




| Alluxio企业版 | Alluxio社区版 | ||
| 架构 对比 | 去中性化元数据架构 应对十亿、百亿规模硬链接的不合理元数据瓶颈导致系统性能大幅下降 | Master-Worker主从&中心化架构 在有亿级别的数据时,会有较严重的元数据性能下降 | |
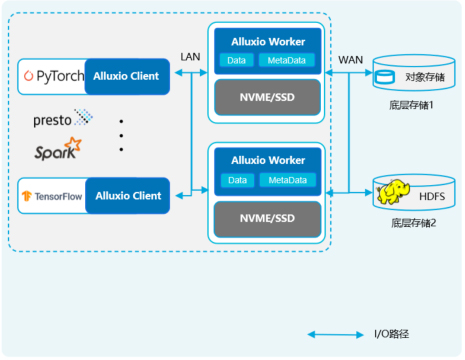 |
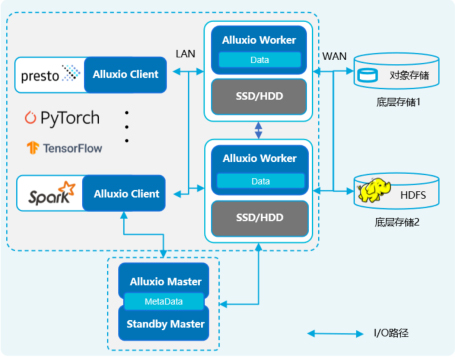 |
||
| 扩展性 | 单个集群可支持的对象数 | 100亿↑ | 1亿↓ |
| IO性能线性扩展 | 支持☑ | 不支持× | |
| 单个Client的最大并发度 | 200+个线程↑ | 32个线程↓ | |
| 集群管理 | Kubernetes Operator | ☑ 引入 Kubernetes Operator 简化集群部署和管理,确保不同环境中的部署一致性,优化硬件利用率,提供持续监控,并将常规任务自动化:Pod 配置、服务配置、挂载 UFS 卷 | 仅包含HELM Chart 提供了HELM chart,支持在Kubernetes环境中启动Alluxio社区版 |
| 作业调度器 (Job Scheduler) | 内置于Alluxio Core 通过将Job scheduler集成到Alluxio Core中,简化部署和管理 | 需额外进程 | |
| 异构worker资源 (CPU、内存、网络、磁盘) | 支持具有异构资源配置的Alluxio Worker节点加入同一个Alluxio集群,提供更高灵活性 | × 要求每个Alluxio Worker节点具有相同的资源配置 | |
| 数据访问 | Client侧UFS回退机制 | ☑ 客户端UFS回退功能在企业版中可用,当 Alluxio Worker无响应时,Alluxio Client 可无缝访问底层文件系统(UFS)中的数据,从而提供对应用程序的持续性保障 | × 如果Alluxio Worker无响应,Alluxio Client的请求会超时,导致整个应用程序工作负载中断 |
| 计算侧兼容协议 | POSIX协议兼容AI训练 | POSIX协议兼容AI训练(协议支持不完善) | |
| 透明数据湖集成 | ☑ 透明数据湖集成功能使应用程序代码能够通过现有文件系统路径(例如 s3://)访问Alluxio中的数据 | × 应用程序代码需要更新为使用 alluxio:// 路径访问Alluxio中的数据 | |
| UFS读速率限制器 | ☑ 管理员可通过设置速率限制,来控制单个 Alluxio Worker 从UFS读取数据时所使用的最大带宽,通过配置 UFS 读取速率限制器,实现资源的优化利用 | × | |
| 缓存管理 | 数据加载器和缓存释放 | 支持基于目录或文件列表的加载/释放 对数据加载器(用于缓存预加载)和缓存释放(用于手动从缓存中驱逐数据)功能进行了全面升级,除了基于目录之外,新增基于文件列表的灵活加载和释放 | 仅支持基于目录的加载/释放;仅支持将整个目录加载到缓存中或从缓存中驱逐 |
| 配额管理 | 顶级目录和嵌套目录 | 不支持基于目录的配额管理 | |
| 缓存存储单元 | Page (4MB) 使用更小且更高效的基于page的缓存存储单元(小于或等于 UFS block 大小,且可配置); | Block (64MB)↓ | |
| 读放大: < 20% 企业版中基于page的缓存将社区版中5-10倍的读放大系数降低到不到原先的20% | 读放大: 5-10倍↓ | ||
| 基于优先级的缓存驱逐 | ☑ 允许管理员为特定目录/文件设置缓存驱逐优先级。即使是本应被驱逐的目录和文件,如果被分配高优先级,也会被保留在缓存中 | × | |
| 缓存过滤 | ☑ 缓存过滤功能允许管理员设置过滤规则,管理哪些文件会被缓存、是否需要检查以及按照什么频次检查底层文件系统(UFS)的元数据或数据变化 | × 不支持正则,只能够按照目录/文件设定是否缓存,并且不区分元数据/数据缓存 | |
| 异步缓存驱逐 | ☑ 通过异步驱逐数据提高性能,尽量避免在缓存写入时驱逐数据。管理员可根据缓存容量和/或最大可缓存page配置异步缓存驱逐策略 | × 仅支持在缓存写入时驱逐数据 | |
| CLIENT和 SDK | S3 API网关 | 内置于Alluxio Core S3 API 网关内置于 Alluxio Worker进程中,通过移除代理代理进程,消除了 Client 与 Worker 间的额外跳转,同时在Kubernetes环境中降低了由于管理代理进程而导致的部署复杂性 | 需额外进程 |
| 网络传输优化 | 高性能零拷贝网络传输 零拷贝传输通过清除Protobuf序列化降低了CPU占用,同时使用更优化的内存管理机制,有效缓解了内存不足问题 | 基于拷贝的网络传输 | |
| Python SDK | ☑ 基于 FSSpec 的原生 Python SDK,强化了与主流 AI 框架的集成 | × | |
| 安全性 | TLS支持 | ☑ 包含TLS支持,可确保Alluxio组件之间以及Alluxio与底层文件系统(UFS)之间安全通信 | × |
| CVE补丁 | ☑ Alluxio会监控常见漏洞与披露(CVE)记录,并在必要时及时向企业版客户提供补丁 | × | |
| 安全审计日志 | ☑ Alluxio审计日志功能提供对所有数据访问和操作的完整可视化追踪。每一次与Alluxio交互都会被自动记录,包括:用户身份与认证信息;执行的操作(读取、写入、删除等);精确时间戳;被访问的资源与路径。 | × 元数据的访问记录,日志量较大 | |
| 产品支持 与服务 | 7x24小时技术支持 | ☑ | × |
| 紧急修补 | ☑ | × | |
| 专业服务-运维状态检查 | ☑ | × | |
| 服务与最佳实践 | ☑ | × | |
我们利用GPU本身的SSD硬盘来搭建Alluxio集群,并且通过Alluxio的多副本特性来解决跨机器、跨AZ拉取文件的问题,不仅能够对带宽带来极大的减少,还能降低对文件存储的Burst流量,让直接文件读取效率提升了85%。
我们已在双集群的百节点部署了Alluxio,整体可用性达到99.95%,缓存命中超过95%+,支持着PB级百亿海量文件的的千卡训练集群规模,为鉴智机器人的大规模AI视觉训练提供了高性能、高可靠、低成本的加速方案,成为自动驾驶技术迭代的“数据引擎”。
Alluxio的缓存机制通过内存级数据加速,大幅降低了我们数据访问延迟,提升了训练效率,并充分发挥了GPU算力价值,利用率提升超过10%,训练任务端到端用时减少了20-30%。
Alluxio 无论是在多机还是单节点的训练和推理上,完全都可以通过分布式的缓存高效加载我们需要的数据,并且alluxio worker 节点非常容易扩容。目前我们底层的存储如HDFS,Ceph和SeaweedFS都是通过Alluxio进行访问。
Alluxio作为我们基础模型训练架构中的数据加速层,不仅显著提升了训练效率,也为我们的商业化落地提供了坚实的支撑。基础模型训练速度提升高达35%。"这一提升直接转化为更快的产品迭代和更低的研发成本。
“在引入 Alluxio 之前,我们每周都要花费数小时来手动管理模型分发 pipeline 和冷启动时间。借助 Alluxio 的分布式缓存,我们彻底消除了冷启动延迟,原本需要数小时的任务现在只需几分钟即可完成。该解决方案能无缝适应我们的业务增长,让工程团队得以专注于功能开发,而无需耗费大量精力维护基础设施。”
“借助 Alluxio,我们成功为机器学习交易模型打造了必要的低延迟特征存储。它将我们离线特征存储的多表连接查询延迟降低至两位数毫秒级,让我们得以在15分钟的交易窗口内处理超过10万个模型。”


