


问题描述
有时候大数据分析需要同时处理来自两个不同存储系统的输入数据。例如,数据科学家可能需要联接(join)两张分别来自HDFS 集群和 S3的表。
现有方案
某些计算框架可以连接到存储系统,包括 HDFS 和主流的云存储(如 S3 或 Azure blob 存储)。例如,在 Hive 中,每个外部表都可以指向不同的存储系统。虽然该方案设置起来较简单,但可能存在性能问题。例如,即使计算与 HDFS 部署在一起,但在数仓中运行计算,从云存储读取数据可能会很慢。同样地,在云环境中运行工作负载或许能有效地读取云存储,但从本地 HDFS 获取数据也可能会很慢。此外,当机器学习或科学计算算法负载需要重复读取相同的输入数据时,这个问题可能会更严重。
另一种常见的解决方案是进行输入数据准备时,将输入数据从某个集群(例如云存储)移动到 HDFS中。这通常需要数据工程师事先构建 ETL 工作流,因此会增加数据管理和同步的复杂性。
ALLUXIO 能带来哪些益处
Alluxio 可以作为 HDFS 和 S3 或其他云存储系统上层的数据抽象层,来提供 统一的文件系统命名空间。在这种情况下,数据应用程序可以将alluxio 作为一个“逻辑文件系统”,文件系统中的不同目录连接到外部存储系统。从远端存储读取数据对用户应用是透明的。 Alluxio的优势还包括提供数据缓存功能,从而加速对同一组文件的重复读取等。
问题描述
在本地服务器或集群上使用TensorFlow 等框架来训练模型,并使用 S3 或 Google Cloud Storage 等远端共享存储来存海量输入数据,这种做法越来越普遍地被数据科学家们所采用。上述技术栈提供了较高的灵活性和成本效益,尤其是不需要开发人员来管理和维护数据。但是,将数据从远端存储移动到本地用于训练,对于要在同一输入上进行多次迭代的数据访问模式而言效率十分低下。
现有方案
实践中常见的解决方案是将数据复制并分发到模型训练服务器的本地或附近位置的存储中。这一数据准备过程通常需要手动或在脚本中维护, 如果数据规模很大,则可能很慢、容易出错并且难以管理。此外,也很难协调多个模型训练作业之间的数据共享(例如,不同的实例同时搜索参数空间或者团队中的不同成员同时处理同一数据集)。
ALLUXIO 能带来哪些益处
理想情况下,将训练数据从远端拉取到本地的数据准备过程以及实现数据共享的过程应该是自动且对应用程序透明的。当部署了Alluxio 数据编排层后,Alluxio 可以将数据提供给 TensorFlow,从而提高端到端的模型开发效率。例如,Alluxio 可以与训练集群并置(co-locate)部署,通过Alluxio POSIX 或 与HDFS兼容的 接口访问训练数据,而数据存储在挂载的远程存储(如 S3)中。我们可以把训练数据从远端存储预加载到Alluxio,也可以按需缓存。要了解更多详细信息,请查看文档。
随着企业内的数据生态系统不断扩大,不仅总数据量在增加,数据存放的各类存储系统也在增多。企业面临的挑战变成如何让不同的应用程序和团队有效地访问各子系统中的数据,而不必花费大量的时间来构建数据访问工作流。
随着数据生态系统日趋成熟,我们也观察到了一个普遍的趋势。当开发人员和团队无法实现可靠的性能和数据访问时,他们通常会寻求创建新的计算框架、新的存储系统,甚至全新的技术栈。虽然这可以作为一个临时解决方案,但随着时间的推移,它只会凸显当前的问题。
Alluxio认识到,要解决这个问题,就需要新增一个数据编排层, 作为位于计算和存储之间的数据编排平台。尤其是当我们需要确保部署环境能够对计算、存储或云环境无感知时,对数据编排层的需求就更加迫切。
Alluxio 命令行具有易于使用且功能丰富的命令组合,对于任何使用过 posix 环境的开发人员来说都很容易上手。
alluxio@ip-172-31-38-93 alluxio]$ ./bin/alluxio fs ls /
drwxr-xr-x alluxio alluxio 24 PERSISTED 05-28-2019 12:33:47:944 DIR /default_tests_files
drwxr-xr-x alluxio alluxio 3 NOT_PERSISTED 05-28-2019 17:49:30:084 DIR /hdfs
drwxr-xr-x alluxio alluxio 4 NOT_PERSISTED 05-28-2019 17:49:33:295 DIR /s3
drwxrwxrwx alluxio alluxio 2 PERSISTED 05-28-2019 16:40:52:914 DIR /testdfsio
如上所示,通过“ls”命令,我们可以看到能通过 Alluxio 访问的不同存储目录。通过Alluxio fs mount 命令,这些存储被有效地“挂载”到 Alluxio 命名空间中。
这种虚拟化使得开发人员和应用程序团队无需担心具体使用的是哪种计算或存储。只要 Alluxio 能够提供与计算框架或存储兼容的接口,它就可以无缝集成到任何环境中。
有人会在HDFS名称节点(v2.7)响应时间方面遇到严重的性能问题。特别是在流量高峰期,HDFS 名称节点可能会过载,并且某些 DFS 操作(如列出目录)可能需要很长时间,这会影响 Presto 和其他 Hadoop 应用程序的查询响应时间。
要解决高峰期名称节点RPC延迟高的问题,可以部署多层架构。比如你有一个高利用率的大型 Hadoop 集群(数千个节点),周围有较小的计算集群(大约 1000 个节点),那么你可以在 Alluxio 上层运行 Presto 和其他不同的框架。 Alluxio 将作为大型 HDFS 集群的缓存层,用来消除数据和元数据的服务压力。
要了解更多详细信息,可查看京东(JD.com)的Strata 演示文稿,文稿中介绍了京东如何使用 Alluxio 作为计算框架的容错、可插拔优化组件。
什么是APACHE HADOOP?
如果你不熟悉大数据应用程序的搭建,这里简单介绍下Apache Hadoop,它是用于管理在集群系统中运行的大数据应用的数据处理和存储的分布式框架。它由 5 个模块组成——分布式文件系统(又名 HDFS 或 Hadoop 分布式文件系统)、用于并行处理数据集的 MapReduce、管理存储数据和运行分析的系统资源的 YARN、为需要随机、实时地读/写数据的应用而设计的 HBase,以及为存储在 HDFS 中的数据提供 SQL 接口 的 SQL-on-Hadoop 引擎——Hive。
将Hadoop用于大数据工作负载
随着数据量的增加,企业也面临着要降低相关的软硬件、存储和管理时间成本的压力。由于Hadoop 等解决方案能够以较小的成本存储更多数据,因此被广泛用于大数据工作负载。
为什么要为HADOOP的高负载 CPU 和 I/O卸载?
Hadoop 自身面临着一系列挑战,以下是从 Hadoop 卸载CPU 和 I/O 高负载的几个原因:
Alluxio 并非 HDFS 的替代品。相反,它是计算和分布式/云存储系统(包括HDFS) 之间增加的一个抽象层,能提供统一的文件系统命名空间。部署Alluxio后, 你可以在公有云上或其他数据中心运行单独的计算集群,帮助其他高负载 Hadoop CPU 和读取密集型的 I/O 操作卸载, 从而让Hadoop 集群中的更多资源释放出来。Alluxio还能(通过把热数据缓存在内存中)为工作负载提速,从而极大地提高正在访问这些数据的 MapReduce 作业的性能。此外,Alluxio 提供稳定的性能,使系统能够保证特定的服务质量。
如果你是 MapR 用户,Alluxio 还可以轻松地帮助 将MapR/HDFS 计算卸载到任何对象存储、云或本地,并在 Alluxio + 任何你选择的对象存储上直接运行所有现有作业。
想了解如何利用Alluxio将数据从HDFS零拷贝迁移上云,可查看此白皮书。
在进行大数据分析和 AI作业 时,你可能会从 S3 读取和写入TB级别的数据,在某些情况下甚至需要以非常高的速率进行数据传输。如果你发现 S3 会让数据密集型作业变慢,可能有几个原因。
你可以从以下几个方面查看原因:
在某些情况下,即使你有足够的并发度,也可能会受到 S3 的限制。这是因为 S3 无法跟上请求速度。你的应用在一个bucket中,每个前缀每秒可以进行至少 3500 个 PUT/COPY/POST/DELETE 和 5500 个 GET/HEAD 请求操作。
如果上述这些操作仍然不能满足你的性能要求,那么可能需要考虑像 Alluxio 这样的缓存层,它不仅能缓存数据,还能缓存 S3 元数据,从而显著加快诸如“List”和“Rename”等操作。此外,你还可以异步写入 S3,进一步提高写入密集型应用的性能。有关更多详细信息以及如何上手,请参阅文档 。
如果Hadoop作业运行缓慢,如何检测/解决故障问题?
部署的Hadoop 集群可能最初运行良好,但逐渐出现作业运行缓慢的问题。这种情况其实很普遍,是 Hadoop 集群维护和馈送的常见问题。由于集群是运行各种作业的共享资源,因此出现这种情况可能有很多原因。此处的回答旨在涵盖导致缓慢的常见原因并介绍相应的部分解决方案。
首选,要检查是否是硬件问题相当容易。由于是分布式系统,因此需要检查作业缓慢的源头,是名称节点,数据节点,还是网络接口卡的问题?你可以通过运行线程转储,来查看作业缓慢的原因。此外,还可以检查内存和磁盘利用率。最后还可以查看是否是垃圾回收(GC) 暂停造成的作业缓慢。
那么,问题是否出在集群容量不足?
随着企业逐步向数据驱动转型,数据作业的数量和规模正在迅速加大。企业有更多的数据分析师和数据科学家,通常意味着需要进行更多的数据作业。添加一个类似Presto 或 TensorFlow的新应用框架会增加大量的作业。某些计算作业的增加可以提前计划,集群的大小也可以提前配置。但很多时候,数据分析师和数据科学家无法很好地预测工作负载,也并不知道这样的工作负载会转化为多少计算作业。通常集群会呈现如下图所示的月度运行规律:
来源:AWS EMR迁移指南
如上图所示,根据同时运行的作业数量,集群可能会被过度使用:
简单的判定方法是查看有关CPU 负载的指标。如果负载达到 90% 或以上,则运行的作业量可能已经超过集群的处理容量。这意味着你的集群受限于计算,作业运行速度变慢是因为需要长时间在作业队列中等待,或者因为集群本身已经饱和,从而导致作业运行缓慢。
Options when you’re out of capacity:
容量不足时的选项:
4a) Lift and Shift 将全部或部分 HDFS 集群直接迁移(Lift and Shift)到云上。你可以根据作业情况,使用公有云实例创建一个新的 HDFS 集群,一般会使用像 S3 这样的对象存储作为底层存储。在创建新的计算和存储孤岛前需要知道获取哪些数据。这也需要对数据副本进行一些规划和同步,也会导致额外的云成本和 HDFS成本。
4b) 将特定工作负载的数据子集复制到云对象存储中并在云上运行分析作业。这需要对数据副本进行一些规划和同步。
4c) 将计算驱动型应用所需的数据缓存到云上,而数据本身存储在本地。在这种情况下,所需的数据由计算框架本身决定,因此无需对任何数据进行复制和同步。这是一种可增强本地计算能力的理想的即时、可扩展方案,也是 Alluxio 的常见用途之一。欢迎立即免费试用:查看 Alluxio 零拷贝迁移方案。
此外,如果你是 MapR 用户,Alluxio 还可以轻松地帮助 将MapR/HDFS 计算卸载到任何对象存储、云或本地,并在 Alluxio + 任何你选择的对象存储上直接运行所有现有作业。
TensorFlow 是一个用于构建诸如深度神经网络等应用的开源机器学习平台,包含用于机器学习、人工智能和数据科学应用的工具、库和社区资源等组成的生态系统。 S3 是一款由亚马逊最早创建的对象存储服务。它具有一套丰富的 API,可将底层对象数据存储抽象化,允许从网络上的任何位置访问数据。
使用 TensorFlow 训练神经网络是一个复杂的过程。训练需要获取大量样本,来迭代性地调整权重,并最小化代表网络误差的损失函数。例如,要使用神经网络进行模式识别,需要对数据信号输入进行加权、求和并馈入决策激活函数(这里指 sigmoid 函数),从而产生决策输出。
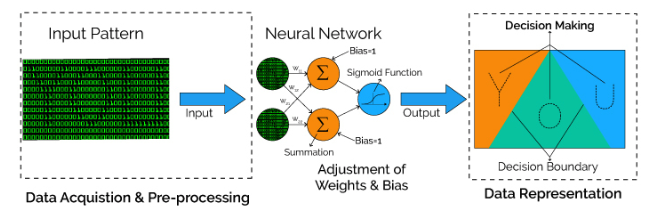
这个过程通常涉及高 I/O以及 CPU、GPU 和 TPU 上的计算密集型矩阵运算,而数据必须从底层存储中读取,并且像 S3 这样的存储通常与 TensorFlow 一起使用。
那么,将 TensorFlow 与 S3 结合使用存在哪些挑战,如何克服这些挑战呢?
在分布式深度学习应用中,训练库的性能取决于底层存储子系统和检查点( checkpointing) 过程的性能。
对于分布式训练应用而言,其常规设置如下:
在训练开始时,需要快速读取海量小文件,并在 CPU 上进行预处理,然后将其用于多级训练。在训练期间,库会定期执行检查点(通过写入来捕获中间状态)机制,以便 TensorFlow 可以在需要时快速回溯,并从较早的检查点重新启动。
为了共享和保存 TensorFlow 生成的某些类型的状态,TensorFlow 框架假定有一个可靠的共享文件系统。尽管 S3 可能看似是理想的文件系统,但实际上,它并非典型的 POSIX 文件系统,而且与文件系统有着明显的区别。
以下是 TensorFlow 与 S3 一起使用时的部分常见挑战:
在典型文件系统中所做的修改通常是立即可见的,但对于 S3 这样的对象存储,修改是最终一致的。 TensorFlow 计算的输出可能不会立即可见。
通过Alluxio POSIX API, 数据工程师能够像访问本地文件系统一样,来访问任何分布式文件系统或云存储,并且能实现更好的性能。这避免了使用具有覆盖层的连接器带来的性能损失。 Alluxio 可以预加载或按需缓存数据集,把数据带到计算集群的本地位置,以此来提高数据访问的性能。我们可以通过部署类似Alluxio的数据编排层,来将数据提供给 TensorFlow,从而提高端到端的模型开发效率。例如,Alluxio 可以与训练集群部署在一起,挂载远程存储(如 S3), 通过 Alluxio POSIX 或兼容HDFS 的接口来提供训练数据。数据可以从远程存储预加载到Alluxio,也可以按需缓存。如需更多信息,请参阅文档。
目前,S3几乎已成为数字业务应用程序存储非结构化数据块的标准API。正因如此,一些厂商提供了与S3 API兼容的选项,允许应用开发者在本地通过S3 API 进行标准化开发,开发完成后将这些应用移植到其他平台上运行。
S3是一款由亚马逊最先创建的对象存储服务,对可扩展性、数据可用性、性能和安全性都有着很好的支持。它具有一套丰富的API,可将底层数据存储抽象化,允许从网络上的任何位置访问数据。在S3中,基本的存储单元被称为对象(object),按照bucket进行组织划分。每个对象都通过对应的键(key)来标识,并有相关的元数据。
S3本身没有特殊之处,但当它的上层有工作负载运行时,情况则不同。此时就会使用类似Spark这种可用于大规模数据处理的快速、通用集群计算框架。我们可以将Spark看成一个高性能的批处理和流处理引擎。它具有强大的库( library),可以在借助SPARK SQL的情况下轻松使用SQL语言。它支持不同编程语言的查询,并以数据集和数据框的形式返回数据。Spark由Apache 基金会维护,使用的是Apache 2.0许可证。
具有兼容S3 API(如 Cloudian、Minio 和 SwiftStack)的对象存储可能看起来像文件系统。事实上,它们与典型的 POSIX 文件系统区别很大。在典型的文件系统中所做的修改通常是立即可见的,但就对象存储而言,修改是具有最终一致性的。为了存储 PB 级的数据,对象存储采用更简单的键值模型,而非典型文件系统的目录树结构。在对象存储上搭建类似目录的结构会减慢它的速度。此外,重命名等文件操作也非常昂贵,因为重命名需要多次进行耗时的HTTP REST 调用(复制到目标文件夹,并删除源数据)才能完成。
Spark 没有原生的 S3 实现,只能依赖 Hadoop 类来将数据访问抽象化。 Hadoop 为 S3 提供了 3 个文件系统客户端(s3n、s3a 和数据块 s3)。要让 Spark 通过这些连接器访问s3, 需要进行大量调优工作才能更好地确保Spark 作业的高性能。例如,需要分析和控制Spark 在开始实际作业之前(在格式转换上)和作业完成之后(在写回结果上)所花费的时间。
ALLUXIO 带来的益处
理想情况下,将 S3 中的数据读入 Spark 并启用数据共享的过程应该是自动和透明的。我们可以通过部署像 Alluxio 这样的数据编排层,来把数据提供给 Spark,从而提高端到端的模型开发效率。例如,Alluxio 可以与 Spark 集群部署在一起,挂载远端存储(如 S3),通过 Alluxio POSIX 或兼容HDFS 的接口来提供数据。
现在,当我们创建 Hive 表时,为提高查询性能和降低维护成本,将表按不同的值和范围划分是常规做法。但是,当该Hive表中的数据跨越不同的存储介质和集群时,Hive 无法通过单个查询直接访问单个表。当数据量太大,无法存储于单个存储介质或集群时,或者当用户需要考虑下列因素时,就会出现上述问题:
存储成本:某些分区的重要性不如其他分区,并且可以存储在成本更低的存储层上;
区域合规性:某些数据必须存储在某个区域,不能在其他区域持久化存储(链接)。
这种情况下,Alluxio就可以作为分布式虚拟文件系统,与 Hive 等应用程序交互,在不同的存储系统中创建具有多个分区的表。例如,为了在多集群环境中既保持高性能又降低存储成本,可以使用 Hive 和 Alluxio 创建按日期范围分区的表,允许最常用的数据集存放在更高的存储层 (MEM) 中,让日期更早/访问频率较低的数据存放在存储成本(如SSD、HDD)较低的的HDFS中, 甚至可以存放在远端云存储(如 S3)中。这样,数据将始终存储在作为单一数据源的底层存储系统中,但同时也可临时存放在 Alluxio 文件系统中。
本文旨在指导终端用户利用 Alluxio 在 Hive 中创建基于不同文件存储位置的外部表,但每个位置只包含按指定值分区的完整数据的子集。
示例
设置ALLUXIO
首先,在 EC2 实例的4 个节点(1 个 Master,3 个 Worker)上部署 Alluxio 集群。请参考 本文档安装Alluxio集群或使用我们的沙盒免费在AWS EC2上一键部署Alluxio。
Alluxio 有 2 个挂载点——HDP 作为根挂载点,S3 bucket 作为嵌套挂载点
HDP 也部署在 4 个节点上。在本示例中,它位于Alluxio 节点上,但也可以作为单独的集群部署。
| [centos@ip-172-31-8-93 alluxio]$ ./bin/alluxio fs ls / |
| drwxr-xr-x centos centos 1 PERSISTED 02-20-2019 00:31:53:234 DIR /hdfs |
| drwxr-xr-x centos centos 1 NOT_PERSISTED 02-19-2019 22:21:46:005 DIR /local |
| drwxrwxrwx madan madan 1 PERSISTED 02-19-2019 22:14:29:532 DIR /s3 |
创建Hive表
运行以下 Hive DDL 语句来创建外部 Hive 表 call_center_s3:
| create external table call_center_s3( |
| cc_call_center_sk bigint |
| , cc_call_center_id string |
| , cc_rec_end_date string |
| , cc_closed_date_sk bigint |
| , cc_open_date_sk bigint |
| , cc_name string |
| , cc_class string |
| , cc_employees int |
| , cc_sq_ft int |
| , cc_hours string |
| , cc_manager string |
| , cc_mkt_id int |
| , cc_mkt_class string |
| , cc_mkt_desc string |
| , cc_market_manager string |
| , cc_division int |
| , cc_division_name string |
| , cc_company int |
| , cc_company_name string |
| , cc_street_number string |
| , cc_street_name string |
| , cc_street_type string |
| , cc_suite_number string |
| , cc_city string |
| , cc_county string |
| , cc_state string |
| , cc_zip string |
| , cc_country string |
| , cc_gmt_offset double |
| , cc_tax_percentage double |
| ) |
| partitioned by (cc_rec_start_date string) |
| row format delimited fields terminated by ‘|’ |
| location ‘alluxio://172.31.9.93:19998/s3/’; |
我们首先在 S3 bucket上 创建原始的 call_center 表,请注意,在创建该外部表时,我们使用 cc_rec_start_date 对表进行分区。然后,我们通过日期来修改表,位置也会相应地修改。我们通过3 个值来修改表,如下所示:
| ALTER TABLE call_center_s3 |
| ADD PARTITION (cc_rec_start_date=‘1998-01-01’) |
| location ‘alluxio://172.31.9.93:19998/s3/’; |
我们已经对表进行了修改并添加了 “1998 年”的分区,由于表中包含的是(本身存储在远端的)冷数据,我们允许该表存放在 Alluxio S3 文件的位置。
| ALTER TABLE call_center_s3 |
| ADD PARTITION (cc_rec_start_date=‘2001-01-01’) |
| location ‘alluxio://172.31.9.93:19998/s3/’; |
我们对表在2001 年日期范围内的数据进行了修改,由于该表的访问频率较低,我们也允许其继续存放在远端的 S3 存储中,而日期较近的数据将被存储在HDFS 集群的磁盘 (SSD) 中。
| ALTER TABLE call_center_s3 |
| ADD PARTITION (cc_rec_start_date=‘2002-01-01’) |
| location ‘alluxio://172.31.9.93:19998/hdfs/’; |
最后,针对最新的数据,我们可以添加一个分区并将其存放在位于SSD 上 的Alluxio HDFS 文件夹中。该文件夹中的数据位于 Alluxio 的不同节点上。
| [centos@ip-172-31-8-218 alluxio]$ ./bin/alluxio fs ls /hdfs |
| drwxr-xr-x centos centos 9356 PERSISTED 04-19-2019 18:30:59:822 0% /hdfs/data-m-0099 |
| [centos@ip-172-31-8-218 alluxio]$ ./bin/alluxio fs ls /s3 |
| drwxr-xr-x centos centos 9356 PERSISTED 04-19-2019 19:04:45:107 0% /s3/data-m-00099 |
在上面的截图中,我们看到对于 HDFS 和 S3 挂载点,数据只持久化存储( PERSISTED)在底层文件系统中,并没有缓存到 Alluxio 内存中。此外,这里的文件百分比为 0%,表明该文件尚未存储到 Alluxio MEM 中。
现在,当我们查询 Hive 表之后,我们可以再次查看数据是否已在 Alluxio MEM 中(cache_promote 设置为默认读取类型)以及文件是否显示 100%,以此确认数据是否已经位于相应的底层存储文件夹中。另外需注意,S3 分区中的数据不会被拉取到 Alluxio中,因为根据 Hive 运行时的谓词该分区已消除。
| hive> select * from call_center_s3 where cc_rec_start_date=‘2002-01-01’; |
注意,这是存放在 HDFS 中的表的日期范围。
| [centos@ip-172-31-8-218 alluxio]$ ./bin/alluxio fs ls /hdfs |
| drwxr-xr-x centos centos 9356 PERSISTED 04-19-2019 18:30:59:822 100% /hdfs/data-m-0099 |
| [centos@ip-172-31-8-218 alluxio]$ ./bin/alluxio fs ls /s3 |
| drwxr-xr-x centos centos 9356 PERSISTED 04-19-2019 19:04:45:107 0% /s3/data-m-00099 |
通过 Alluxio 命名空间验证查询引擎确实从 HDFS获取数据, 而不是从其他远程目录拉取数据,再将其持久化保存在 Alluxio MEM 中。
| hive> select * from call_center_s3 where cc_rec_start_date=‘1998-01-01’; |
同样地,对于S3, 我们把通过日期值设为1998来查询表中的数据。
| [centos@ip-172-31-8-218 alluxio]$ ./bin/alluxio fs ls /hdfs |
| drwxr-xr-x centos centos 9356 PERSISTED 04-19-2019 18:30:59:822 100% /hdfs/data-m-0099 |
| [centos@ip-172-31-8-218 alluxio]$ ./bin/alluxio fs ls /s3 |
| drwxr-xr-x centos centos 9356 PERSISTED 04-19-2019 19:04:45:107 100% /s3/data-m-00099 |
通过 Alluxio 命令行再次验证,确保数据是从 S3中获取, 并进入Alluxio 命名空间。
结论
许多用户利用分区来提高 Hive 性能并降低维护成本。本文讨论了一种同时使用 Hive 与 Alluxio 来存储单个表,但利用多个不同的存储资源来提高效率的方案。
如果在 Hive 中定义了几百个外部表,那么将这些表的关联改成指向新位置最简单的做法是什么?
如果要把 Alluxio 集成到技术栈中的话,出现上述问题属于正常现象。用户的常见设置是把Spark-SQL或Presto作为查询框架,然后与 Hive 相关联,由 Hive 提供元数据,来把这些查询引擎指向位于HDFS或对象存储中的Parquet 或 ORC 文件的正确位置。
如果要使用Alluxio,一般都需要修改URI,同时要对路径稍作修改。
S3 and HDFS
S3和HDFS
| s3://alluxio-test/ufs/tpc-ds-test-data/parquet/scale100/warehouse/ |
| hdfs://34.243.133.102:8020/tpc-ds-test-data/parquet/scale100/warehouse/ |
变成
| alluxio://alluxio-master1/scale100/warehouse/ |
那么如果涉及到上百张表的话,应该怎么做?
最近,因为要做一些内部测试,我进行了相关操作。这篇文章简要介绍了我 对Hive修改的流程。
首先,我通过查看Hive表定义来了解需要修改的内容。由于我当前的架构是基于 AWS EMR 运行的,因此我用 AWS Glue 和爬网程序(crawler)将 parquet 文件导入 Hive。但是,crawler在转换(casting)时出现错误。我的表是把 csso/dtime_sk 作为一个整数类型(int)来分区的,但是crawler在分区语句中将其转换成字符串。因此,我需要解决这个问题并把文件的位置修改成一个Alluxio URI。
hive> show create table warehouse; |
CREATE TABLE `catalog_sales`( |
`cs_sold_time_sk` int, |
`cs_ship_date_sk` int, |
`cs_bill_customer_sk` int, |
`cs_bill_cdemo_sk` int, |
`cs_bill_hdemo_sk` int, |
......... |
PARTITIONED BY ( |
`cs_sold_date_sk` string) |
ROW FORMAT SERDE |
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe' |
STORED AS INPUTFORMAT |
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat' |
OUTPUTFORMAT |
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat' |
LOCATION |
'hdfs://34.243.133.102:8020/tpcds/catalog_sales' |
TBLPROPERTIES ( |
'CrawlerSchemaDeserializerVersion'='1.0', |
'CrawlerSchemaSerializerVersion'='1.0', |
'UPDATED_BY_CRAWLER'='nstest1', |
'averageRecordSize'='115', |
'classification'='parquet', |
'compressionType'='none', |
'last_modified_by'='hadoop', |
'last_modified_time'='1558657957', |
'objectCount'='1838', |
'recordCount'='144052377', |
'sizeKey'='12691728701', |
'typeOfData'='file') |
第一步是转储(dump)所有的表定义。我使用下面的脚本来简化流程。该脚本的输出是包含表创建语句的各个表的 ddl 文件。
#!/bin/sh |
if [ $# -ne 1 ] |
then |
echo "Usage: $0 <databasename>" |
exit 1 |
fi |
DB_NAME="${1}" |
HIVE="hive -S" |
tables="`${HIVE} --database ${DB_NAME} -e 'show tables;'`" |
for table in ${tables} |
do |
${HIVE} --database ${DB_NAME} -e "show create table $table;" > ${table}.ddl |
done |
之后,我看看在Hive中需要解决的问题:
接着,我写了一个简短的脚本来完成以上任务。这里,我通过创建一个新的数据库关联,来直接使用原始定义的数据集或通过Alluxio来使用。
#!/bin/sh |
if [ $# -ne 4 ] |
then |
echo "Usage: $0 <databasename> <newdatabasename> <s3filepath> <alluxioufspath>" |
echo "example: $0 nstest nstest1 s3://alluxio-test/ufs/tpc-ds-test-data/parquet/scale100 alluxio:///" |
exit 1 |
fi |
DB_NAME="${1}" |
NEW_DB_NAME="${2}" |
S3_FILE_PATH="${3}" |
ALLUXIO_UFS_PATH="${4}" |
HIVE="hive -S" |
tables="`ls *.ddl`" |
# Create new database |
hive -e "create database ${NEW_DB_NAME}" |
for table in ${tables} |
do |
echo "Working on $table" |
TABLE_NAME="`basename $table .ddl`" |
# Fix Parition key |
sed -i ' |
:1 |
/PARTITIONED/ { |
n |
s/string/int/ |
b1 |
}' ${table} |
# Change file path |
sed -i s^${S3_FILE_PATH}^${ALLUXIO_UFS_PATH}^ ${table} |
# Create table defintion in new database |
hive --database ${NEW_DB_NAME} -f ${table} |
# Repair partitions for Hive |
hive --database ${NEW_DB_NAME} -e "MSCK REPAIR TABLE ${TABLE_NAME}" |
done |
如果你当前使用的Hive 设置比较标准,只需要修改当前数据库实例中的表位置,那么你可以使用 ALTER TABLE 语句来简化流程。
#!/bin/sh |
if [ $# -ne 3 ] |
then |
echo "Usage: $0 <databasename> <s3filepath> <alluxioufspath>" |
echo "example: $0 db1 s3://alluxio-test/ufs/tpc-ds-test-data/parquet/scale100 alluxio:///" |
exit 1 |
fi |
DB_NAME="${1}" |
S3_FILE_PATH="${3}" |
ALLUXIO_UFS_PATH="${4}" |
HIVE="hive -S" |
tables="`ls *.ddl`" |
for table in ${tables} |
do |
echo "Working on $table" |
TABLE_NAME="`basename $table .ddl`" |
|
# Change file path |
TABLE_LOCATION="`sed -i s^${S3_FILE_PATH}^${ALLUXIO_UFS_PATH}^ ${table} | grep alluxio`" |
echo "ALTER TABLE ${TABLE_NAME} SET LOCATION \"${TABLE_LOCATION}\";" >> ${FILE} |
echo "MSCK REPAIR TABLE ${TABLE_NAME};" >> ${FILE} |
done |
hive --database ${DB_NAME} -f ${FILE} |
单节点缓存对于某些用户来说可能已经够用,但它并不能显著提高性能。理论上,单节点缓存的数据仅限于该单个节点已经访问的数据。此外,大多数具有单节点缓存的框架通常不会使用节点上的SSD或HDD。
Alluxio的不同之处在于它是唯一能够同时提供以下三大功能的数据编排层:分布式缓存(将数据本地化)、兼容主流大数据框架的API以及全局命名空间(实现统一数据孤岛)。Alluxio能够获取可用的集群资源并将其作为分布式分级缓存层供这些框架访问。我们可以通过配置Alluxio来拷贝热数据并智能地将数据分级存储到 RAM、SSD、HDD 甚至像 S3 这样的远端存储中。多级分层增加了能够本地化到worker节点上的数据量,缩短了作业完成时间,并能够实现与 AWS S3 等对象存储一致的性能。
Presto 和 Spark 均受限于 CPU ,因此需要 CPU 密集型实例。同时,Presto 和 Spark 也需要使用内存,所以大多数用户在Presto/Spark工作负载上使用的是R4/R5实例。内存本身会被分配给 Presto/Spark 和 Alluxio ,通常大约 60% 用于计算,30% 用于 Alluxio,其余内存用于操作系统。
如果EBS 卷本身内置了 IOPS,会起到很大的作用。 Alluxio 可以把内存和磁盘作为存储层,自动智能地管理这些存储层之间的数据迁移。如果数据的大小超过内存的容量,且需要频繁访问,则相较于从存储系统访问数据,使用EBS卷让数据更靠近计算的操作更为合理。
Alluxio 是通过智能分级缓存提供数据本地性的数据编排系统。副本参数很容易配置,配置完成后,Alluxio 会透明地对计算框架所请求的数据进行复制。终端用户不需要进行任何更改,数据复制是透明的。数据存储在 RAM、SSD 或 HDD 中。它的位置由(可配置的) LRU策略决定。此外,数据可以被pin在热数据层中。
副本参数配置后,Alluxio 会在其他worker节点上保存数据副本。随着热数据变成冷数据,这些数据的副本也将向下层移动。当某个 worker 节点出现故障时,Alluxio master 将直接访问包含副本数据的另一个节点,并根据配置创建新的副本。复制的单位是数据块。
关于数据复制的更多内容,请参看该文档: https://docs.alluxio.io/ee/user/stable/en/Active-Replication.html
针对不同的工作负载,提到网速,用户通常会考虑网络延迟和吞吐量两个方面。在对数据请求量较高的场景(如 OLTP 工作负载)中,网络延迟是主要的影响因素;而对数据请求量较低的 OLAP 工作负载来说,延迟并非主要问题。对于吞吐量来说,带宽是重要的考虑因素,如果处理不当,吞吐量可能成为混合云数据用例的性能瓶颈。
尽管使用带宽更高的专用电路会有所帮助,但 Alluxio 数据编排可通过将数据缓存到计算节点的本地位置来解决混合云数据访问的问题:
![]()
混合云/跨数据中心分析
为什么?
Alluxio worker 是与计算框架并置部署(co-locate)的。因此,它可以极大地帮助解决吞吐量和网络延迟问题。这是因为应用程序请求访问的数据集可以通过 Alluxio缓存到计算节点的本地位置。Alluxio的优势体现在两个方面:
1)减少或避免数据的网络传输
2) 减少必须来回传输的数据量
如果Alluxio worker 上的某个磁盘发生故障,应用侧的 Alluxio 客户端将出现读取失败或超时。鉴于一个数据块可能在 Alluxio 空间中缓存了多个副本,客户端会查看其他worker 节点并从存有同一数据块副本的 worker节点读取。
如果没有其他worker节点缓存了该数据块,那么该客户端将会去底层存储读取数据。整个重试过程对应用程序和用户都是隐藏的。
想要了解更多技术细节,请参看可扩展性调优文档。
谓词下推允许将 SQL 查询的某些部分(谓词)“下推”到数据所在的位置。这种优化可以通过更早地过滤数据来减少查询处理时间。不同的计算框架在使用谓词下推后,可以在数据经网络传输、加载到内存之前过滤数据,甚至跳过整个文件或文件块的读取,以此实现查询的优化。
Alluxio 本身不做任何谓词下推。对Alluxio来说,它并不知道要访问哪个表或执行哪类查询。一般来说,Alluxio 会返回计算文件所包含的任何内容。比如,如果通过spark来访问 parquet 格式的计算文件,那么Spark 会读取 Parquet 元数据header, 来确定该文件是否与查询相关。 当然,Alluxio 也起到一些优化作用,比如,它可以将特定的(通常是被频繁读取的)元数据header数据块缓存到内存中。
什么是 WANdisco 混合数据湖?
WANdisco Fusion 方案通过AWS S3 的数据湖复制和拷贝本地 Hadoop 分布式文件系统 (HDFS) 集群中的数据。它提供连续的数据传输和同步,帮助确保数据的一致性。你可以使用 AWS EMR 或其他平台运行 Hadoop 应用,来访问S3 中拷贝的数据。 WANdisco 还提供了单一的虚拟命名空间来集成多个存储。 WANdisco 主要使用类似于托管 distCP 的方式来实现该方案。
该方案要求 WANdisco 软件同时安装在本地和云上的 EC2 实例上:
Alluxio方案有何不同?
首先,Alluxio 可与分析和 AI 工作负载进行集成。因此,使用 Alluxio 将数据零拷贝迁移至AWS 的最大不同点在于,无需在云上复制、拷贝、同步、存储或监测另一组数据。数据不会被存储在 S3、GCS 等云存储系统上,而是存放在 Alluxio 缓存层的内存中,从而简化了架构。数据可以存放在本地,但计算可以在云上弹性运行。有了 Alluxio,需大量读取的分析工作负载可以实现与数据在本地时同等的访问性能。如何实现呢?因为 Alluxio 具有跨worker节点上的 RAM、SSD 和 HDD 的智能分级缓存层,可以只缓存作业所需的数据,即热数据。
其他区别如下表所示:
| WANdisco + AWS Data Lake | Alluxio for Zero-Copy Bursting | |
| Namespace | Unified namespace for AWS S3 | Unified namespace across any storage (ex.HDFS and S3) |
| Data Storage | On-prem and S3 | On-prem only, no copies stored in cloud |
| Pay-As-You-Go (PAYG) options | Yes, via AWS Marketplace | Yes, via AWS Marketplace |
| Analytics | Bring your own | Integrated with EMR or Bring your own |
| Data Synchronization | Yes | Yes |
| Deployment model | Install on-prem and in AWS | Install in AWS only |
| Costs | Fusion SW, HW, and instance costs plus AWS EMR costs | Alluxio SW only plus AWS EMR costs |
| Open-source based | No | Yes, Alluxio is based on the Alluxio open source project |
如上图所示, Alluxio方案 和 WANdisco 的数据拷贝方案之间存在明显区别。两者在涉及数据拷贝以及运行分析的方案上都有所不同。
下图为 2019 年纽约市 O’Reilly Strata 数据会议上星展银行(DBS)演讲中提及的 Alluxio 架构示例。注意:DBS 还将Alluxio用于其数据中心,确保本地分析负载能够实现稳定的高性能。如果采用零拷贝迁移上云方案,则不需要这么做.
要了解更多信息,请参见 零拷贝迁移。
Cloudera 最近推出了企业数据云平台,通过将工作负载迁移上云来应对不可预知的场景,并增加数据中心容量,帮助企业解决本地数据容量的挑战。
The Lift and Shift approach 直接迁移方案
Cloudera 的管理控制台允许通过直接迁移( lift-and-shift )方案将工作负载迁移上云,并在云上运行现有的 Cloudera 平台。如果采用该方案,首先要在云上创建一个新的 Hadoop 集群,并在云上进行配置。你可以选择要配置的服务和框架,也可以根据现有规划进行选择。关于如何配置见下图:
接下来,选择你想在 AWS 或其他公有云上使用的实例,比如在 m4.2xlarge 的实例上运行你的集群。
但是,集群使用的数据需要来回复制。因此,你需要设置复制策略,如下所示:
你需要为从本地 Hadoop 集群复制的数据指定目标位置,以下示例演示的是 S3。设置好后,你需要等待数据被复制过来。
什么是“零拷贝”迁移?
“零拷贝”迁移方案实际上并不会复制数据,它会同步数据并且用户可以选择仅在内存中运行,因此数据不会持久化到云对象存储中。 当数据位于Alluxio内存中时,Spark、Presto 和 Hive 等框架可以在 Alluxio 上层无缝运行。
“零拷贝”迁移方案与 Cloudera 的“ lift and shift”方案相比如何?
尽管Cloudera manager提供了很好的 用户界面(UI )来帮助实现直接迁移,但也存在一些问题:
要了解更多信息,请参见 零拷贝迁移。
越来越多的分析和机器学习工作负载使用S3作为数据存储,因此很容易生成大量的get操作和数据访问请求。例如:简单的几个命令就可以启动一个包含1000 个节点的 AWS EMR 服务集群,每个节点都在运行Spark或Presto 服务。这意味着每个split / executor都可能从 S3 请求数据。
尽管S3 500 或 503 错误并不算特别常见,但偶尔还是会出现这些报错。
错误代码“500 Internal Server Error”表示 S3 目前无法为请求提供服务。这可能有几个原因:S3 服务本身存在内部错误,或者数据访问速率太高。
错误代码503(“503 Slow Down”或“503 Service Unavailable”)表示s3 bucket的数据请求量过大或者请求速度过快(需减慢请求),导致Amazon S3 无法处理请求。
解决方案
如果出现 500 错误,最好的解决方案是重试。但由于该报错无法预知,因此很难保持SLA一致或提供稳定的用户体验。
如果出现 503 错误,建议使用指数退避(Exponential backoff)。指数退避是一种成倍降低向S3发送请求的速率,从而逐步找到可接受速率的算法。
以上两种情况下,简单的重试可能不起作用,因为应用已经被阻止,处于等待状态。
另一种方案是使用像Alluxio这样的数据编排层来把S3等对象存储抽象化。类似Alluxio的编排技术可以将S3中的数据带到离计算框架更近的位置。这样做的目的是将S3中的数据挂载到(与计算框架在同一实例上运行的)Alluxio上。数据直接从充当缓存层的 Alluxio中读取,当数据已经缓存在Alluxio中时,任何 AWS 5xx 错误对读取的影响都可以被消除。点击此处免费试用。
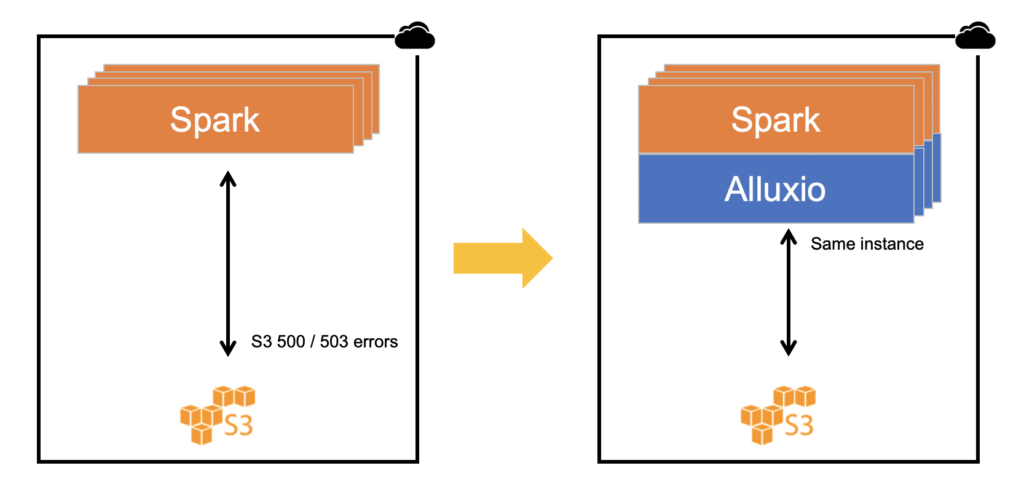
此外,使用该方案还可以避免进行write/put操作时的AWS错误。Alluxio包含一个异步写入选项。这意味着向S3的任何写入操作都是完全抽象化的。当数据写入Alluxio后,应用程序/客户端会直接返回,无需等待Alluxio将数据写入S3。为了增加耐久性,也可以在Alluxio 集群中通过自适应备份进行数据拷贝。
如需部署EMR和Alluxio, 请点击教程:https://www.alluxio.io/products/aws/aws-emr-tutorial-ami/
here: https://docs.aws.amazon.com/AmazonS3/latest/API/ErrorResponses.html#ErrorCodeList
查看S3完整错误代码列表:https://docs.aws.amazon.com/AmazonS3/latest/API/ErrorResponses.html#ErrorCodeList
Alluxio的作用是充当存储系统上层的抽象层。Alluxio的设计本身已经假定其下层有存储层,将Alluxio作为存储系统使用并不能解决存算耦合的问题。
Alluxio可作为长期运行的数据集群,缓存来自不同存储系统的数据,供计算引擎访问。所以某种程度上Alluxio的确可以存储数据,但其存储目的是方便计算引擎访问,而非作为存储系统本身。
存储系统需要考虑不同的问题——持久化、耐久性以及如何达到类似 S3的高成本效益。我们不建议只在 Alluxio 中分布式地存储数据。
当然,也可能有这样非常基本的应用场景:你需要一个临时的数据缓存区来存储无需永久化存储的数据,在这种情况下,就可以把Alluxio作为这些临时数据的存储层。
背景
目前,用于高级分析应用的数据集规模比以往任何时候都大,而数据存放的位置越来越分散。现代的存算分离架构环境更有助于应用在这些分布式数据集上运行。数据可以存储在远离计算的位置,例如不同的云环境或数据中心。该架构有时被称为混合云或多云数据分析环境。
访问远端数据带来的挑战
随着主流应用框架提供的连接器越来越丰富,查询/转换远端数据逐渐成为可能。然而,由于网络延迟和带宽限制,访问远端存储数据也带来了挑战。如果某个数据集被多次读取,网络延迟时间也会成倍增加。当数据量非常大的时候,带宽可能会成为一个制约因素。此外,由于云服务商的定价不对称,流量成本可能会非常高。
两种方案
解决远程数据访问挑战的方案之一是将数据拷贝到应用计算引擎的本地位置,但该方案的难点在于维护数据副本以及副本相关的其他成本。此外,某些企业还因为监管、合规性或数据主权要求,不允许将数据拷贝到其他位置。
鉴于上述原因,Alluxio内部有这样的说法——数据拷贝产生的问题多于它能解决的问题。 Alluxio开源项目的开发初衷就是要让数据留在原地, 并解决数据访问和数据本地性问题。Alluxio可以与分布式应用框架并置部署。比如,你有100个Spark 或 Presto worker实例,那么可以将100个Alluxio worker与这些实例并置部署。Alluxio数据编排层能够把当前运行的数据集缓存到应用的本地位置,供应用访问。
Alluxio实现数据本地性示例
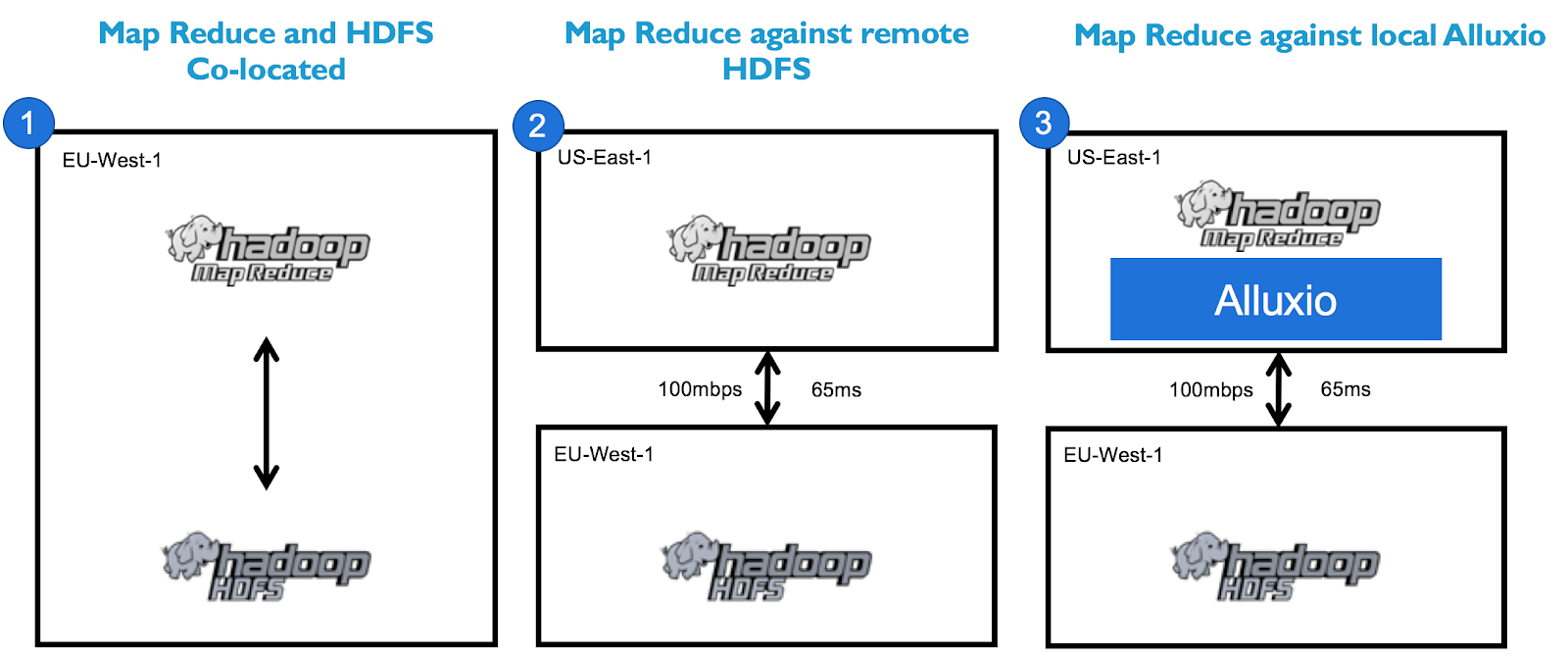
我们来看看在以下三种架构上运行的基本 Terasort 作业:
性能测试结果显示Alluxio执行查询时的性能水平十分接近本地查询:
为什么呢?因为 Alluxio 将数据集缓存到了 MapReduce worker的本地位置:
如需运行此程序的具体信息,请随时与我们联系。对于其他计算框架(Spark、Hive、Presto、TensorFlow、PyTorch)而言,以上测试结果也具有代表性。所有主流计算框架在部署Alluxio后都能从中获益。
要了解更多有关Alluxio如何解决网络延迟和带宽问题的信息,请点击此处。
TensorFlow 是一个用于构建诸如深度神经网络等应用的开源机器学习平台,包含用于机器学习、人工智能和数据科学应用的工具、库和社区资源等组成的生态系统。 S3 是一款由亚马逊最早创建的对象存储服务。它具有一套丰富的 API,可将底层对象数据存储抽象化,允许从网络上的任何位置访问数据。
使用 TensorFlow 训练神经网络是一个复杂的过程。训练需要获取大量样本,来迭代性地调整权重,并最小化代表网络误差的损失函数。例如,要使用神经网络进行模式识别,需要对数据信号输入进行加权、求和并馈入决策激活函数(这里指 sigmoid 函数),从而产生决策输出。
这个过程通常涉及高 I/O以及 CPU、GPU 和 TPU 上的计算密集型矩阵运算,而数据必须从底层存储中读取,并且像 S3 这样的存储通常与 TensorFlow 一起使用。
那么,将 TensorFlow 与 S3 结合使用存在哪些挑战,如何克服这些挑战呢?
在分布式深度学习应用中,训练库的性能取决于底层存储子系统和检查点( checkpointing) 过程的性能。
对于分布式训练应用而言,其常规设置如下:
在训练开始时,需要快速读取海量小文件,并在 CPU 上进行预处理,然后将其用于多级训练。在训练期间,库会定期执行检查点(通过写入来捕获中间状态)机制,以便 TensorFlow 可以在需要时快速回溯,并从较早的检查点重新启动。
为了共享和保存 TensorFlow 生成的某些类型的状态,TensorFlow 框架假定有一个可靠的共享文件系统。尽管 S3 可能看似是理想的文件系统,但实际上,它并非典型的 POSIX 文件系统,而且与文件系统有着明显的区别。
以下是 TensorFlow 与 S3 一起使用时的部分常见挑战:
在典型文件系统中所做的修改通常是立即可见的,但对于 S3 这样的对象存储,修改是最终一致的。 TensorFlow 计算的输出可能不会立即可见。
通过Alluxio POSIX API, 数据工程师能够像访问本地文件系统一样,来访问任何分布式文件系统或云存储,并且能实现更好的性能。这避免了使用具有覆盖层的连接器带来的性能损失。 Alluxio 可以预加载或按需缓存数据集,把数据带到计算集群的本地位置,以此来提高数据访问的性能。我们可以通过部署类似Alluxio的数据编排层,来将数据提供给 TensorFlow,从而提高端到端的模型开发效率。例如,Alluxio 可以与训练集群部署在一起,挂载远程存储(如 S3), 通过 Alluxio POSIX 或兼容HDFS 的接口来提供训练数据。数据可以从远程存储预加载到Alluxio,也可以按需缓存。如需更多信息,请参阅文档。
目前,S3几乎已成为数字业务应用程序存储非结构化数据块的标准API。正因如此,一些厂商提供了与S3 API兼容的选项,允许应用开发者在本地通过S3 API 进行标准化开发,开发完成后将这些应用移植到其他平台上运行。
S3是一款由亚马逊最先创建的对象存储服务,对可扩展性、数据可用性、性能和安全性都有着很好的支持。它具有一套丰富的API,可将底层数据存储抽象化,允许从网络上的任何位置访问数据。在S3中,基本的存储单元被称为对象(object),按照bucket进行组织划分。每个对象都通过对应的键(key)来标识,并有相关的元数据。
S3本身没有特殊之处,但当它的上层有工作负载运行时,情况则不同。此时就会使用类似Spark这种可用于大规模数据处理的快速、通用集群计算框架。我们可以将Spark看成一个高性能的批处理和流处理引擎。它具有强大的库( library),可以在借助SPARK SQL的情况下轻松使用SQL语言。它支持不同编程语言的查询,并以数据集和数据框的形式返回数据。Spark由Apache 基金会维护,使用的是Apache 2.0许可证。
具有兼容S3 API(如 Cloudian、Minio 和 SwiftStack)的对象存储可能看起来像文件系统。事实上,它们与典型的 POSIX 文件系统区别很大。在典型的文件系统中所做的修改通常是立即可见的,但就对象存储而言,修改是具有最终一致性的。为了存储 PB 级的数据,对象存储采用更简单的键值模型,而非典型文件系统的目录树结构。在对象存储上搭建类似目录的结构会减慢它的速度。此外,重命名等文件操作也非常昂贵,因为重命名需要多次进行耗时的HTTP REST 调用(复制到目标文件夹,并删除源数据)才能完成。
Spark 没有原生的 S3 实现,只能依赖 Hadoop 类来将数据访问抽象化。 Hadoop 为 S3 提供了 3 个文件系统客户端(s3n、s3a 和数据块 s3)。要让 Spark 通过这些连接器访问s3, 需要进行大量调优工作才能更好地确保Spark 作业的高性能。例如,需要分析和控制Spark 在开始实际作业之前(在格式转换上)和作业完成之后(在写回结果上)所花费的时间。
ALLUXIO 带来的益处
理想情况下,将 S3 中的数据读入 Spark 并启用数据共享的过程应该是自动和透明的。我们可以通过部署像 Alluxio 这样的数据编排层,来把数据提供给 Spark,从而提高端到端的模型开发效率。例如,Alluxio 可以与 Spark 集群部署在一起,挂载远端存储(如 S3),通过 Alluxio POSIX 或兼容HDFS 的接口来提供数据。
现在,当我们创建 Hive 表时,为提高查询性能和降低维护成本,将表按不同的值和范围划分是常规做法。但是,当该Hive表中的数据跨越不同的存储介质和集群时,Hive 无法通过单个查询直接访问单个表。当数据量太大,无法存储于单个存储介质或集群时,或者当用户需要考虑下列因素时,就会出现上述问题:
存储成本:某些分区的重要性不如其他分区,并且可以存储在成本更低的存储层上;
区域合规性:某些数据必须存储在某个区域,不能在其他区域持久化存储(链接)。
这种情况下,Alluxio就可以作为分布式虚拟文件系统,与 Hive 等应用程序交互,在不同的存储系统中创建具有多个分区的表。例如,为了在多集群环境中既保持高性能又降低存储成本,可以使用 Hive 和 Alluxio 创建按日期范围分区的表,允许最常用的数据集存放在更高的存储层 (MEM) 中,让日期更早/访问频率较低的数据存放在存储成本(如SSD、HDD)较低的的HDFS中, 甚至可以存放在远端云存储(如 S3)中。这样,数据将始终存储在作为单一数据源的底层存储系统中,但同时也可临时存放在 Alluxio 文件系统中。
本文旨在指导终端用户利用 Alluxio 在 Hive 中创建基于不同文件存储位置的外部表,但每个位置只包含按指定值分区的完整数据的子集。
示例
设置ALLUXIO
首先,在 EC2 实例的4 个节点(1 个 Master,3 个 Worker)上部署 Alluxio 集群。请参考 本文档安装Alluxio集群或使用我们的沙盒免费在AWS EC2上一键部署Alluxio。
Alluxio 有 2 个挂载点——HDP 作为根挂载点,S3 bucket 作为嵌套挂载点
HDP 也部署在 4 个节点上。在本示例中,它位于Alluxio 节点上,但也可以作为单独的集群部署。
| [centos@ip-172-31-8-93 alluxio]$ ./bin/alluxio fs ls / |
| drwxr-xr-x centos centos 1 PERSISTED 02-20-2019 00:31:53:234 DIR /hdfs |
| drwxr-xr-x centos centos 1 NOT_PERSISTED 02-19-2019 22:21:46:005 DIR /local |
| drwxrwxrwx madan madan 1 PERSISTED 02-19-2019 22:14:29:532 DIR /s3 |
创建Hive表
运行以下 Hive DDL 语句来创建外部 Hive 表 call_center_s3:
| create external table call_center_s3( |
| cc_call_center_sk bigint |
| , cc_call_center_id string |
| , cc_rec_end_date string |
| , cc_closed_date_sk bigint |
| , cc_open_date_sk bigint |
| , cc_name string |
| , cc_class string |
| , cc_employees int |
| , cc_sq_ft int |
| , cc_hours string |
| , cc_manager string |
| , cc_mkt_id int |
| , cc_mkt_class string |
| , cc_mkt_desc string |
| , cc_market_manager string |
| , cc_division int |
| , cc_division_name string |
| , cc_company int |
| , cc_company_name string |
| , cc_street_number string |
| , cc_street_name string |
| , cc_street_type string |
| , cc_suite_number string |
| , cc_city string |
| , cc_county string |
| , cc_state string |
| , cc_zip string |
| , cc_country string |
| , cc_gmt_offset double |
| , cc_tax_percentage double |
| ) |
| partitioned by (cc_rec_start_date string) |
| row format delimited fields terminated by ‘|’ |
| location ‘alluxio://172.31.9.93:19998/s3/’; |
我们首先在 S3 bucket上 创建原始的 call_center 表,请注意,在创建该外部表时,我们使用 cc_rec_start_date 对表进行分区。然后,我们通过日期来修改表,位置也会相应地修改。我们通过3 个值来修改表,如下所示:
| ALTER TABLE call_center_s3 |
| ADD PARTITION (cc_rec_start_date=‘1998-01-01’) |
| location ‘alluxio://172.31.9.93:19998/s3/’; |
我们已经对表进行了修改并添加了 “1998 年”的分区,由于表中包含的是(本身存储在远端的)冷数据,我们允许该表存放在 Alluxio S3 文件的位置。
| ALTER TABLE call_center_s3 |
| ADD PARTITION (cc_rec_start_date=‘2001-01-01’) |
| location ‘alluxio://172.31.9.93:19998/s3/’; |
我们对表在2001 年日期范围内的数据进行了修改,由于该表的访问频率较低,我们也允许其继续存放在远端的 S3 存储中,而日期较近的数据将被存储在HDFS 集群的磁盘 (SSD) 中。
| ALTER TABLE call_center_s3 |
| ADD PARTITION (cc_rec_start_date=‘2002-01-01’) |
| location ‘alluxio://172.31.9.93:19998/hdfs/’; |
最后,针对最新的数据,我们可以添加一个分区并将其存放在位于SSD 上 的Alluxio HDFS 文件夹中。该文件夹中的数据位于 Alluxio 的不同节点上。
| [centos@ip-172-31-8-218 alluxio]$ ./bin/alluxio fs ls /hdfs |
| drwxr-xr-x centos centos 9356 PERSISTED 04-19-2019 18:30:59:822 0% /hdfs/data-m-0099 |
| [centos@ip-172-31-8-218 alluxio]$ ./bin/alluxio fs ls /s3 |
| drwxr-xr-x centos centos 9356 PERSISTED 04-19-2019 19:04:45:107 0% /s3/data-m-00099 |
在上面的截图中,我们看到对于 HDFS 和 S3 挂载点,数据只持久化存储( PERSISTED)在底层文件系统中,并没有缓存到 Alluxio 内存中。此外,这里的文件百分比为 0%,表明该文件尚未存储到 Alluxio MEM 中。
现在,当我们查询 Hive 表之后,我们可以再次查看数据是否已在 Alluxio MEM 中(cache_promote 设置为默认读取类型)以及文件是否显示 100%,以此确认数据是否已经位于相应的底层存储文件夹中。另外需注意,S3 分区中的数据不会被拉取到 Alluxio中,因为根据 Hive 运行时的谓词该分区已消除。
| hive> select * from call_center_s3 where cc_rec_start_date=‘2002-01-01’; |
注意,这是存放在 HDFS 中的表的日期范围。
| [centos@ip-172-31-8-218 alluxio]$ ./bin/alluxio fs ls /hdfs |
| drwxr-xr-x centos centos 9356 PERSISTED 04-19-2019 18:30:59:822 100% /hdfs/data-m-0099 |
| [centos@ip-172-31-8-218 alluxio]$ ./bin/alluxio fs ls /s3 |
| drwxr-xr-x centos centos 9356 PERSISTED 04-19-2019 19:04:45:107 0% /s3/data-m-00099 |
通过 Alluxio 命名空间验证查询引擎确实从 HDFS获取数据, 而不是从其他远程目录拉取数据,再将其持久化保存在 Alluxio MEM 中。
| hive> select * from call_center_s3 where cc_rec_start_date=‘1998-01-01’; |
同样地,对于S3, 我们把通过日期值设为1998来查询表中的数据。
| [centos@ip-172-31-8-218 alluxio]$ ./bin/alluxio fs ls /hdfs |
| drwxr-xr-x centos centos 9356 PERSISTED 04-19-2019 18:30:59:822 100% /hdfs/data-m-0099 |
| [centos@ip-172-31-8-218 alluxio]$ ./bin/alluxio fs ls /s3 |
| drwxr-xr-x centos centos 9356 PERSISTED 04-19-2019 19:04:45:107 100% /s3/data-m-00099 |
通过 Alluxio 命令行再次验证,确保数据是从 S3中获取, 并进入Alluxio 命名空间。
结论
许多用户利用分区来提高 Hive 性能并降低维护成本。本文讨论了一种同时使用 Hive 与 Alluxio 来存储单个表,但利用多个不同的存储资源来提高效率的方案。
如果在 Hive 中定义了几百个外部表,那么将这些表的关联改成指向新位置最简单的做法是什么?
如果要把 Alluxio 集成到技术栈中的话,出现上述问题属于正常现象。用户的常见设置是把Spark-SQL或Presto作为查询框架,然后与 Hive 相关联,由 Hive 提供元数据,来把这些查询引擎指向位于HDFS或对象存储中的Parquet 或 ORC 文件的正确位置。
如果要使用Alluxio,一般都需要修改URI,同时要对路径稍作修改。
S3 and HDFS
S3和HDFS
| s3://alluxio-test/ufs/tpc-ds-test-data/parquet/scale100/warehouse/ |
| hdfs://34.243.133.102:8020/tpc-ds-test-data/parquet/scale100/warehouse/ |
变成
| alluxio://alluxio-master1/scale100/warehouse/ |
那么如果涉及到上百张表的话,应该怎么做?
最近,因为要做一些内部测试,我进行了相关操作。这篇文章简要介绍了我 对Hive修改的流程。
首先,我通过查看Hive表定义来了解需要修改的内容。由于我当前的架构是基于 AWS EMR 运行的,因此我用 AWS Glue 和爬网程序(crawler)将 parquet 文件导入 Hive。但是,crawler在转换(casting)时出现错误。我的表是把 csso/dtime_sk 作为一个整数类型(int)来分区的,但是crawler在分区语句中将其转换成字符串。因此,我需要解决这个问题并把文件的位置修改成一个Alluxio URI。
hive> show create table warehouse; |
CREATE TABLE `catalog_sales`( |
`cs_sold_time_sk` int, |
`cs_ship_date_sk` int, |
`cs_bill_customer_sk` int, |
`cs_bill_cdemo_sk` int, |
`cs_bill_hdemo_sk` int, |
......... |
PARTITIONED BY ( |
`cs_sold_date_sk` string) |
ROW FORMAT SERDE |
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe' |
STORED AS INPUTFORMAT |
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat' |
OUTPUTFORMAT |
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat' |
LOCATION |
'hdfs://34.243.133.102:8020/tpcds/catalog_sales' |
TBLPROPERTIES ( |
'CrawlerSchemaDeserializerVersion'='1.0', |
'CrawlerSchemaSerializerVersion'='1.0', |
'UPDATED_BY_CRAWLER'='nstest1', |
'averageRecordSize'='115', |
'classification'='parquet', |
'compressionType'='none', |
'last_modified_by'='hadoop', |
'last_modified_time'='1558657957', |
'objectCount'='1838', |
'recordCount'='144052377', |
'sizeKey'='12691728701', |
'typeOfData'='file') |
第一步是转储(dump)所有的表定义。我使用下面的脚本来简化流程。该脚本的输出是包含表创建语句的各个表的 ddl 文件。
#!/bin/sh |
if [ $# -ne 1 ] |
then |
echo "Usage: $0 <databasename>" |
exit 1 |
fi |
DB_NAME="${1}" |
HIVE="hive -S" |
tables="`${HIVE} --database ${DB_NAME} -e 'show tables;'`" |
for table in ${tables} |
do |
${HIVE} --database ${DB_NAME} -e "show create table $table;" > ${table}.ddl |
done |
之后,我看看在Hive中需要解决的问题:
接着,我写了一个简短的脚本来完成以上任务。这里,我通过创建一个新的数据库关联,来直接使用原始定义的数据集或通过Alluxio来使用。
#!/bin/sh |
if [ $# -ne 4 ] |
then |
echo "Usage: $0 <databasename> <newdatabasename> <s3filepath> <alluxioufspath>" |
echo "example: $0 nstest nstest1 s3://alluxio-test/ufs/tpc-ds-test-data/parquet/scale100 alluxio:///" |
exit 1 |
fi |
DB_NAME="${1}" |
NEW_DB_NAME="${2}" |
S3_FILE_PATH="${3}" |
ALLUXIO_UFS_PATH="${4}" |
HIVE="hive -S" |
tables="`ls *.ddl`" |
# Create new database |
hive -e "create database ${NEW_DB_NAME}" |
for table in ${tables} |
do |
echo "Working on $table" |
TABLE_NAME="`basename $table .ddl`" |
# Fix Parition key |
sed -i ' |
:1 |
/PARTITIONED/ { |
n |
s/string/int/ |
b1 |
}' ${table} |
# Change file path |
sed -i s^${S3_FILE_PATH}^${ALLUXIO_UFS_PATH}^ ${table} |
# Create table defintion in new database |
hive --database ${NEW_DB_NAME} -f ${table} |
# Repair partitions for Hive |
hive --database ${NEW_DB_NAME} -e "MSCK REPAIR TABLE ${TABLE_NAME}" |
done |
如果你当前使用的Hive 设置比较标准,只需要修改当前数据库实例中的表位置,那么你可以使用 ALTER TABLE 语句来简化流程。
#!/bin/sh |
if [ $# -ne 3 ] |
then |
echo "Usage: $0 <databasename> <s3filepath> <alluxioufspath>" |
echo "example: $0 db1 s3://alluxio-test/ufs/tpc-ds-test-data/parquet/scale100 alluxio:///" |
exit 1 |
fi |
DB_NAME="${1}" |
S3_FILE_PATH="${3}" |
ALLUXIO_UFS_PATH="${4}" |
HIVE="hive -S" |
tables="`ls *.ddl`" |
for table in ${tables} |
do |
echo "Working on $table" |
TABLE_NAME="`basename $table .ddl`" |
|
# Change file path |
TABLE_LOCATION="`sed -i s^${S3_FILE_PATH}^${ALLUXIO_UFS_PATH}^ ${table} | grep alluxio`" |
echo "ALTER TABLE ${TABLE_NAME} SET LOCATION \"${TABLE_LOCATION}\";" >> ${FILE} |
echo "MSCK REPAIR TABLE ${TABLE_NAME};" >> ${FILE} |
done |
hive --database ${DB_NAME} -f ${FILE} |
单节点缓存对于某些用户来说可能已经够用,但它并不能显著提高性能。理论上,单节点缓存的数据仅限于该单个节点已经访问的数据。此外,大多数具有单节点缓存的框架通常不会使用节点上的SSD或HDD。
Alluxio的不同之处在于它是唯一能够同时提供以下三大功能的数据编排层:分布式缓存(将数据本地化)、兼容主流大数据框架的API以及全局命名空间(实现统一数据孤岛)。Alluxio能够获取可用的集群资源并将其作为分布式分级缓存层供这些框架访问。我们可以通过配置Alluxio来拷贝热数据并智能地将数据分级存储到 RAM、SSD、HDD 甚至像 S3 这样的远端存储中。多级分层增加了能够本地化到worker节点上的数据量,缩短了作业完成时间,并能够实现与 AWS S3 等对象存储一致的性能。
Presto 和 Spark 均受限于 CPU ,因此需要 CPU 密集型实例。同时,Presto 和 Spark 也需要使用内存,所以大多数用户在Presto/Spark工作负载上使用的是R4/R5实例。内存本身会被分配给 Presto/Spark 和 Alluxio ,通常大约 60% 用于计算,30% 用于 Alluxio,其余内存用于操作系统。
如果EBS 卷本身内置了 IOPS,会起到很大的作用。 Alluxio 可以把内存和磁盘作为存储层,自动智能地管理这些存储层之间的数据迁移。如果数据的大小超过内存的容量,且需要频繁访问,则相较于从存储系统访问数据,使用EBS卷让数据更靠近计算的操作更为合理。
Alluxio 是通过智能分级缓存提供数据本地性的数据编排系统。副本参数很容易配置,配置完成后,Alluxio 会透明地对计算框架所请求的数据进行复制。终端用户不需要进行任何更改,数据复制是透明的。数据存储在 RAM、SSD 或 HDD 中。它的位置由(可配置的) LRU策略决定。此外,数据可以被pin在热数据层中。
副本参数配置后,Alluxio 会在其他worker节点上保存数据副本。随着热数据变成冷数据,这些数据的副本也将向下层移动。当某个 worker 节点出现故障时,Alluxio master 将直接访问包含副本数据的另一个节点,并根据配置创建新的副本。复制的单位是数据块。
关于数据复制的更多内容,请参看该文档: https://docs.alluxio.io/ee/user/stable/en/Active-Replication.html
针对不同的工作负载,提到网速,用户通常会考虑网络延迟和吞吐量两个方面。在对数据请求量较高的场景(如 OLTP 工作负载)中,网络延迟是主要的影响因素;而对数据请求量较低的 OLAP 工作负载来说,延迟并非主要问题。对于吞吐量来说,带宽是重要的考虑因素,如果处理不当,吞吐量可能成为混合云数据用例的性能瓶颈。
尽管使用带宽更高的专用电路会有所帮助,但 Alluxio 数据编排可通过将数据缓存到计算节点的本地位置来解决混合云数据访问的问题:
![]()
混合云/跨数据中心分析
为什么?
Alluxio worker 是与计算框架并置部署(co-locate)的。因此,它可以极大地帮助解决吞吐量和网络延迟问题。这是因为应用程序请求访问的数据集可以通过 Alluxio缓存到计算节点的本地位置。Alluxio的优势体现在两个方面:
1)减少或避免数据的网络传输
2) 减少必须来回传输的数据量
如果Alluxio worker 上的某个磁盘发生故障,应用侧的 Alluxio 客户端将出现读取失败或超时。鉴于一个数据块可能在 Alluxio 空间中缓存了多个副本,客户端会查看其他worker 节点并从存有同一数据块副本的 worker节点读取。
如果没有其他worker节点缓存了该数据块,那么该客户端将会去底层存储读取数据。整个重试过程对应用程序和用户都是隐藏的。
想要了解更多技术细节,请参看可扩展性调优文档。
谓词下推允许将 SQL 查询的某些部分(谓词)“下推”到数据所在的位置。这种优化可以通过更早地过滤数据来减少查询处理时间。不同的计算框架在使用谓词下推后,可以在数据经网络传输、加载到内存之前过滤数据,甚至跳过整个文件或文件块的读取,以此实现查询的优化。
Alluxio 本身不做任何谓词下推。对Alluxio来说,它并不知道要访问哪个表或执行哪类查询。一般来说,Alluxio 会返回计算文件所包含的任何内容。比如,如果通过spark来访问 parquet 格式的计算文件,那么Spark 会读取 Parquet 元数据header, 来确定该文件是否与查询相关。 当然,Alluxio 也起到一些优化作用,比如,它可以将特定的(通常是被频繁读取的)元数据header数据块缓存到内存中。
什么是 WANdisco 混合数据湖?
WANdisco Fusion 方案通过AWS S3 的数据湖复制和拷贝本地 Hadoop 分布式文件系统 (HDFS) 集群中的数据。它提供连续的数据传输和同步,帮助确保数据的一致性。你可以使用 AWS EMR 或其他平台运行 Hadoop 应用,来访问S3 中拷贝的数据。 WANdisco 还提供了单一的虚拟命名空间来集成多个存储。 WANdisco 主要使用类似于托管 distCP 的方式来实现该方案。
该方案要求 WANdisco 软件同时安装在本地和云上的 EC2 实例上:
Alluxio方案有何不同?
首先,Alluxio 可与分析和 AI 工作负载进行集成。因此,使用 Alluxio 将数据零拷贝迁移至AWS 的最大不同点在于,无需在云上复制、拷贝、同步、存储或监测另一组数据。数据不会被存储在 S3、GCS 等云存储系统上,而是存放在 Alluxio 缓存层的内存中,从而简化了架构。数据可以存放在本地,但计算可以在云上弹性运行。有了 Alluxio,需大量读取的分析工作负载可以实现与数据在本地时同等的访问性能。如何实现呢?因为 Alluxio 具有跨worker节点上的 RAM、SSD 和 HDD 的智能分级缓存层,可以只缓存作业所需的数据,即热数据。
其他区别如下表所示:
| WANdisco + AWS Data Lake | Alluxio for Zero-Copy Bursting | |
| Namespace | Unified namespace for AWS S3 | Unified namespace across any storage (ex.HDFS and S3) |
| Data Storage | On-prem and S3 | On-prem only, no copies stored in cloud |
| Pay-As-You-Go (PAYG) options | Yes, via AWS Marketplace | Yes, via AWS Marketplace |
| Analytics | Bring your own | Integrated with EMR or Bring your own |
| Data Synchronization | Yes | Yes |
| Deployment model | Install on-prem and in AWS | Install in AWS only |
| Costs | Fusion SW, HW, and instance costs plus AWS EMR costs | Alluxio SW only plus AWS EMR costs |
| Open-source based | No | Yes, Alluxio is based on the Alluxio open source project |
如上图所示, Alluxio方案 和 WANdisco 的数据拷贝方案之间存在明显区别。两者在涉及数据拷贝以及运行分析的方案上都有所不同。
下图为 2019 年纽约市 O’Reilly Strata 数据会议上星展银行(DBS)演讲中提及的 Alluxio 架构示例。注意:DBS 还将Alluxio用于其数据中心,确保本地分析负载能够实现稳定的高性能。如果采用零拷贝迁移上云方案,则不需要这么做.
要了解更多信息,请参见 零拷贝迁移。
Cloudera 最近推出了企业数据云平台,通过将工作负载迁移上云来应对不可预知的场景,并增加数据中心容量,帮助企业解决本地数据容量的挑战。
The Lift and Shift approach 直接迁移方案
Cloudera 的管理控制台允许通过直接迁移( lift-and-shift )方案将工作负载迁移上云,并在云上运行现有的 Cloudera 平台。如果采用该方案,首先要在云上创建一个新的 Hadoop 集群,并在云上进行配置。你可以选择要配置的服务和框架,也可以根据现有规划进行选择。关于如何配置见下图:
接下来,选择你想在 AWS 或其他公有云上使用的实例,比如在 m4.2xlarge 的实例上运行你的集群。
但是,集群使用的数据需要来回复制。因此,你需要设置复制策略,如下所示:
你需要为从本地 Hadoop 集群复制的数据指定目标位置,以下示例演示的是 S3。设置好后,你需要等待数据被复制过来。
什么是“零拷贝”迁移?
“零拷贝”迁移方案实际上并不会复制数据,它会同步数据并且用户可以选择仅在内存中运行,因此数据不会持久化到云对象存储中。 当数据位于Alluxio内存中时,Spark、Presto 和 Hive 等框架可以在 Alluxio 上层无缝运行。
“零拷贝”迁移方案与 Cloudera 的“ lift and shift”方案相比如何?
尽管Cloudera manager提供了很好的 用户界面(UI )来帮助实现直接迁移,但也存在一些问题:
要了解更多信息,请参见 零拷贝迁移。
越来越多的分析和机器学习工作负载使用S3作为数据存储,因此很容易生成大量的get操作和数据访问请求。例如:简单的几个命令就可以启动一个包含1000 个节点的 AWS EMR 服务集群,每个节点都在运行Spark或Presto 服务。这意味着每个split / executor都可能从 S3 请求数据。
尽管S3 500 或 503 错误并不算特别常见,但偶尔还是会出现这些报错。
错误代码“500 Internal Server Error”表示 S3 目前无法为请求提供服务。这可能有几个原因:S3 服务本身存在内部错误,或者数据访问速率太高。
错误代码503(“503 Slow Down”或“503 Service Unavailable”)表示s3 bucket的数据请求量过大或者请求速度过快(需减慢请求),导致Amazon S3 无法处理请求。
解决方案
如果出现 500 错误,最好的解决方案是重试。但由于该报错无法预知,因此很难保持SLA一致或提供稳定的用户体验。
如果出现 503 错误,建议使用指数退避(Exponential backoff)。指数退避是一种成倍降低向S3发送请求的速率,从而逐步找到可接受速率的算法。
以上两种情况下,简单的重试可能不起作用,因为应用已经被阻止,处于等待状态。
另一种方案是使用像Alluxio这样的数据编排层来把S3等对象存储抽象化。类似Alluxio的编排技术可以将S3中的数据带到离计算框架更近的位置。这样做的目的是将S3中的数据挂载到(与计算框架在同一实例上运行的)Alluxio上。数据直接从充当缓存层的 Alluxio中读取,当数据已经缓存在Alluxio中时,任何 AWS 5xx 错误对读取的影响都可以被消除。点击此处免费试用。
此外,使用该方案还可以避免进行write/put操作时的AWS错误。Alluxio包含一个异步写入选项。这意味着向S3的任何写入操作都是完全抽象化的。当数据写入Alluxio后,应用程序/客户端会直接返回,无需等待Alluxio将数据写入S3。为了增加耐久性,也可以在Alluxio 集群中通过自适应备份进行数据拷贝。
如需部署EMR和Alluxio, 请点击教程:https://www.alluxio.io/products/aws/aws-emr-tutorial-ami/
here: https://docs.aws.amazon.com/AmazonS3/latest/API/ErrorResponses.html#ErrorCodeList
查看S3完整错误代码列表:https://docs.aws.amazon.com/AmazonS3/latest/API/ErrorResponses.html#ErrorCodeList
Alluxio的作用是充当存储系统上层的抽象层。Alluxio的设计本身已经假定其下层有存储层,将Alluxio作为存储系统使用并不能解决存算耦合的问题。
Alluxio可作为长期运行的数据集群,缓存来自不同存储系统的数据,供计算引擎访问。所以某种程度上Alluxio的确可以存储数据,但其存储目的是方便计算引擎访问,而非作为存储系统本身。
存储系统需要考虑不同的问题——持久化、耐久性以及如何达到类似 S3的高成本效益。我们不建议只在 Alluxio 中分布式地存储数据。
当然,也可能有这样非常基本的应用场景:你需要一个临时的数据缓存区来存储无需永久化存储的数据,在这种情况下,就可以把Alluxio作为这些临时数据的存储层。
背景
目前,用于高级分析应用的数据集规模比以往任何时候都大,而数据存放的位置越来越分散。现代的存算分离架构环境更有助于应用在这些分布式数据集上运行。数据可以存储在远离计算的位置,例如不同的云环境或数据中心。该架构有时被称为混合云或多云数据分析环境。
访问远端数据带来的挑战
随着主流应用框架提供的连接器越来越丰富,查询/转换远端数据逐渐成为可能。然而,由于网络延迟和带宽限制,访问远端存储数据也带来了挑战。如果某个数据集被多次读取,网络延迟时间也会成倍增加。当数据量非常大的时候,带宽可能会成为一个制约因素。此外,由于云服务商的定价不对称,流量成本可能会非常高。
两种方案
解决远程数据访问挑战的方案之一是将数据拷贝到应用计算引擎的本地位置,但该方案的难点在于维护数据副本以及副本相关的其他成本。此外,某些企业还因为监管、合规性或数据主权要求,不允许将数据拷贝到其他位置。
鉴于上述原因,Alluxio内部有这样的说法——数据拷贝产生的问题多于它能解决的问题。 Alluxio开源项目的开发初衷就是要让数据留在原地, 并解决数据访问和数据本地性问题。Alluxio可以与分布式应用框架并置部署。比如,你有100个Spark 或 Presto worker实例,那么可以将100个Alluxio worker与这些实例并置部署。Alluxio数据编排层能够把当前运行的数据集缓存到应用的本地位置,供应用访问。
Alluxio实现数据本地性示例
我们来看看在以下三种架构上运行的基本 Terasort 作业:
性能测试结果显示Alluxio执行查询时的性能水平十分接近本地查询:
为什么呢?因为 Alluxio 将数据集缓存到了 MapReduce worker的本地位置:
如需运行此程序的具体信息,请随时与我们联系。对于其他计算框架(Spark、Hive、Presto、TensorFlow、PyTorch)而言,以上测试结果也具有代表性。所有主流计算框架在部署Alluxio后都能从中获益。
要了解更多有关Alluxio如何解决网络延迟和带宽问题的信息,请点击此处。
 京公网安备 11010802040260号
京公网安备 11010802040260号





