
Alluxio 是一款云原生数据加速层。随着当今计算性能已远超数据访问能力,Alluxio 旨在弥合高性能 GPU 计算与分布式云存储之间的鸿沟,解决现代 AI 基础设施面临的关键 I/O 和数据搬运挑战。
去中心化对象存储库架构 DORA(Decentralized Object Repository Architecture)通过完全去中心化的元数据和缓存设计,消除了集中式元数据管理瓶颈,在大规模多云环境中实现了亚毫秒级延迟、TB/s 吞吐量以及 97%-98% 的 GPU 利用率。
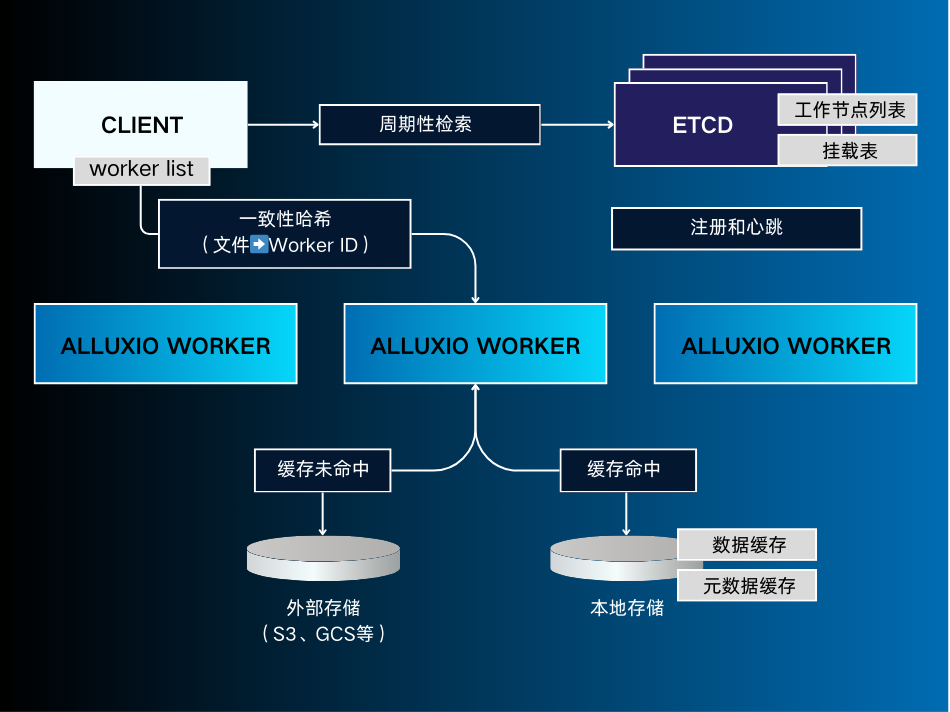 |
| 图1:DORA架构图 |
需求与挑战
破局之道:呼唤“简单、快速、可扩展”的数据访问层:
为此,Alluxio 提供了一套高效的解决方案。它让研究人员和工程师能够在计算节点所在的位置,无缝访问到分布各处的数据——用户只需将云存储桶像本地文件夹一样挂载,即可享受到接近本地NVMe的访问性能,无需任何数据迁移,立即可用。
现有解决方案的不足之处
AI 生态系统中有许多数据解决方案,但没有一种能同时满足可扩展性、简洁性和云上移动性这三个维度的需求:
1、单节点 CLI 工具(如 s3fs、gcsfs):便于在单节点上挂载对象存储,但缺乏跨集群的分布式能力、共享能力和并发处理能力。
2、HPC(高性能计算)存储系统(如 Lustre、GPFS、VastData、Weka 等):它们性能出色,但操作和运维复杂,且较易成为成本高昂的数据孤岛,无法解决数据引力或跨云访问问题。
3、托管云缓存(如 AWS FSx for Lustre、GCP Anywhere Cache):在性能和目标用户体验上与 Alluxio 趋同,但需要专用配置,绑定于单一云环境,且缺少轻量级纯软件部署模式。
Alluxio的定位
Alluxio的有所为与有所不为
去中心化架构概述
中心化与去中心化元数据服务
这些访问模式的转变暴露了集中式元数据服务设计的局限性:
拥抱 AI 时代,拥抱去中心化
Alluxio 主要组件如下:
I/O 流程
核心设计原则
缓存引擎
细粒度缓存
缓存淘汰
文件级元数据缓存
零拷贝数据传输
底层文件系统(UFS):持久层
支持的存储系统
UFS 作为最终可信数据源和一致性模型
关键要点
面向用户:多协议访问
容错
总结








