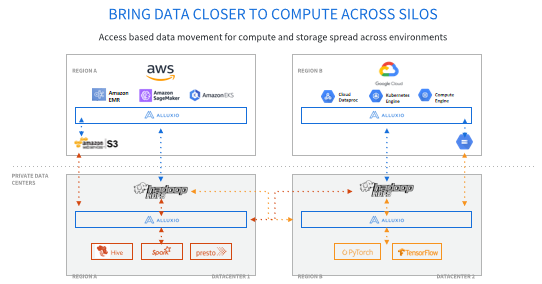
我们的目标是把数据从远端的存储带回到近端的计算里面,因为特别是在云计算、混合计算或者是多数据中心的场景下,存储很多时候都不是跟传统的计算在一起的,所以这时候访问数据就会有很多的问题。在这种场景下,我们需要把数据重新从远端的存储带回到近端的计算上面达成更高效的访问。
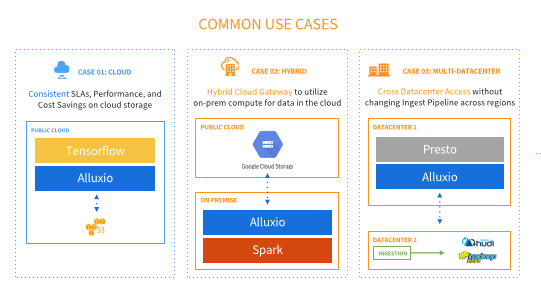
最主要的应用用例有三个:
第一个用例是云计算的场景,云计算场景一般都是用云计算存储,所以它的性能和稳定性并不是非常的好, 把Alluxio加上去以后,可以达到更好的 SLA一致性,更好的性能,并且可以省去流量,比如说公有云存储的流量使用需要花钱,但我们可以通过caching solution去缓解流量的开销。
第二个场景是混合云计算,比如说我们有一部分的数据是放在公有云里面,有一部分数据还放在传统的私有云里面,如果私有云的数据想去访问公有云,它的带宽是非常受限的,这个时候可以把Alluxio加进去,成为一个缓存层,来缓解这个问题,这就是混合云部署。
第三个场景是一个多计算中心解决方案,比如你在北京、上海,兰州都有一个数据中心,可以在这种场景下部署Alluxio去加速应用场景。

我们的发展主要有下面三个方向,我们一直强调Alluxio虽然是一个缓存层的组件,但它不仅仅是一个缓存层。
第一个组件就是unify data lake,可以理解为支持不同的API向上层的计算引擎,也可以向下支持不同的存储系统,你只要管理好 Alluxio的一套 API,就可以管理好整套的data lake solution。
第二个是可以更有效地获取数据并管理数据,这也是缓存层主要的功能,主要是给业务进行加速。我们也提供data policy引擎,比如说你想把数据从一个HDFS集群移动到另一个HDFS集群,可以通过policy engine定时并且定量地进行数据移动,从而更好地管理数据集群。
第三个是多云部署。拿美国这边打个比方,比如说你需要用AWS的 S3, 同时要用GCP的BigQuery引擎,你可以进行混合云的部署,也就是说你可以在 GCP里面部署Alluxio集群去query S3的数据,这样就可以更好地搭建混合云。
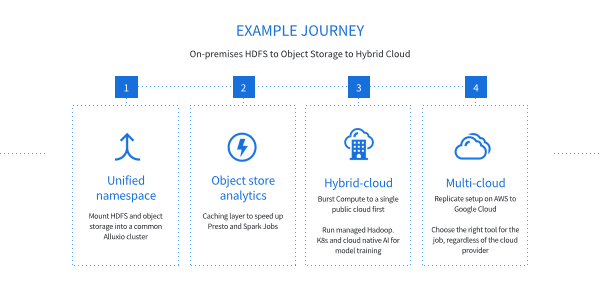
举例
在国内比较常见的场景是从私有云的HDFS到混合云的对象存储,其中我们提供几个功能,第一个叫unified name space,你可以把 HDFS集群和对象存储的集群都mount到一个统一的Alluxio cluster里面进行管理,提供完整的基于对象存储的一套分析解决方案。在这种场景下,比较常见到的是混合云部署,就是说既有公有云也有私有云。

我们来看一下部署的架构,在这个场景里,有两个不同的公有云提供商,一个是AWS,一个是Google Cloud。在AWS和Google Cloud里面我们都部署了Alluxio集群。其中第三个集群是一个private cluster,就是私有云的集群,我们也同时部署了Alluxio,它的底层其实是一个MINIO集群,也就是说MINIO的集群同时提供了数据服务给两个公有云和一个私有云,而在这种场景下,你可以用Alluxio作为缓存加速提供给不同的上层计算引擎,包括在AWS上的 EMR Google cloud dataproc和包括在私有云下面自己搭建的Hive, Spark和Presto场景,你可以达成一个完整的循环,不需要用私有云里面的MINIO提供非常低的性能,去给不同的公有云和私有云计算引擎。
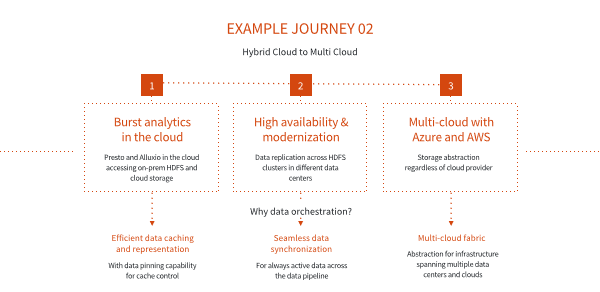
混合云到多个云的场景
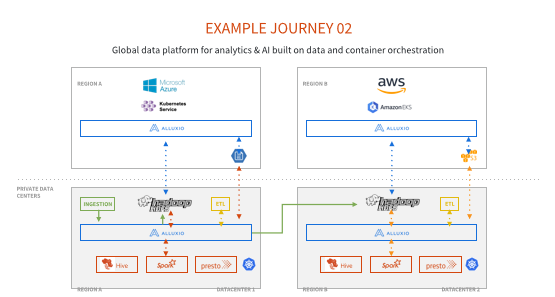
大家可以看到,同样是两个公有云提供商,左边是Microsoft Azure,右边是AWS,可以看到下面ETL job和Ingestion都会直接写到Alluxio里面,在这种场景下,你可以选择写入Alluxio的方式,把这个数据写回到底层的 HDFS上面去, 然后Alluxio会把这个数据分享给不同的数据中心,包括右边的HDFS集群和上面的几个公有云的Alluxio集群。在这种搭建下,只需要一个Alluxio集群,就可以实现数据共享,不需要搭建 ETL数据通道,再去把所有的数据写回到不同的HDFS 集群和另外的Alluxio或者是云计算的对象存储里面。
ceberg概览

Iceberg是一种开放式的table format,它主要是作为对标 Hive的一种文件,是一种表格存储的格式,主要的应对场景是比较大型的数据分析场景。它提供几种不同的功能,主要有 Schema evolution,hidden partitioning,partition layout evolution 和time travel,还提供version rollback的功能,很多功能是专门为了满足美国关于数据隐私法案的需求,提供事务性的支持。相对于Hive很难实现事务性的支持,Apache Iceberg提供了更好的支持。

Iceberg的schema evolution都是基于元数据操作的,没有任何的数据操作,可以增加column,drop column,可以rename column,也可以更新 column struct field,map key,map value或者 list element,甚至可以reorder,change the order of column or field in a nested struct。其实他们现在也支持z-ordering这种格式,为了让数据能得到更好的加速效果。
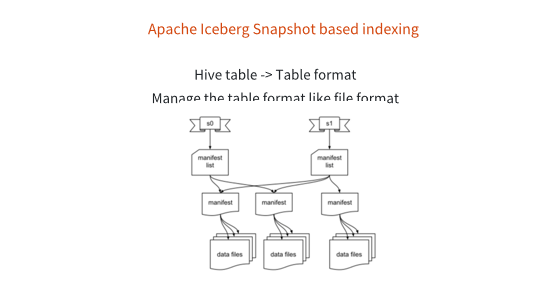
那么它是怎么实现事务性支持呢?它用了比较传统的数据库的理念,就是snapshot,它的不同的表格版本,是用snapshot来保护的,snapshot下面有一系列的manifest file来表征这个表在某一个特殊的时间点,比如说在11月27号,它是一个 snapshot,有可能过比如说一个小时或者是一天,它就更新一个snapshot,所以每个表格是通过snapshot去保证它的不同的版本的数据的一致性。
接下来我们来看一下为什么 Iceberg提出了这种方案。
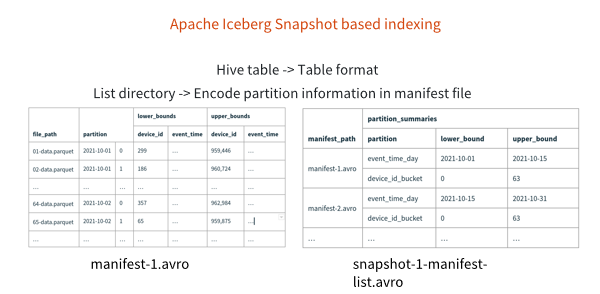
在大数据数据库的领域,大家原来都是用 Hive table,但是大家发现Hive table有很多问题,它就变成了一个table format。主要问题有我认为有两种,第一个是Hive table不支持事务性的,所以要支持 ACID非常困难。第二个是Hive table 是directory-based mechanism,所以每次去获取这个表格的全貌,都要通过底层的存储系统去list directory。在表格小的情况下,这不是一个非常重的开销,但如果是一个非常大的表格,比如说有上万个或者是上百万个partition的表格,开销会非常的昂贵,所以他们就提出一个概念叫encoding partitioning Information in manifest file,等于说它不需要通过 directory-based的概念去做这个事情了,而是把所有的数据都include到 table format里面去,直接去解析这个文件,来获取所有的文件位置。
然后我们可以看一下,比如说在右边manifest list里面,它会标注 manifest file在哪里,比如说manifest-1.avro这个file,它有一个partition的概念,event time是2021年10月11号到2021年10月15号,有一个最小的event date和最大的event date,然后对应到左边就可以找到 manifest file,这个 manifest file会对应所有的 Parquet文件,因为我们知道Parquet文件是通过最小值和最大值去做 predicate pushdown,等于说在这个概念里面,它就把所有的最小值和最大值都include到Iceberg的metadata里面去了,就不需要去list directory,去fetch parquet header获取做 predicate pushdown的元数据,而是可以一次性把所有的数据都拉过来,进行indexing的操作。大家如果对Iceberg的indexing比较感兴趣的话,我推荐大家去看下面的 tabular log,这是Ryan最新写的关于Iceberg如何做indexing的非常详细的blog,大家如果感兴趣可以看一下。
Alluxio+Iceberg 集成方案
我们发现Alluxio提供的是数据层面的东西,而 Iceberg提供的是表格层面的东西,它们两个关系非常远,但是为什么我们要把Alluxio的方案和 Iceberg的方案进行集成,我想来回答一下大家的问题。

首先我们发现,现在构筑一个大数据方案,是希望得到一个完整的方案,而不是只用一个Iceberg或Alluxio就可以完成一个数据湖的搭建,事实上自上而下需要很多不同的组件去组成一个数据湖的方案。比如说,如果是基于Iceberg,很有可能上面需要有元数据的管理层,下面是Iceberg这样的元数据format底层,再下面有可能是利用Presto或者Spark等不同技术搭建了 ETL或者OLAP的计算引擎层,然后再下面有可能是Alluxio这样的缓存层,最下面有可能是你自己的一些云计算存储或者HDFS存储。所以我们看到很多用户非常关心整个业务逻辑的搭建,认为Alluxio方案需要跟Iceberg进行集成。
那么现阶段Alluxio给Iceberg提供了哪些优势?
1.不管Iceberg放在私有云、公有云还是多云环境下面,Alluxio都可以给整个数据通道进行加速,给业务逻辑提供更好的数据本地性。
2.因为Iceberg相比Hive, 没有自己的服务去管理这些 file format,如果你要进行数据迁移,会比较麻烦,特别是比如说现在 Iceberg支持最好的是Hadoop,也就是基于HDFS那套接口,如果你要把这个方案迁移到比如说S3或者Azure上面,就会有一些问题,在这种场景下,如果用Alluxio,你只要用一套方案就可以解决所有的问题,不需要将不同的存储方案一个个地跟Iceberg进行适配,这其实在很多场景下是一件非常麻烦的事情。
3.很多公司的底层存储并不保证read-after-write strong consistent,那么你想要实现Iceberg的方案就非常困难,但是Alluxio可以避免这一点,你可以把这个文件写到Alluxio里面,Alluxio可以保证strong consistent的操作,你可以用Alluxio直接基于现在已有的 eventual consistent的系统来搭建数据湖。
我们下面来说一下,在已有的场景下,怎么将Iceberg的方案和Alluxio的方案进行集成。

为什么说集成需要比较小心,其实作为一个缓存层,我们不是在所有场景下完全的支持强一致性的,因为我们的写入有很多种方式,第一种是MUST_CACHE,在这种方式下,我们会把数据直接写入Alluxio,不写入底层的 HDFS集群或者S3集群。第二种方式叫THROUGH,一般不太关心写入的数据,后面要再被重复应用,所以不想把这个数据写回缓存层,直接写回底层的分布式存储。第三种是CACHE_THROUGH,就是同时写入Alluxio系统和底层的 S3或者HDFS。第四种方式是Eventual consistent的模式,写回Alluxio是strong consistent,但最后写回底层的存储,是一个Eventual consistent的模式。很多人会采用这种模式,因为比如说 object store s3的rename特别的昂贵,这种情况下,我们推荐通过ASYNC_THROUGH的方式写入,但有时候这个方式,对不同的基于Iceberg的数据湖方案就会有一些不同的影响。
架构推荐
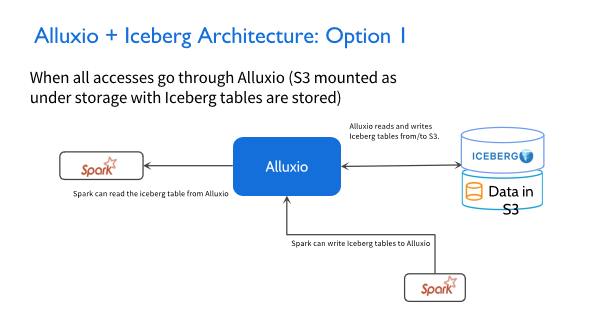
第一种架构比较简单,我们拿 Spark和AWS举个例子,左边 Spark是在私有云的场景,右边Spark是在公有云的场景,在这两个场景里都同时会写入Alluxio集群。所以在这种场景下,读写这两条线都没有太大的问题。因为这一端的强一致性是在Alluxio这层保护的,所以数据对Iceberg的事务性支持就可以得到非常好的控制。
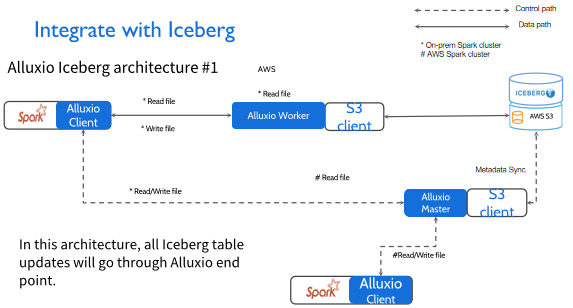
第二个场景比较复杂,也是很多用户常用的一种模式。比如在私有云场景里,我是写回Alluxio里面的,但在公有云里面我不希望通过Alluxio写回,因为我已经在AWS里面Run EMR job,所以我希望直接写回S3就可以得到一个比较好的性能。
第二个场景比较复杂,也是很多用户常用的一种模式。比如在私有云场景里,我是写回Alluxio里面的,但在公有云里面我不希望通过Alluxio写回,因为我已经在AWS里面Run EMR job,所以我希望直接写回S3就可以得到一个比较好的性能。
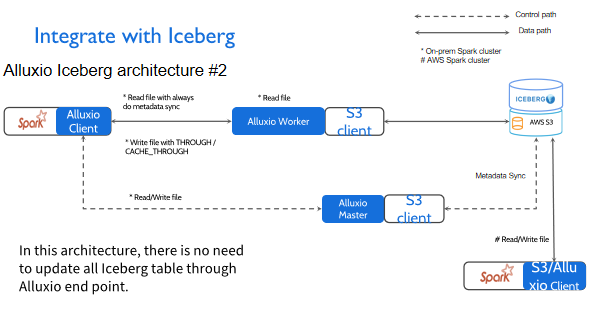
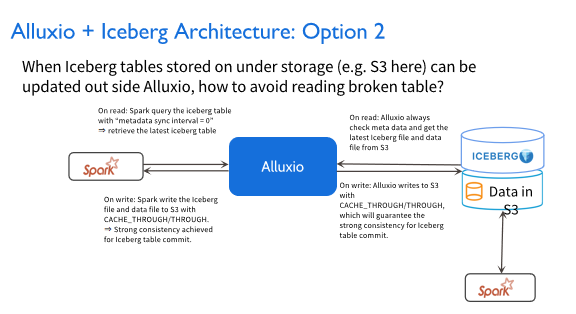
就算Spark job在AWS上面运行时拉取Iceberg的表格,它也可以拉取到最新的表格,而不是说通过ASYNC_THROUGH的方式,有可能你写进去过了几分钟或者是几十秒,你才发现这个表格更新了,此时你没有办法去update Iceberg的表格,也就没有办法保证数据的一致性。像AWS这种系统,它不提供 push机制告知更新,所以这种场景下我们一般会有一个周期性的检查,检查AWS是否更新,在这种场景下,我们推荐你在读Iceberg文件之前,总是进行元数据的同步操作,保证你每次拉取的数据都是最新的数据。
本次分享就到这里,谢谢大家。








