对于许多客户而言,Alluxio 通常被用作云对象存储之上的分布式、兼容 S3 的读缓存,并通过穿透写语义确保数据持久性。我们曾在《 Alluxio + S3:面向低延迟、语义丰富的分层架构》一文中详细探讨过其在读密集型负载下的性能与架构设计。
真实案例:处理大规模突发性PUT请求
1、在高峰时段吸收突发性上传流量,待流量回落后将数据持久化存储至对象存储;
2、支持写后即读(read-after-write)访问;
3、所有能力都需在保持兼容 S3 语义的前提下实现,且对现有数据工作流进行极少或零改动。
在对象存储前端部署透明写缓存
1、可以继续使用 boto3 或 AWS SDK;
2、可以继续与 S3 协议兼容的服务端进行交互。
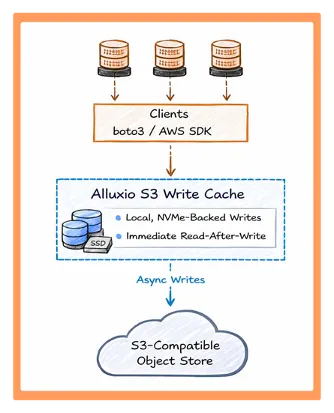
|
| 图1:Alluxio S3 写缓存改变了写入和写后即读的延迟模型。应用程序可继续使用标准的 S3 API。 PUT 请求在由本地 NVMe 承载的 Alluxio worker 上完成,数据可立即读取,向对象存储的持久化操作则在后台异步进行。 |
基准测试
- 1 台 Alluxio Worker 节点:i3en.metal
- 1 台 Warp 客户端:c5n.metal
测试 1:PUT延迟(10KB )
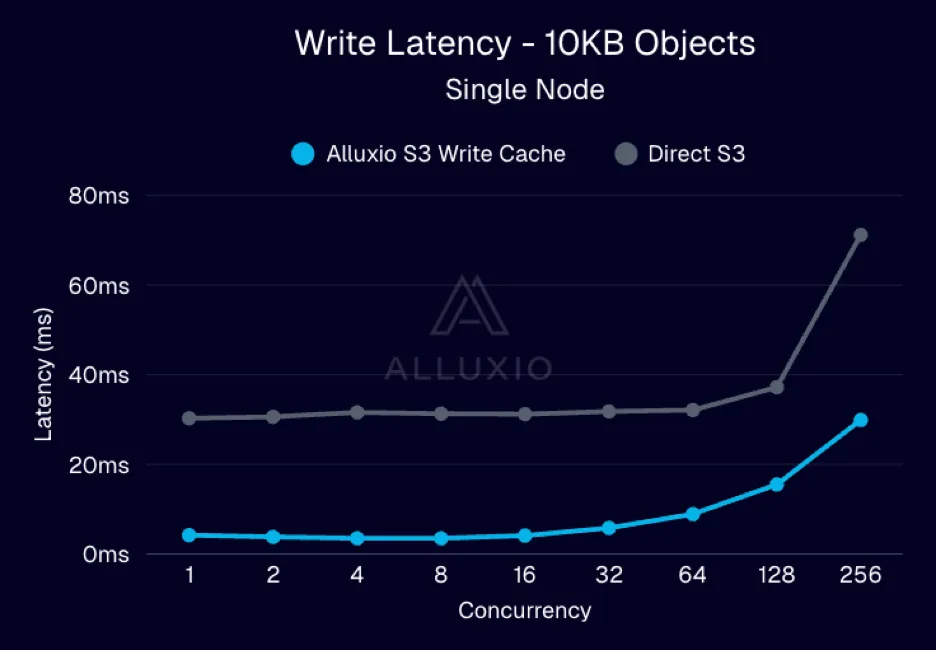 |
| 图2:并发场景下小对象PUT延迟降低7-8倍 |
测试 2:写后即读的延迟(10KB)
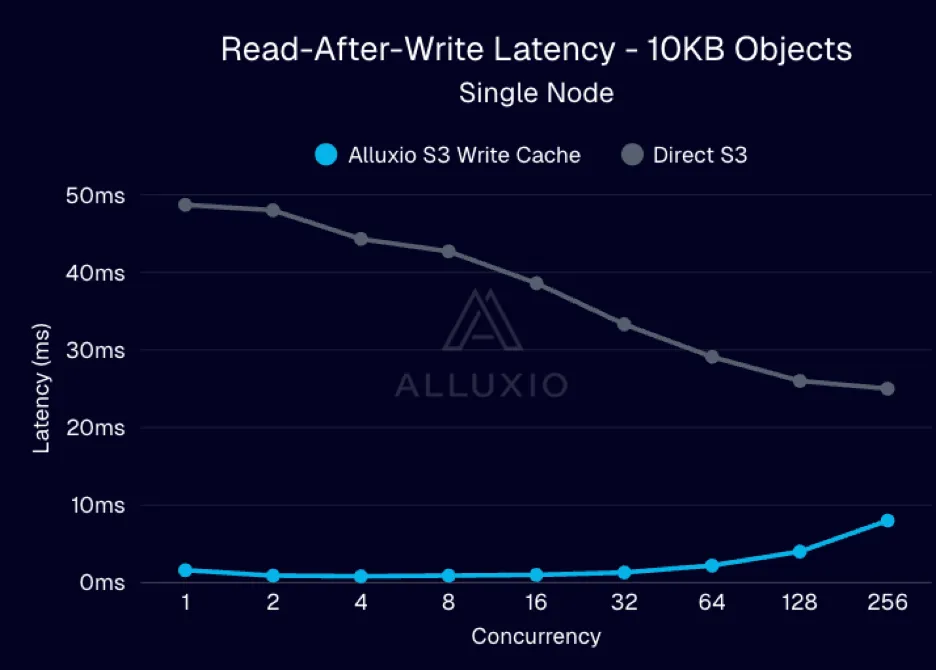 |
| 图3:并发场景下,写后即读的速度提升了10倍 |
2、采用 Alluxio 时,低并发场景下写后即读的延迟仅为 1-2 毫秒,即使随着并发量增加,延迟仍能稳定控制在 10 毫秒以下。
测试 3:通过采用多worker来扩展写入和写后即读的吞吐量
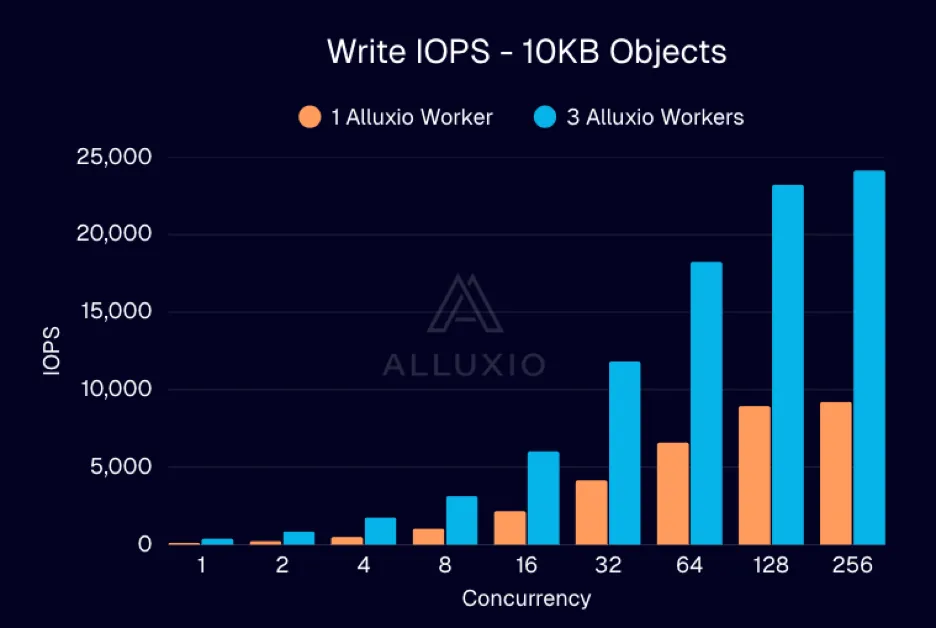 |
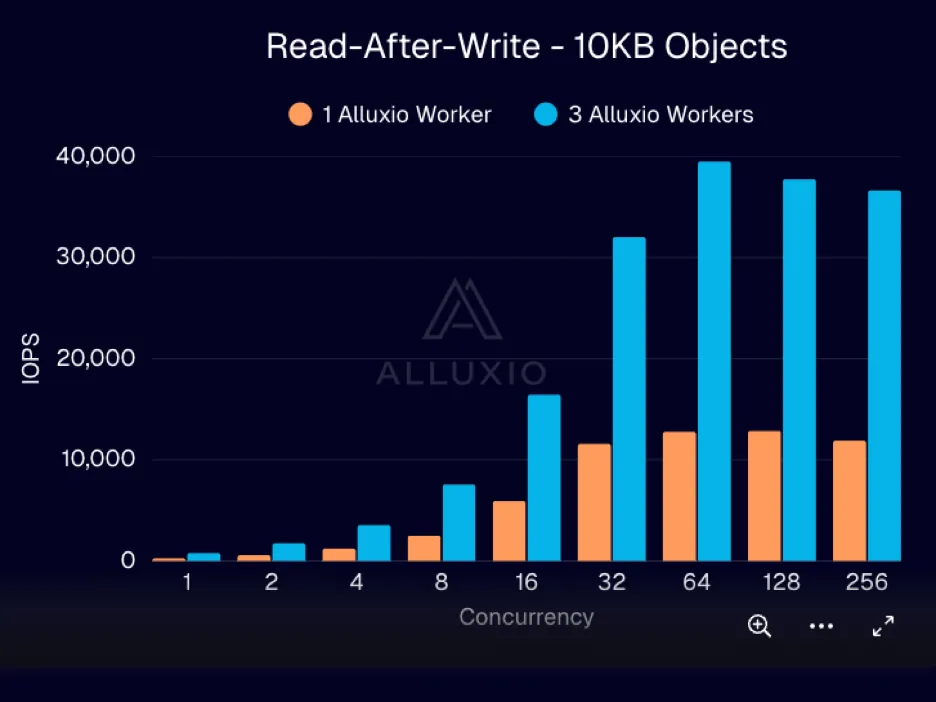 |
| 该图展示了随着客户端并发数增加,写入吞吐量(PUT 10 KB)和写后即读吞吐量(以 IOPS 为单位)的变化趋势 |
基准测试结果摘要
最终结论
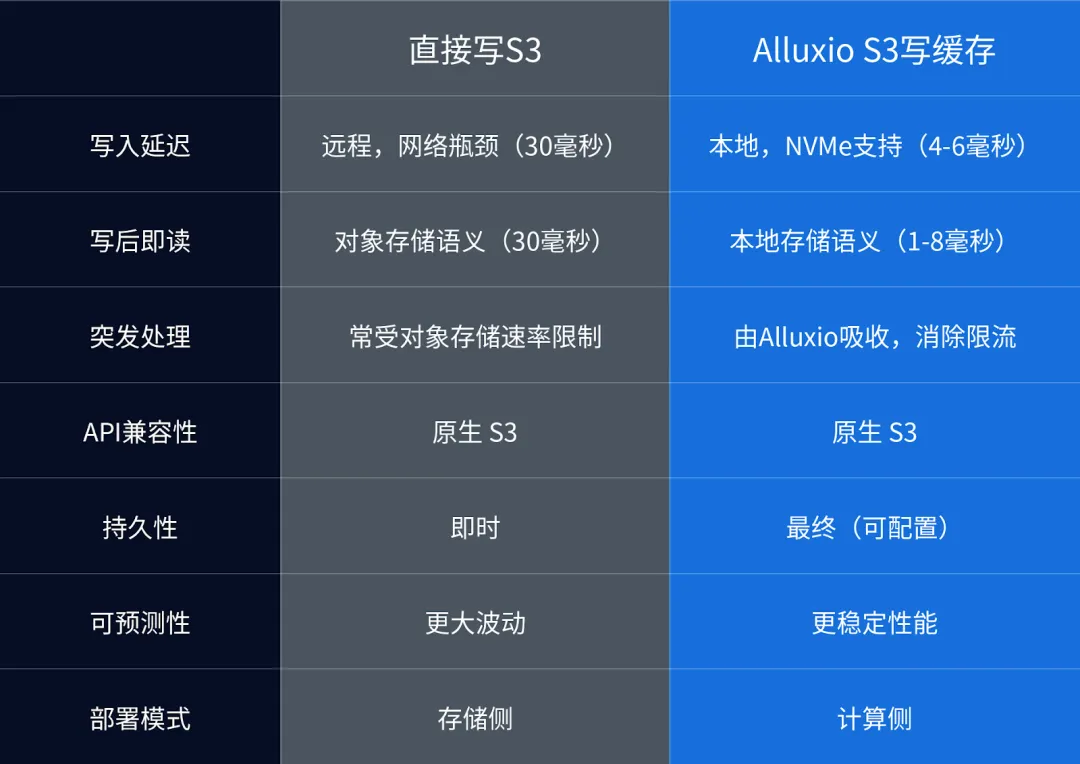 |
| Alluxio 写缓存与直接写 S3 对比 |








