EN中文
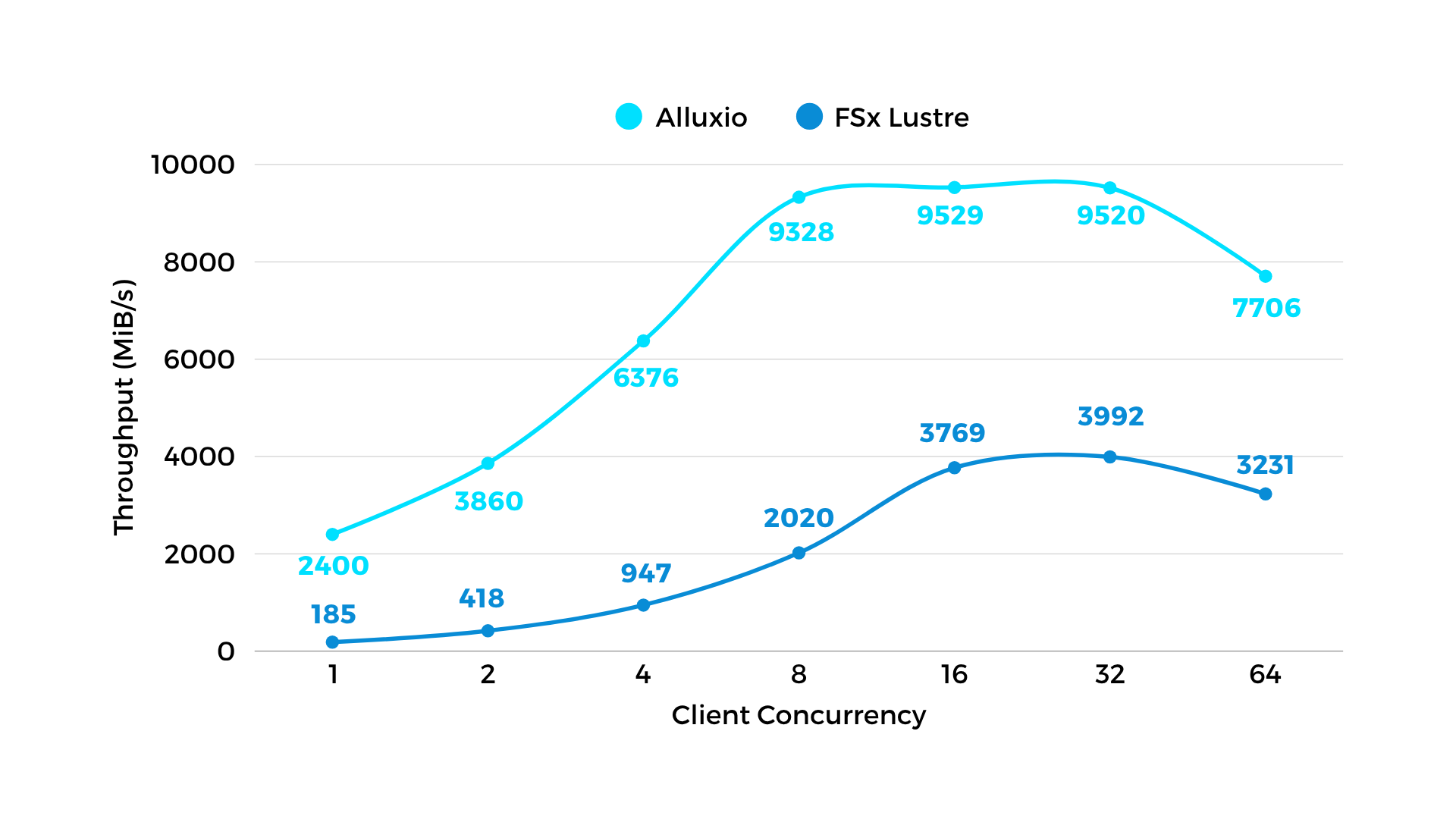
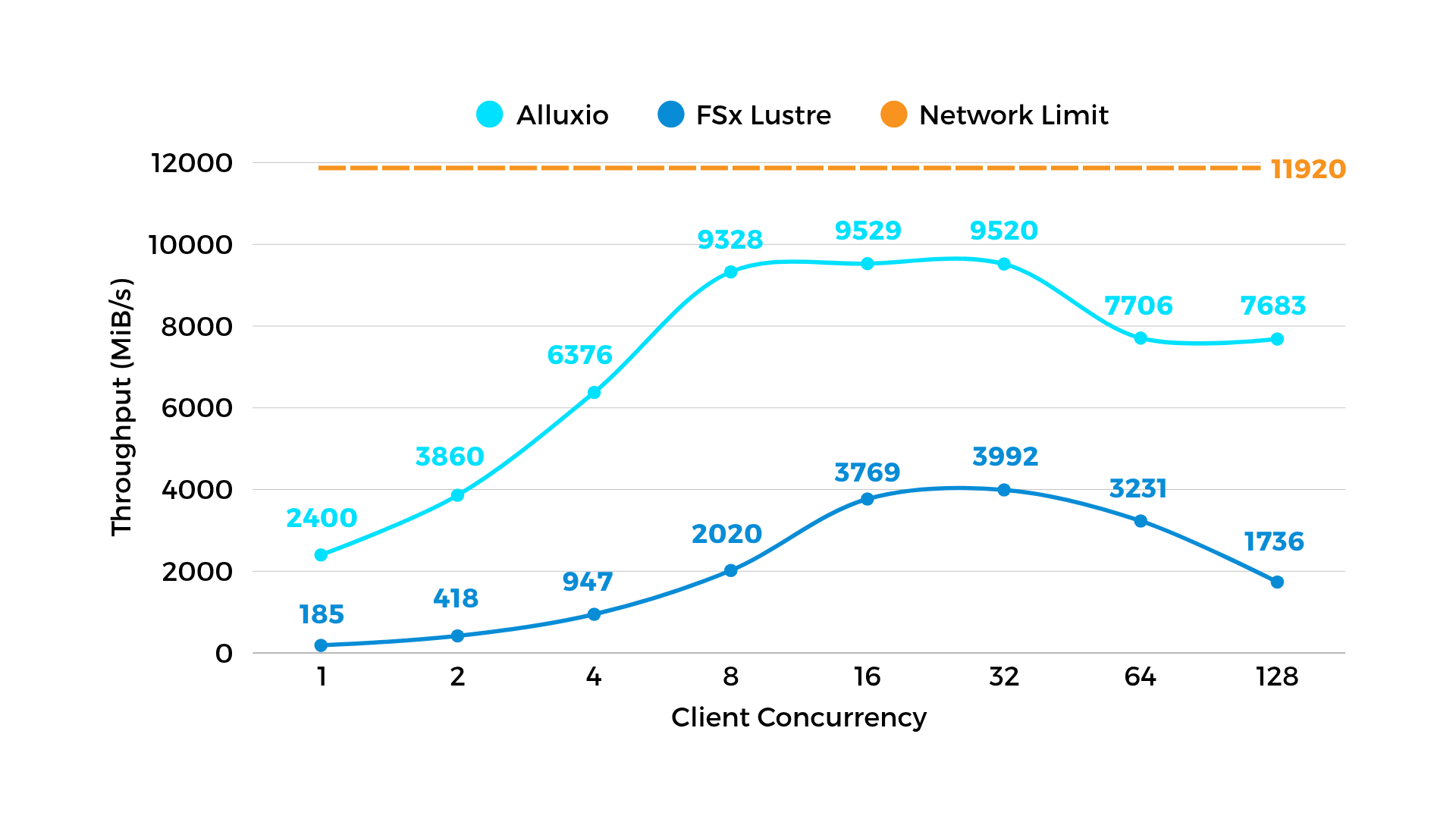
图 1:读吞吐 - 模拟训练数据集读取
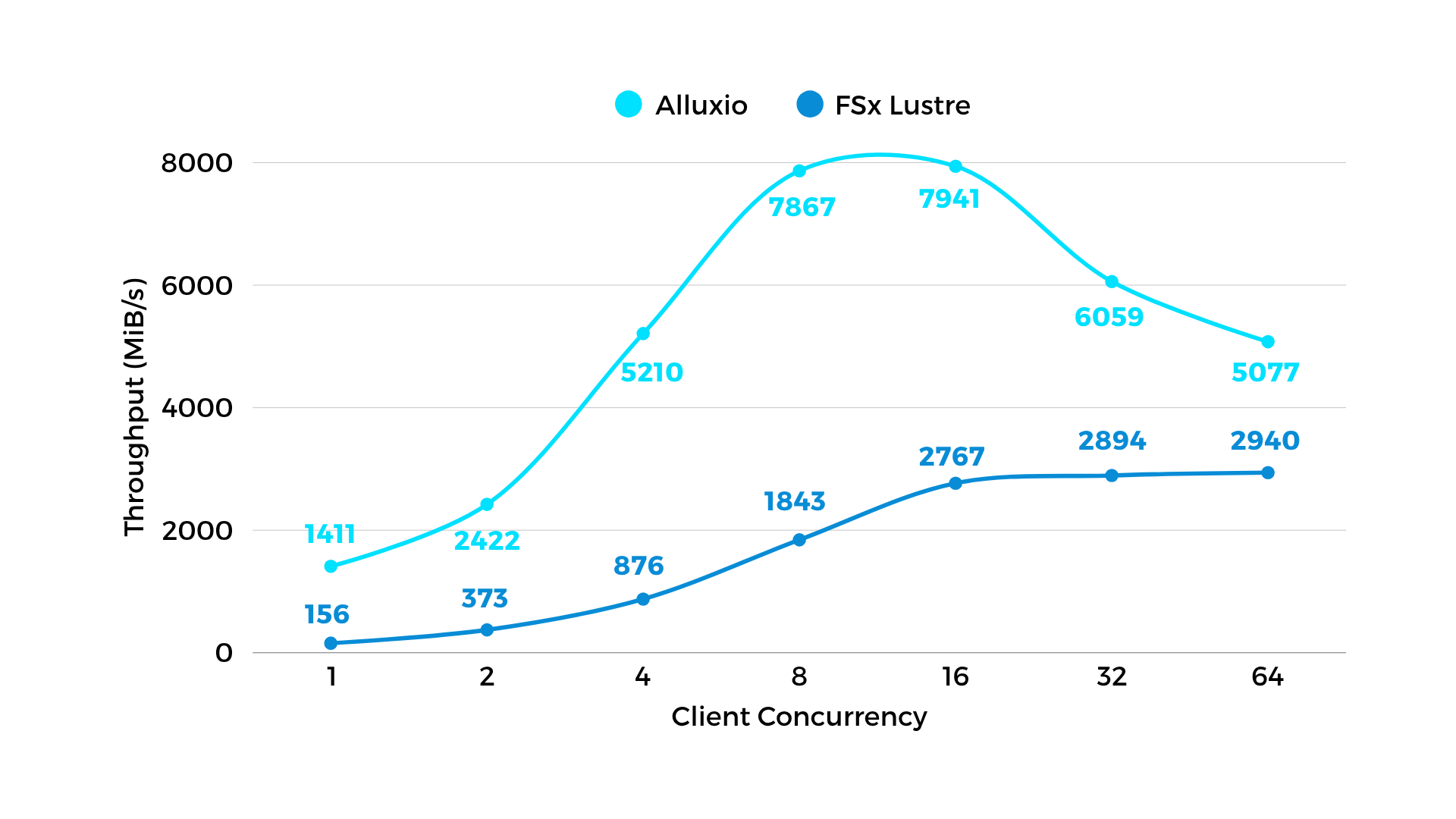
图 2:写吞吐 - 模拟chekpoint写入
图 3:Alluxio(浅蓝色线)的模型部署速度提高了 2 ~ 4 倍。
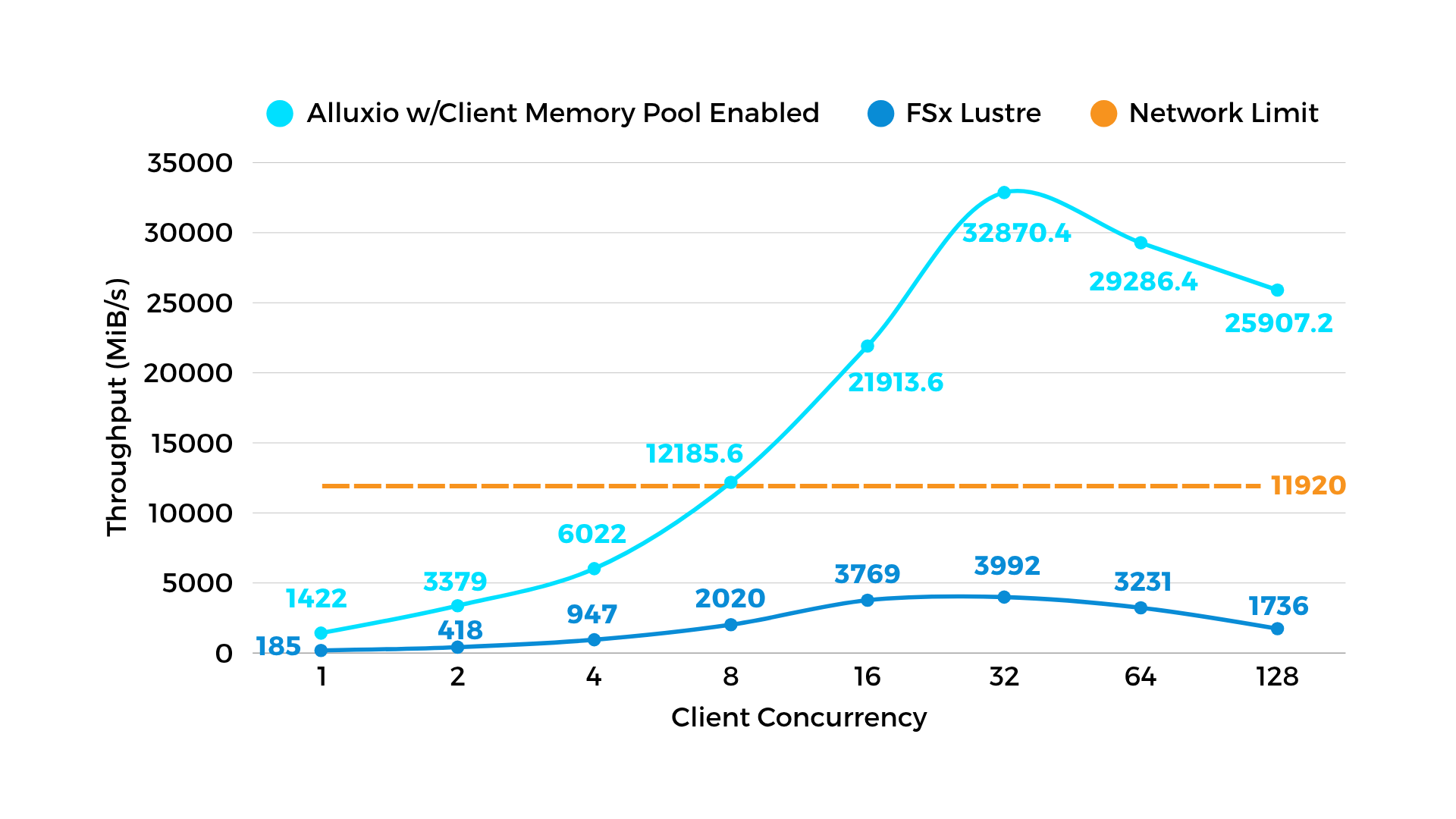
图 4:当将单个模型分布到同一节点上的多个 GPU 时,Alluxio 可以启用“客户端内存池”(AI 3.6 中的新功能)并提供高达 32GiB/s 的读取吞吐量,这比正常情况快 3 倍,并打破了网络限制。
“与并行文件系统相比,新的分布式缓存架构提高了模型训练速度,降低了存储成本,提高了跨集群的 GPU 利用率,降低了运营开销,实现了训练工作负载可移植性,并提供了 40% 更佳的 I/O 性能。”
Alluxio改变了游戏规则,将模型加载时间提高了3到6倍,并为我们的无服务器GPU计算服务提供了关键的多云敏捷性。通过Alluxio解决基本的I/O挑战,加载LLM权重的吞吐量可以提高10倍,接近硬件极限(千兆字节/秒吞吐量)。借助Alluxio,我们可以优化我们的基础设施,使公司能够以前所未有的速度和效率部署定制化的LLM。
不,Alluxio不是像Amazon FSx for Lustre的存储系统。Alluxio是一个AI规模的分布式缓存平台,为AI工作负载带来数据本地性和水平可扩展性。Alluxio不提供持久存储,相反,Alluxio具有Under File System的概念,可以利用您现有的数据湖和商用存储系统。相比之下,Amazon FSx for Lustre 是一种传统的并行文件系统,仅限于 AWS 生态,通常缺乏高级缓存或跨存储类型的联邦数据访问能力。
Alluxio专为以FSx for Lustre无法做到的方式加速AI工作负载而构建。与FSx相比,Alluxio提供:
无论您是在做模型训练、推理还是检索增强生成(RAG),Alluxio都能提供智能缓存和对AWS S3和其他数据湖的数据零拷贝访问,而不受FSx的限制。
当然可以,Alluxio提供了一个Kubernetes原生operator,简化了容器化AI平台的部署和集成。与 FSx 不同,它专为在云原生环境中顺利运行而构建。
不需要,Alluxio通过POSIX(FUSE)、S3、HDFS和Python API提供透明的数据访问,因此您可以将其与现有应用程序集成,而无需更改任何代码。
并不是,与 FSx 相比,即使您都在单个云(例如 AWS)中,您仍然可以从性能提升和成本节约中受益。
在与FSx的比较中,Alluxio仅存储成本就可以节省50-80%。此外,与FSx不同,Alluxio不对IOPS收费,而IOPS费用可能很高。
Alluxio专为AI工作负载而设计,包括生成式人工智能、LLM训练和推理、多模态、智能驾驶系统和机器人技术、agentic系统等。Alluxio为金融科技、智能驾驶、具身智能、机器人技术、推理即服务、社交媒体内容平台、企业AI等各行各业的人工智能平台提供支持。





 京公网安备 11010802040260号
京公网安备 11010802040260号



