分享专家:
陈传迎——蚂蚁高级开发工程师
背景介绍
首先是我们为什么要引入Alluxio,其实我们面临的问题和业界基本上是相同的:
- 第一是存储IO的性能问题,目前gpu的模型训练速度越来越快,势必会对底层存储造成一定的压力,如果底层存储难以支持目前gpu的训练速度,就会严重制约模型训练的效率。
- 第二是单机存储容量问题,目前我们的模型集合越来越大,那么势必会造成单机无法存放的问题。那么对于这种大模型训练,我们是如何支持的?
- 第三是网络延迟问题,目前我们有很多存储解决方案,但都没办法把一个高吞吐、高并发以及低延时的性能融合到一起,而Alluxio为我们提供了一套解决方案,Alluxio比较小型化,随搭随用,可以和计算机型部署在同一个机房,这样可以把网络延时、性能损耗降到最低,主要出于这个原因我们决定把Alluxio引入蚂蚁集团。
以下是分享的核心内容:总共分为3个部分,也就是Alluxio引入蚂蚁集团之后,我们主要从以下三个方面进行了性能优化:第一部分是稳定性建设、 第二部分是性能优化、第三部分是规模提升。
稳定性建设
首先介绍为什么要做稳定性的建设,如果我们的资源是受k8s调度的,然后我们频繁的做资源重启或者迁移,那么我们就需要面临集群频繁的做FO,FO的性能会直接反映到用户的体验上,如果我们的FO时间两分钟不可用,那么用户可能就会看到有大量的报错,如果几个小时不可用,那用户的模型训练可能就会直接kill掉,所以稳定性建设是至关重要的,我们做的优化主要是从两块进行:一个是worker register follower,另外一个是master迁移。
Worker Register Follower
先介绍下这个问题的背景:上图是我们Alluxio运行的稳定状态,由master进行元数据服务,然后内部通过raft的进行元数据一致性的同步,通过primary对外提供元数据的服务,然后通过worker节点对外提供data数据的服务,这两者之间是通过worker注册primary进行一个发现,也就是worker节点的发现,这样就可以保证在稳定状态下运行。那如果这时候对primary进行了重启,就需要做一次FO的迁移,也就是接下来这个过程,比如这时候对primary进行了重启,那么内部的standby就需要通过raft进行重新选举,选举出来之前,其实primary的元数据和worker是断联的,断连的状态下就需要进行raft的一致性选举,进行一次故障的转移,接下来如果这台机器选举出来一个新的primary,这个时候work就需要重新进行一次发现,发现之后注册到primary里面,这时新的primary就对外提供元数据的服务,而worker对外提供data数据的服务,这样就完成了一次故障的转移,那么问题点就发生在故障发生在做FO的时候,worker发现新的primary后需要重新进行一次注册,这个部分主要面临三个问题:
- 第一是首个worker注册前集群是不可用的,因为刚开始首个worker恢复了新的primary领导能力,如果这个时候没有worker,其实整个primary是没有data节点的,也就是只能访问元数据而不能访问data数据。
- 第二是所有worker注册过程中,冷数据对性能的影响。如果首个worker注册进来了,这时就可以对外提供服务,因为有data节点了,而在陆续的注册的过程当中如果首个节点注册进来了,然后后续的节点在注册的过程当中,用户访问worker2的缓存block 的时候,worker2处于一种miss的状态,这时候data数据是丢失的,会从现存的worker中选举出来到底层去读文件,把文件读进来后重新对外提供服务,但是读的过程当中,比如说worker1去ufs里面读的时候,这就牵扯了一个预热的过程,会把性能拖慢,这就是注册当中的问题。
- 第三是worker注册完成之后的数据冗余清理问题。注册完成之后,其实还有一个问题就是在注册的过程当中不断有少量数据进行了重新预热,worker全部注册之后,注册过程中重新缓存的这部分数据就会造成冗余, 那就需要进行事后清理,按照这个严重等级其实就是第一个worker注册前,这个集群不可用,如果worker规格比较小,可能注册的时间2-5分钟,这2-5分钟这个集群可能就不可用,那用户看到的就是大量报错,如果worker规格比较大,例如一个磁盘有几tb的体量,完全注册上来需要几个小时。那这几个小时整个集群就不可对外提供服务,这样在用户看来这个集群是不稳定的,所以这个部分是必须要进行优化的。
我们目前的优化方案是:把所有的worker向所有的master进行注册,提前进行注册,只要worker起来了 那就向所有的master重新注册一遍,然后中间通过这种实时的心跳保持worker状态的更新。那么这个优化到底产生了怎样效果?可以看下图:
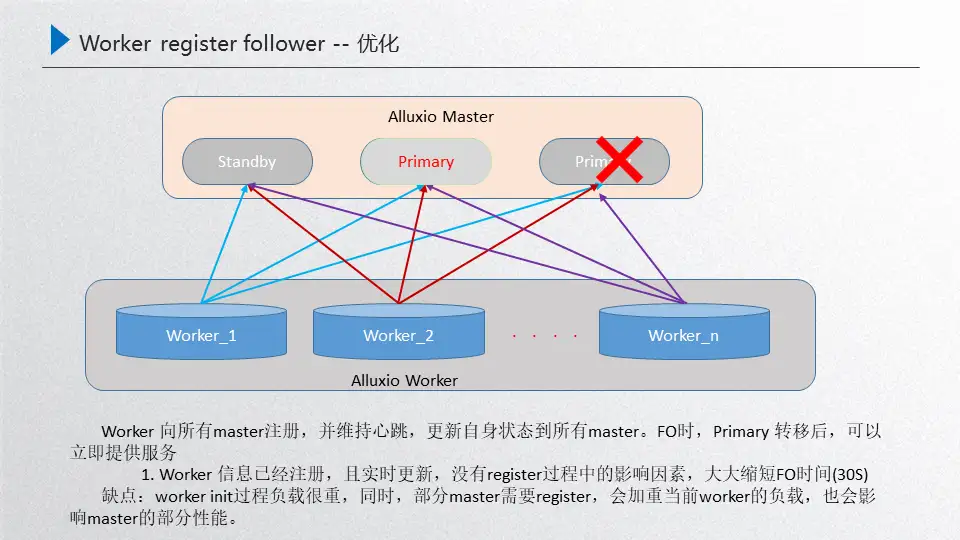
这个时候如果primary被重启了,内部通过raft进行选举,选举出来的这个新的primary对外提供服务,primary的选举需要经历几部分:第一部分就是primary被重启之后,raft进行自发现,自发现之后两者之间进行重新选举,选举出来之后这个新的primary经过catch up后就可以对外提供服务了,就不需要重新去获取worker进行一个register,所以这就可以把时间完全节省下来,只需要三步:自发现、选举、catch up。
这个方案的效率非常高,只需要30秒以内就可以完成,这就大大缩短了FO的时间。另一个层面来说,这里也有一些负面的影响,主要是其中一个master如果进行了重启,那么对外来说这个primary是可以提供正常服务的,然后这个standby重启的话,在对外提供服务的同时,worker又需要重新注册这个block的元数据信息,这个block元数据信息其实流量是非常大的,这时会对当前的worker有一定影响,而且对部分注册上来的master性能也有影响,如果这个时候集群的负载不是很重的话,是完全可以忽略的,所以做了这样的优化。
Master的迁移问题
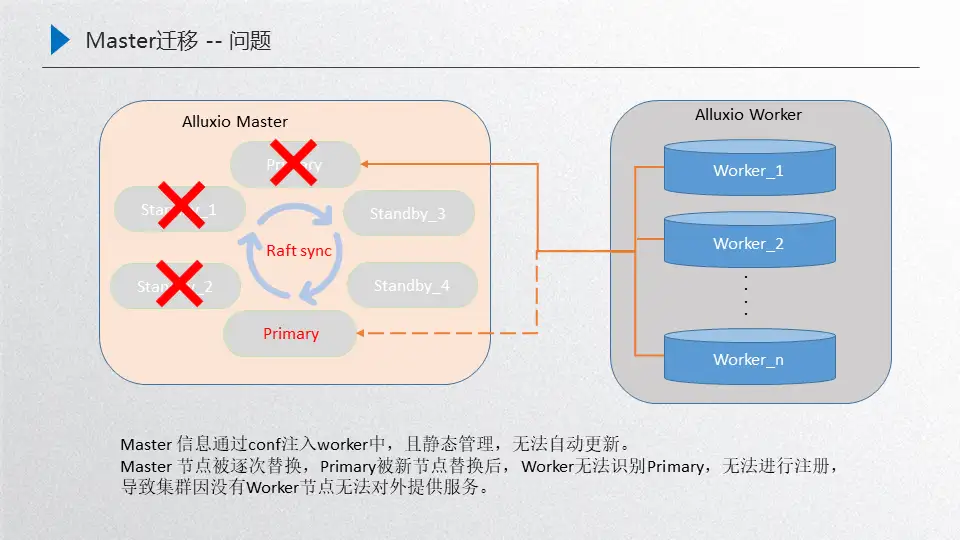
如图所示,其实刚开始是由这三者master对外提供服务, 这三者达到一个稳定的状态,然后worker注册到primary对外提供服务,这个时候如果对机器做了一些腾挪,比如standby3把standby1替换掉,然后standby4把standby2替换掉,然后新的primary把老的primary替换掉,这个时候新的这个master的集群节点就是由这三者组成:standby3、standby4、新的primary,按照正常的流程来说,这个worker是需要跟当前这个新的集群进行建联的,维持一个正常的心跳,然后对外提供服务,但是这时候并没有,主要原因就是worker识别的master信息其实是一开始由configer进行静态注入的,在初始化的时候就已经写进去了,而且后台是静态管理的,没有动态的更新,所以永远都不能识别这三个节点, 识别的永远是三个老节点,相当于是说这种场景直接把整个集群搞挂了,对外没有data节点就不可提供服务了,恢复手段主要是需要手动把这三个新节点注册到configer当中,重新把这个worker重启一遍,然后进行识别,如果这个时候集群规模比较大,worker节点数量比较多,那这时的运维成本就会非常大,这是我们面临的master迁移问题,接下来看一下怎么应对这种稳定性:
我们的解决方案是在primary和worker之间维持了一个主心跳,如果master节点变更了就会通过主心跳同步当前的worker,实现实时更新master节点,比如standby3把standby1替换掉了,这个时候primary会把当前的这三个节点:primary、standby2、standby3通过主心跳同步过来给当前的worker,这个时候worker就是最新的,如果再把standby4、standby2替换,这时候又会把这三者之间的状态同步过来,让他保持是最新的,如果接下来把新的primary加进来,就把这四者之间同步过来,重启之后进行选举,选举出来之后 这就是新的primary,由于worker节点最后的一步是存着这四个节点,在这四个节点当中便利寻找当前的leader,然后就可以识别新的primary,再把这三个新的master同步过来 这样就达到一个安全的迭代过程,这样的情况下再受资源调度腾挪的时候,就可以稳定的腾挪下去。
以上两部分就是稳定性建设的内容。
性能优化
性能优化我们主要进行了follower read only的过程,首先给大家介绍一下背景,如图所示:
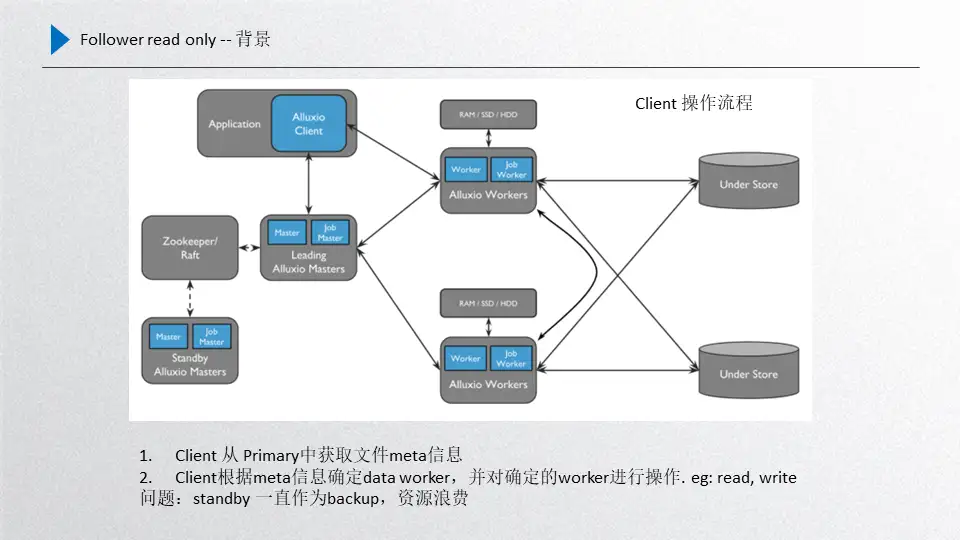
这个是当前Alluxio的整体框架,首先client端从leader拿取到元数据,根据元数据去访问正常的worker,leader和standby之间通过raft进行与元数据一致性的同步,leader进行元数据的同步只能通过leader发起然后同步到standby,所以说他是有先后顺序的。而standby不能通过发起新的信息同步到leader,这是一个违背数据一致性原则的问题。
另一部分就是当前的这个standby经过前面的worker register follower的优化之后,其实standby和worker之间也是有一定联系的,而且数据都会收集上来,这样就是standby在数据的完整性上已经具备了leader的属性,也就是数据基本上和leader是保持一致的。
而这一部分如果再把它作为backup,即作为一种稳定性备份的话,其实就是一种资源的浪费,想利用起来但又不能打破raft数据一致性的规则,这种情况下我们就尝试是不是可以提供只读服务, 因为只读服务不需要更新raft的journal entry,对一致性没有任何的影响,这样standby的性能就可以充分利用起来,所以说这里想了一些优化的方案,而且还牵扯了一个业务场景,就是如果我们的场景适用于模型训练或者文件的cache加速的,那只有第一次预热的时候数据才会有写入,后面是只读的,针对大量只读场景应用standby对整个集群的性能取胜是非常可观的。
下面是详细的优化方案,如图所示:
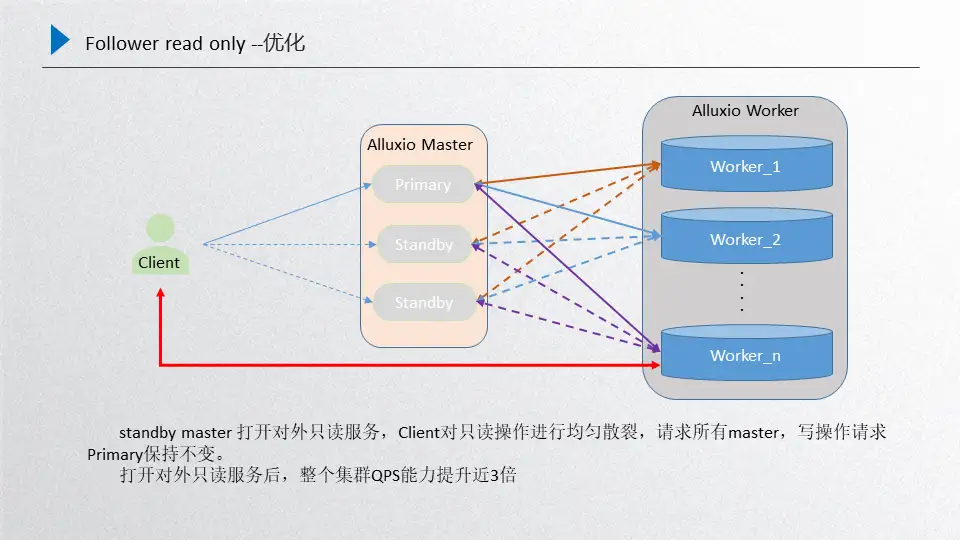
主要是针对前面进行的总结,所有的worker向所有的standby进行注册,这时候standby的数据和primary的数据基本上是一致的,另一部分还是primary和worker之间维护的主心跳,这个时候如果client端再发起只读请求的时候,就会随机散列到当前所有的master上由他们进行处理,处理完成之后返回client端,对于写的请求还是会发放到primary上去。然后在不打破raft一致性的前提下,又可以把只读的性能提升,这个机器扩展出来,按照正常推理来说,只读性能能够达到三倍以上的扩展,通过follower read实际测验下来效果也是比较明显的。这是我们引入Alluxio之后对性能的优化。
规模提升
规模提升主要是横向扩展,首先看一下这个问题的背景:如图所示:
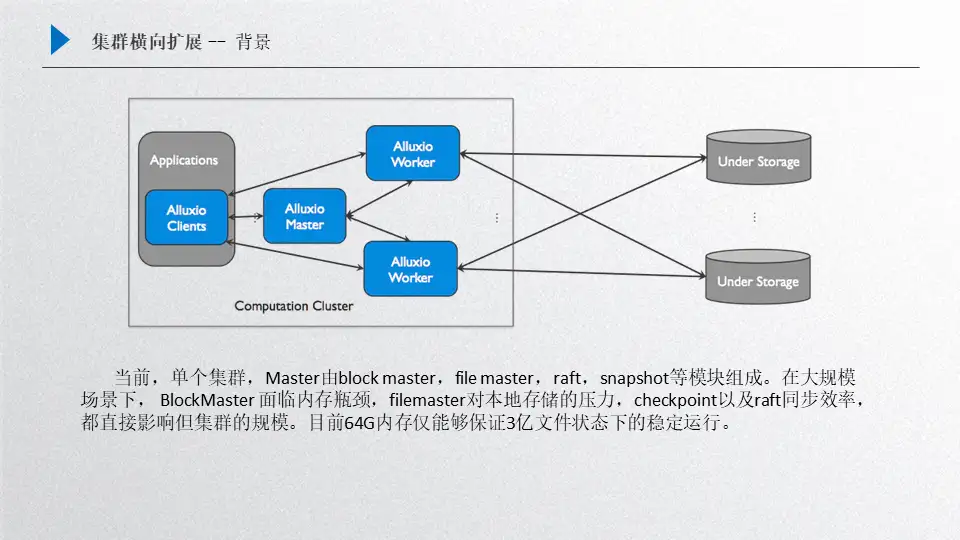
还是Alluxio的框架,master里面主要包含了很多构件元素,第一个就是block master,第二个是file master,另外还有raft和snapshot,这个部分的主要影响因素就是在这四个方面:
- Block master,如果我们是大规模集群创建下,block master面临的瓶颈就是内存,它会侵占掉大量master的内存,主要是保存的worker的block信息;
- File master,主要是保存了inode信息,如果是大规模场景下,对本地存储的压力是非常大的;
- Raft面临的同步效率问题;
- snapshot的效率,如果snapshot的效率跟不上,可以发现后台会积压非常多journal entry,这对性能提升也有一定影响;
做了一些测试之后,在大规模场景下,其实机器规格不是很大的话,也就支持3-6个亿这样的规模,如果想支持10亿甚至上百亿这样的规模,全部靠扩大存储机器的规格是不现实的,因为模型训练的规模可以无限增长,但是机器的规格不可以无限扩充,那么针对这个问题我们是如何优化的呢?
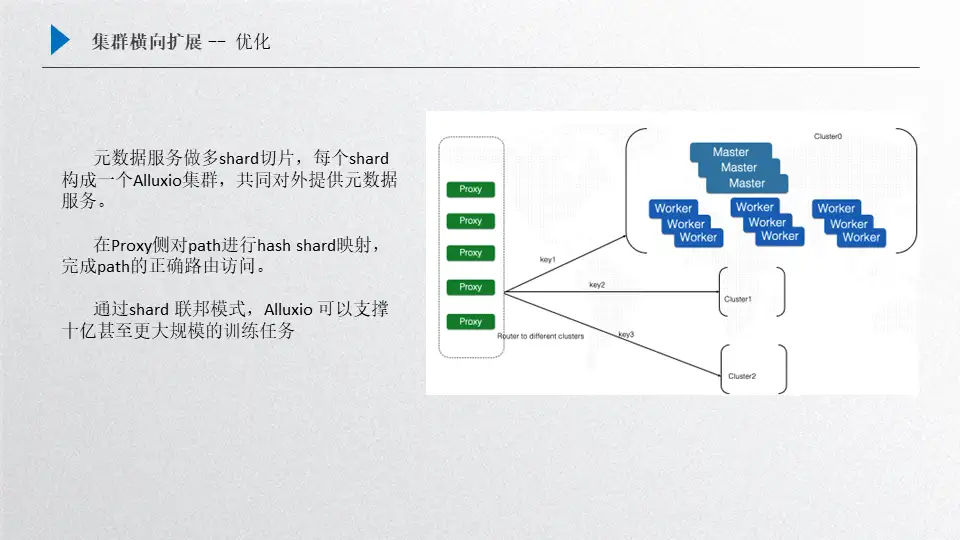
这个优化我们主要借鉴了Redis的实现方案,就是可以在底层对元数据进行分片,然后由多个cluster集群对外提供服务,这样做的一个好处就是对外可以提供一个整体,当然也可以采取不同的优化策略,比如多个集群完全由用户自己去掌控, 把不同的数据分配到每一个集群上,但这样对用户的使用压力就会比较大。先来介绍一下这个框架,首先我们把这个元数据进行一个分片,比如用户拿到的整体数据规模集合比较大,单集群放不下了,这时候会把大规模的数据集合进行一个分片,把元数据进行一些哈希(Hash)映射,把一定hash的值映射到其中某一个shard上,这样cluster这个小集群就只需要去缓存对应部分key对应的文件,这样就可以在集群上面有目标性的进行选择。
那么接下来其他的数据就会留给其他cluster,把全量的hash分配到一个设定的集群规模上,这样就可以通过几个shard把整个大的模型训练文件数量cache下来,对外提供大规模的模型训练,然后我们的前端是增加了proxy,proxy其实内部是维护一张hash映射表的,用户过来的请求其实是通过proxy进行hash的映射查找,然后分配到固定的某一个集群上进行处理,比如过来的一个文件请求通过计算它的hash 映射可以判定hash 映射路由到cluster1上面去,这样其实就可以由cluster1负责,其他key的映射分配到其他cluster上,把数据打散,这样的好处有很多方面:
- 第一是元数据承载能力变大了;
- 第二是把请求的压力分配到多个集群上去,整体的qps能力、集群的吞吐能力都会得到相应的提升;
- 第三是通过这种方案,理论上可以扩展出很多的cluster集群,如果单个集群支持的规模是3-6个亿,那三个集群支持的规模就是9-18亿,如果扩展的更多,对百亿这种规模也可以提供一种支持的解决方案。
以上是我们对模型进行的一些优化。整个的框架包括稳定性的建设、性能的优化和规模的提升。
- 在稳定建设方面:我们可以把整个集群做FO的时间控制在30秒以内,如果再配合一些其他机制,比如client端有一些元数据缓存机制,就可以达到一种用户无感知的条件下进行FO,这种效果其实也是用户最想要的,在他们无感知的情况下,底层做的任何东西都可以恢复,他们的业务训练也不会中断,也不会有感到任何的错误,所以这种方式对用户来说是比较友好的。
- 在性能优化方面:单个集群的吞吐已经形成了三倍以上提升,整个性能也会提升上来,可以支持更大并发的模型训练任务。
- 在模型规模提升方面:模型训练集合越来越大,可以把这种模型训练引入进来,对外提供支持。
在Alluxio引入蚂蚁适配这些优化之后,目前运行下来对各个方向业务的支持效果都是比较明显的。另外目前我们跟开源社区也有很多的合作,社区也给我们提供很多帮助,比如在一些比较着急的问题上,可以给我们提供一些解决方案和帮助,在此我们表示感谢!








