当云端仿真任务从万级扩展到百万级,最先触到天花板的往往不是算力,而是数据。带宽买不够、存储买了用不完、自研缓存越来越重——这是大规模仿真平台在数据访问层几乎必然会经历的困境。
本文分享九识智能在这一演进过程中的实际路径:如何用 Alluxio 替代 PFS 和自研缓存,将 IO 带宽从 30GB/s 突破到 100GB/s 以上,同时降低架构复杂度。
关于作者
关于九识智能
业务背景:分布式仿真 pipeline 的数据访问架构

遇到的挑战:自研 Cache + PFS 组合的带宽瓶颈与成本困境
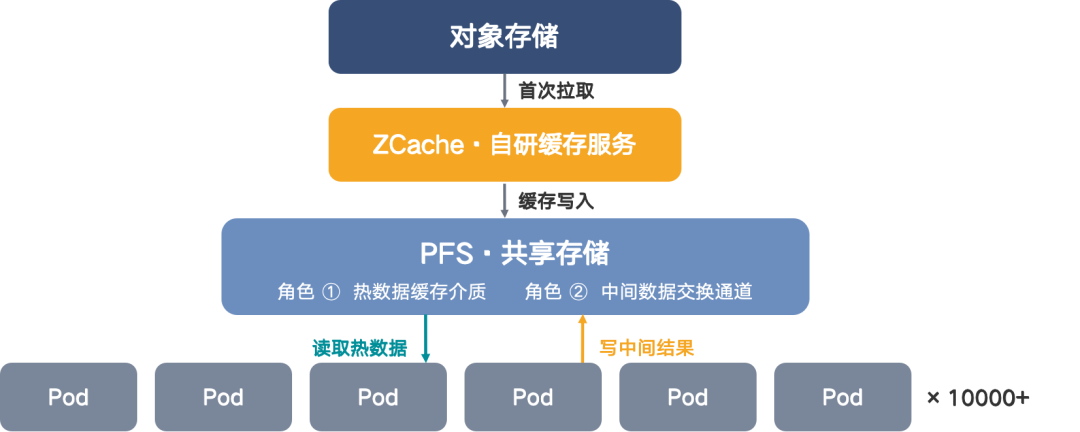
简单来说当任务运行的时候,会先去检查 ZCache 里面有没有缓存过这个热数据,如果有的话,会从共享存储的 PFS 直接读取;如果数据没有被缓存过,会从对象存储下载数据到自研缓存和 PFS,之后的任务就不需要进行重复的下载,相当于缓存命中。我们自研的缓存服务除了管理查询,还负责数据的淘汰,采用 LRU 算法管理整个缓存盘的空间。在业务规模相对可控的阶段,ZCache 有效缓解了对象存储的压力。

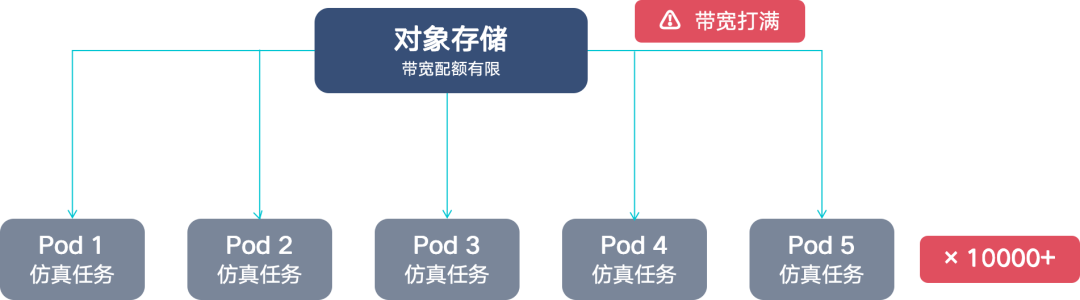
但随着并行任务量持续增长,新的瓶颈出现了——这次不在对象存储,而在 PFS 端。PFS 提供数据的读和写,其本身都是在云产品远端进行访问,所有的客户端 Pod 都会通过访问另一个集群的网关去访问 PFS。这个集群的整体带宽受限于通往网关的网络链路上最窄一环的带宽。当并行的 Pod 数越多,带宽就会越不够用。由于云厂商对 PFS 做了带宽限制,当带宽达到上限,我们整体任务处理的读和写就会很慢。这会直接影响到 GPU 节点,在读写原生接口的时候就会卡住,造成整体任务的延迟上升, GPU 利用率下降,吞吐也会不够。
为了解决这个问题,我们只能选择去扩充带宽。但是云厂商提供的 PFS 带宽和存储空间是绑定购买的:当我们去买带宽,存储空间也必须同时购买,即使我们每天用的热数据量并不大,但为了扩充带宽则需要增购存储空间,这样就会造成存储空间的浪费。其次,PFS 的带宽也不是无限可扩的。我们最初用的是普通版的 PFS,带宽最多扩到 30GB/s ,完全不能满足实际业务需求。对于这种情况,我们只能再去购买高性能版的 PFS,而该版本的价格则是普通版的好几倍,对我们来说很不合算。
此外,我们的 pipeline 数据处理模式是单读单写的。虽然 PFS 有一些高级特性,比如数百并发同时读写同一个文件,这种情况我们是没有的,对于 PFS 的强一致性,高级别的快照特性其实也用不上。我们都是上一环节把数据产出到共享存储,下一个环节再去处理,都是单写单读的过程。所以,本质上我们是在花钱买用不完的存储空间,仅仅为了换取所需带宽。
为什么选择 Alluxio:技术选型的核心考量
首先第一个调研的是 JuiceFS
第二个调研的产品是对象存储加速器
Alluxio 如何解决两个问题:读缓存层替代自研 Cache + PFS,Cache-Only 写缓存替代 PFS 中间数据交换
方面一: Alluxio 的性能
方面二:Alluxio 的读写特性
方面三:高可用
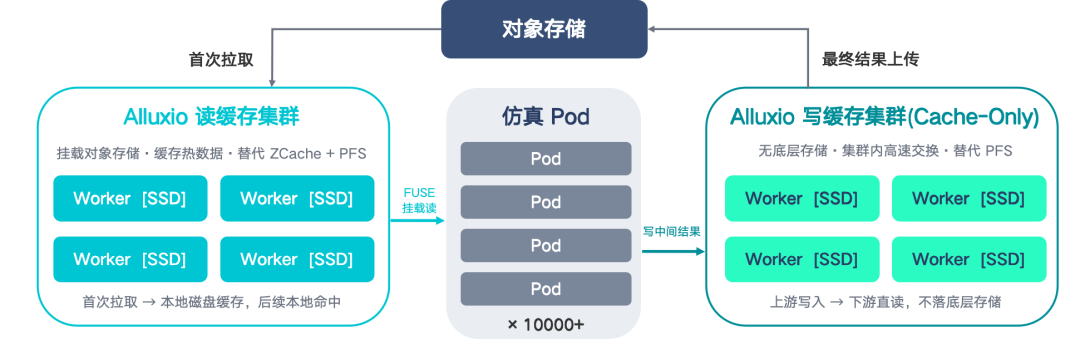
 以上我们架构演进的三个阶段。第一阶段是从对象存储直接把数据下载下来运行;第二阶段是从对象存储下载之后,加入到我们自研的缓存里;第三阶段是现在我们直接通过 Alluxio 进行数据的读取和管理,数据写入也是通过 Alluxio 写来实现。
以上我们架构演进的三个阶段。第一阶段是从对象存储直接把数据下载下来运行;第二阶段是从对象存储下载之后,加入到我们自研的缓存里;第三阶段是现在我们直接通过 Alluxio 进行数据的读取和管理,数据写入也是通过 Alluxio 写来实现。
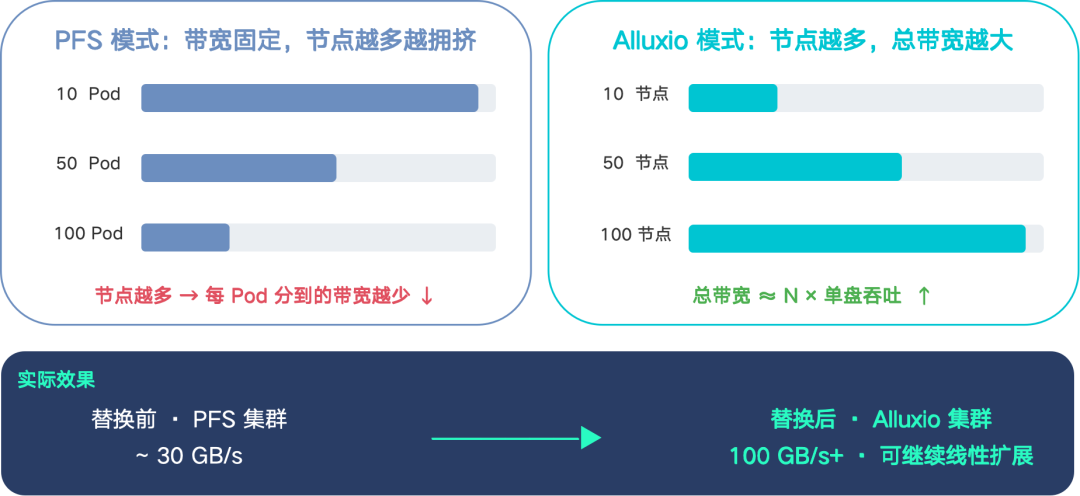
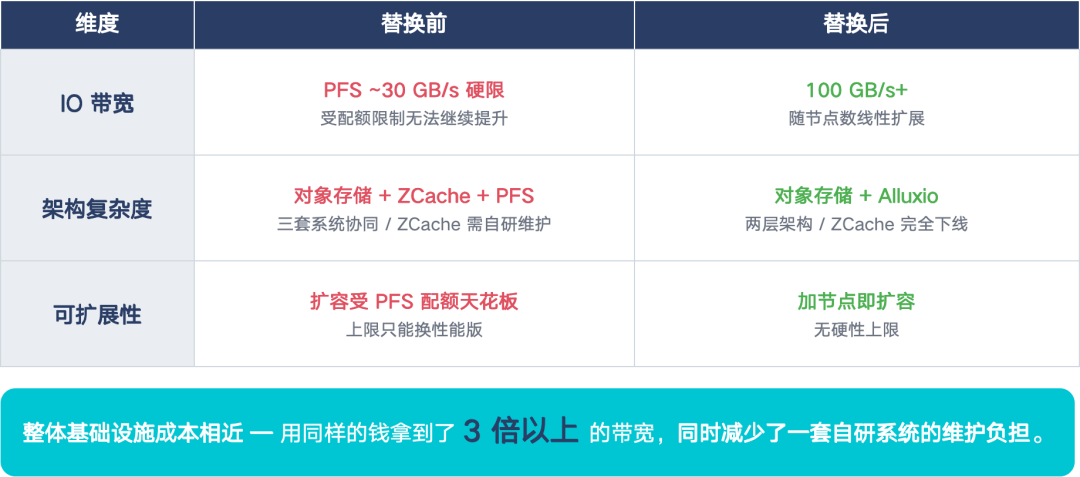
Alluxio 在我们大规模仿真场景的核心优势是:Alluxio 的 IO 带宽是可以随着业务需要的节点数线性扩展的,因为 Alluxio 的带宽来自每一个 worker 的本地磁盘,加一个节点就多一份带宽。而在 PFS 模式里,由于通往 PFS 网关的带宽是固定的,所以当你节点数越多,每个 Pod 分享到的带宽其实就越少,整体的读写性能就会很慢,延迟也会上去。实际效果是,我们之前 PFS 的集群总带宽大概 30GB/s,切到 Alluxio 之后可以轻松达到 100GB/s 以上,而且还可以继续加节点往上提,迄今为止还没有看到 Alluxio 的带宽上限。
我们在采用 Alluxio 之后的收益是显而易见的: