分享专家:丁天宝 Shopee工程师,孙颢宁 Shopee工程师
一、存储现状
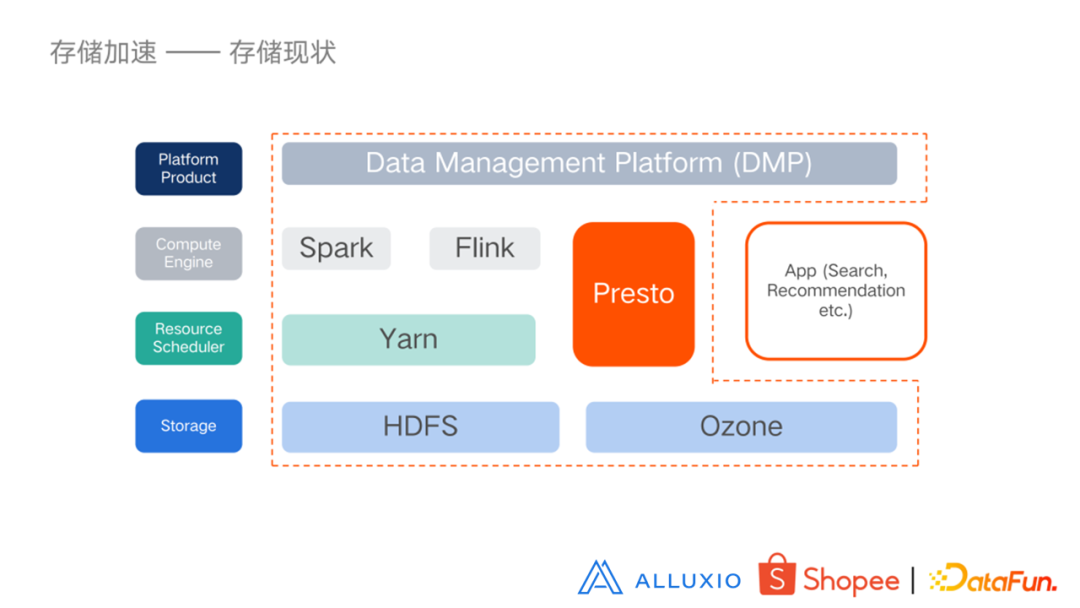
目前虾皮的存储结构从上到下主要分为存储层、调度层、计算引擎层和平台管理层,在引擎层有 Spark、Flink、Presto;调度层有 Yarn;存储主要是 HDFS 和 Ozone,对接存储层的也有一些APP,例如推荐和搜索等等。
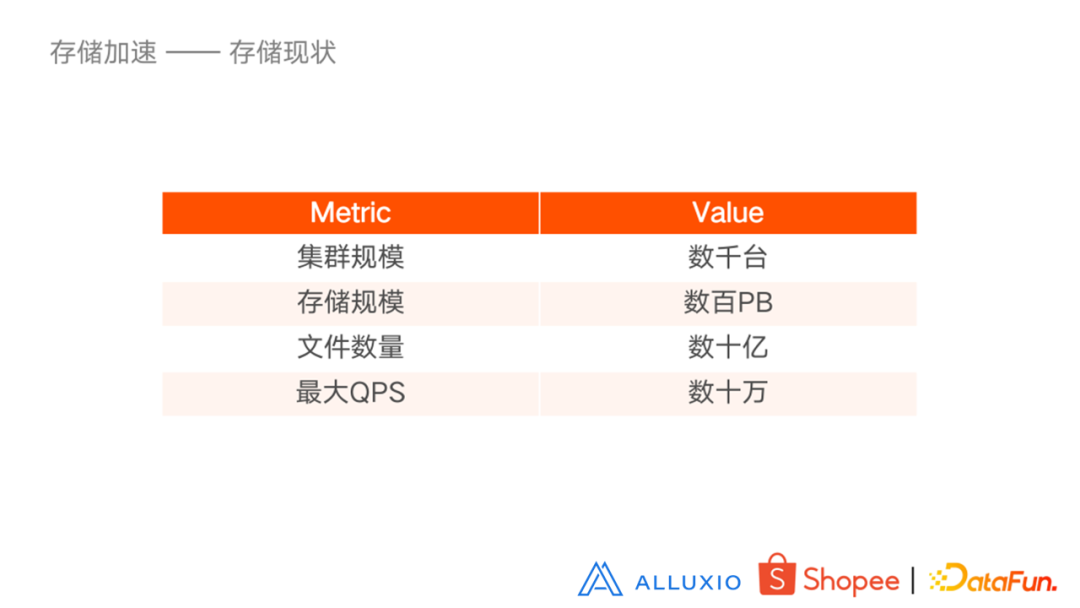
我们的存储集群规模有几千台,存储规模约数百 PB,文件数量约几十亿,最大 QPS 约几十万。
二、存储加速
存储加速部分,主要是针对 Presto,它是我们存储系统的一个使用大户。目前 Presto 的集群规模大概数千实例,TP90 大概两分钟,每天读取文件大概有几十 PB,查询量大概每天数十万。
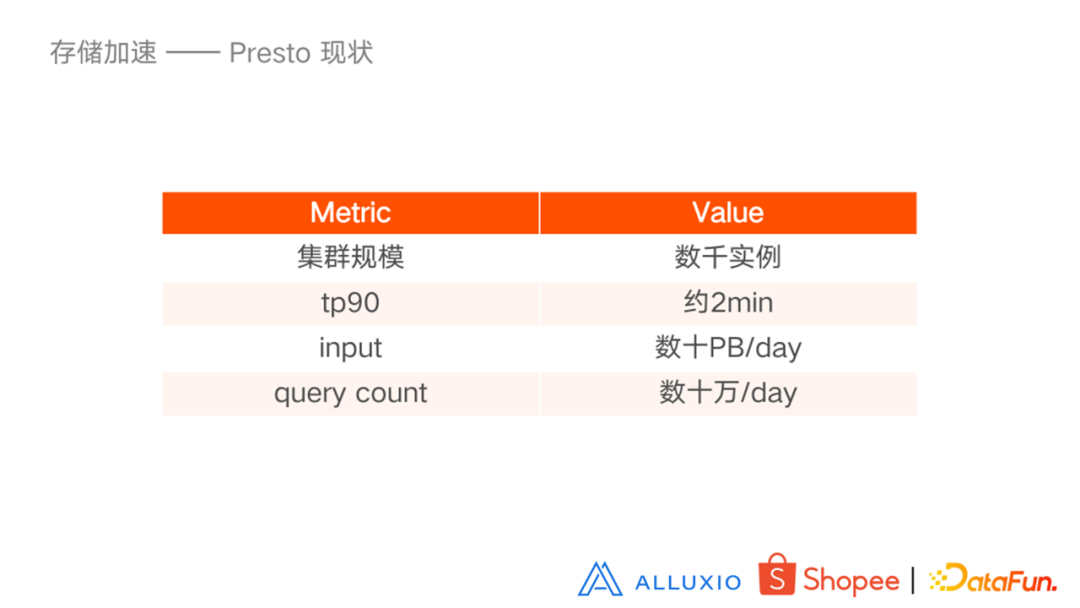
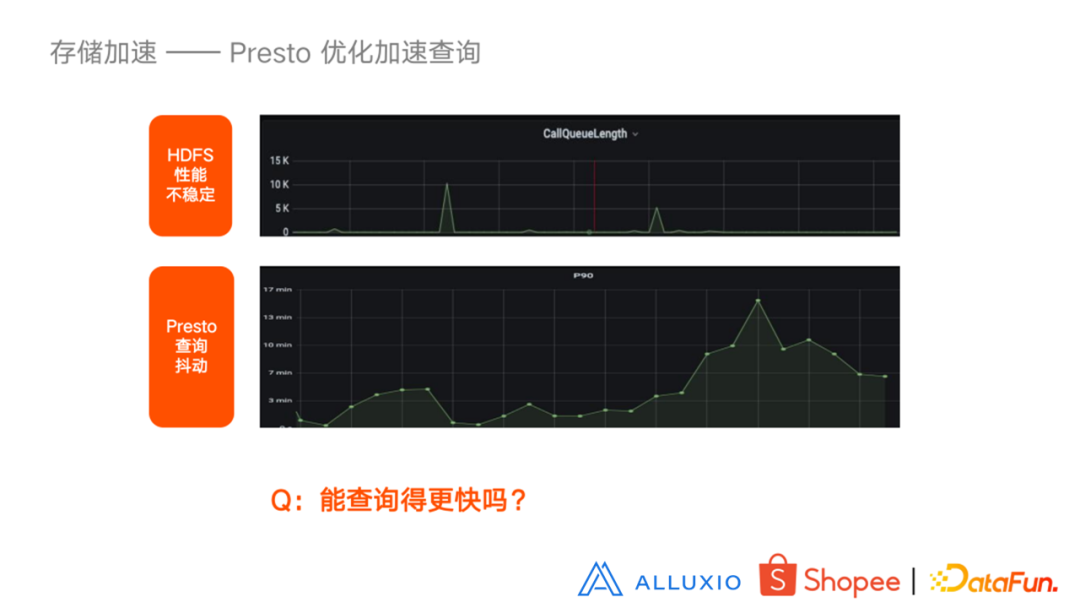
经过长时间的使用发现,HDFS 性能经常不稳定,Presto 的查询也会有抖动现象。所以就产生了既提升查询速度又保证查询稳定性的需求。目前比较主流的改进方式是添加 cache,cache 中比较主流的方式是使用 Alluxio。Alluxio 方案中相对经典的方式是 Presto Worker 和 Alluxio Worker 部署在一起,HDFS 挂载在 Alluxio 目录上,Presto 通过 Alluxio 访问 HDFS,缓存 Alluxio 自己管理。
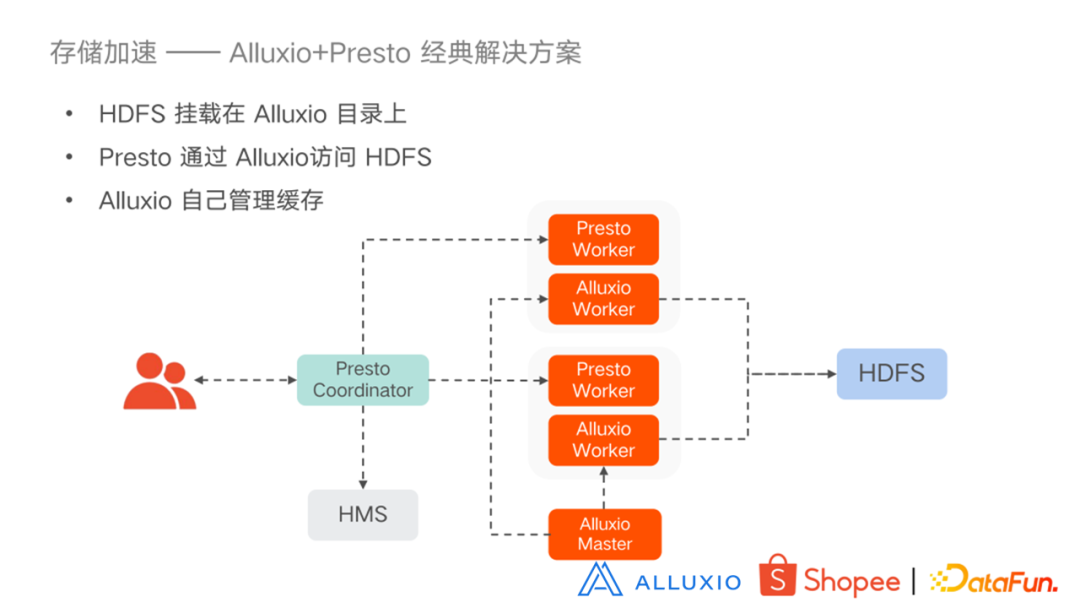
在这种 Alluxio+Presto 经典解决方案中也存在一些问题:
解决方案:
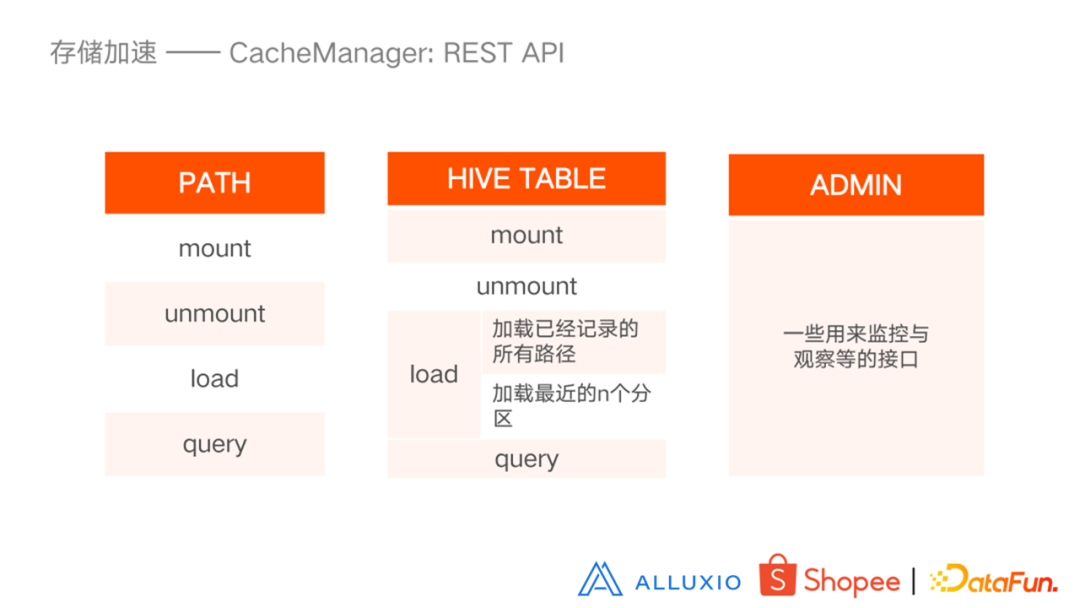
- 对 HMS:设置标志,告诉 Presto 缓存在 Presto 还是在 Alluxio 中;
- 对 Alluxio Worker:设计 Cache Manger,自定义缓存策略,提前加载缓存;
- 有了这个标志以后 Presto 就可以直接去查 HDFS,不需要通过 Alluxio 去中转。
Cache Manager 架构和实现细节
为了解决以上问题,我们设计了一个 Cache Manager 系统。首先来看一下Cache Manager 的整体架构:
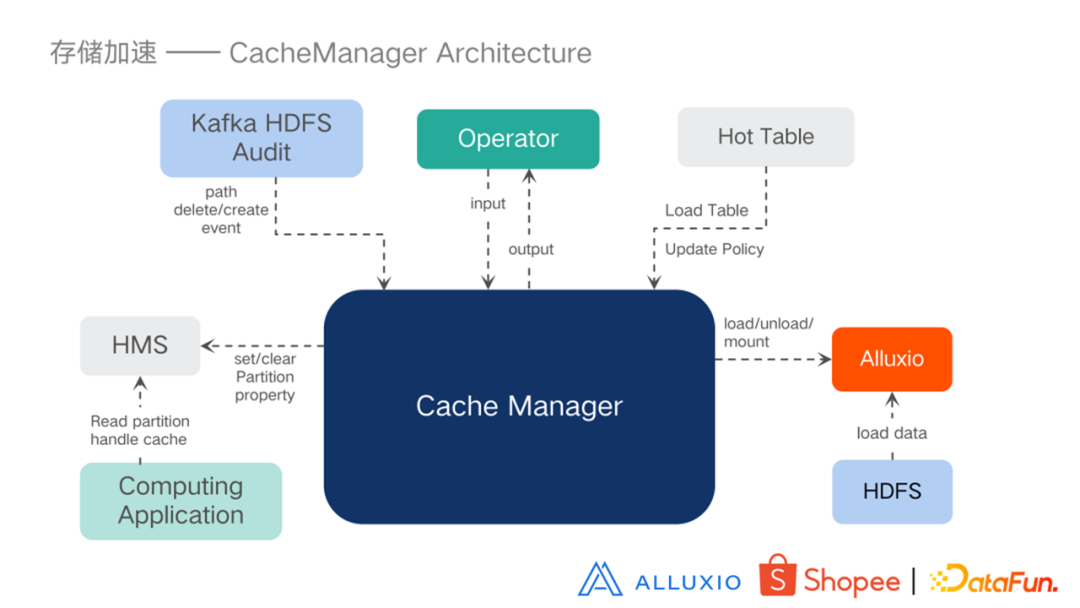
- Cache Manager 通过 load/unload/mount 发给 Alluxio,Alluxio 从HDFS 加载数据;
- 根据一些缓存策略去加载一些热表;
- 提供了一些 API 接口,可以进行一些输入和输出;
- 通过 Kafka 的 HDFS 对已经加载的缓存进行一些修改;
- 在HMS上打一些标志,这样计算引擎就可以从 HMS 得到并从 Alluxio 去加载数据。
接下来看一下 Cache Manager 的一些实现细节。
- 热表:通过 Presto 的查询日志,每天生成的 Hive 表,按日期分区,统计每个表每一天的热度,即访问次数。
- 缓存策略
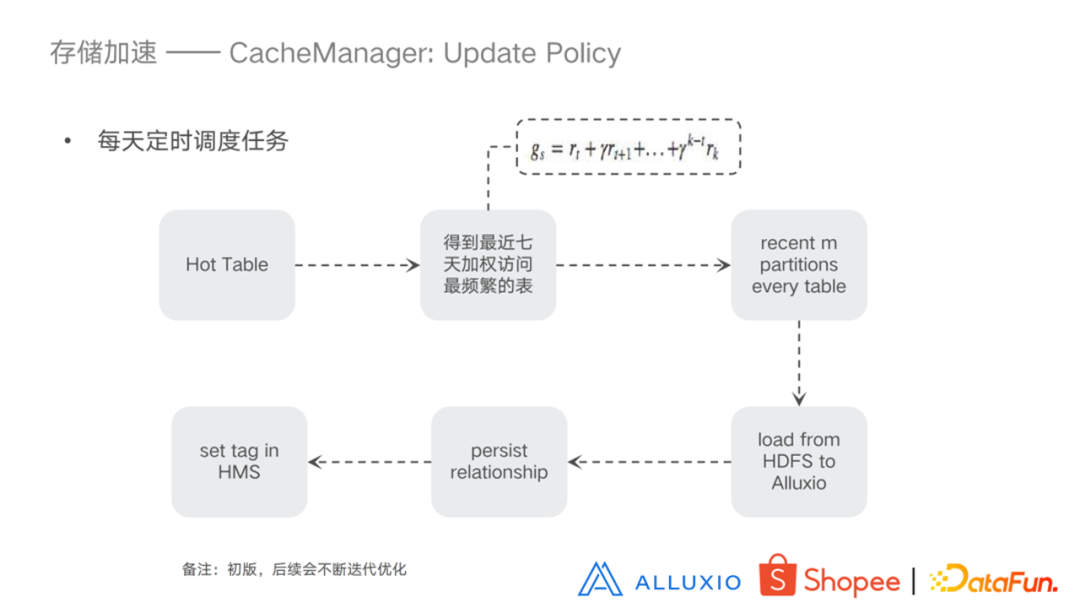
从热表中得到最近七天加权访问最频繁的表,取每个表最近的 m 个分区,把这些分区从 HDFS 加载到 Alluxio 中,把这些关系存储到数据库中,然后在 HMS 设置标志。注意的是,这是一个比较初级的版本,后续会不断迭代优化。
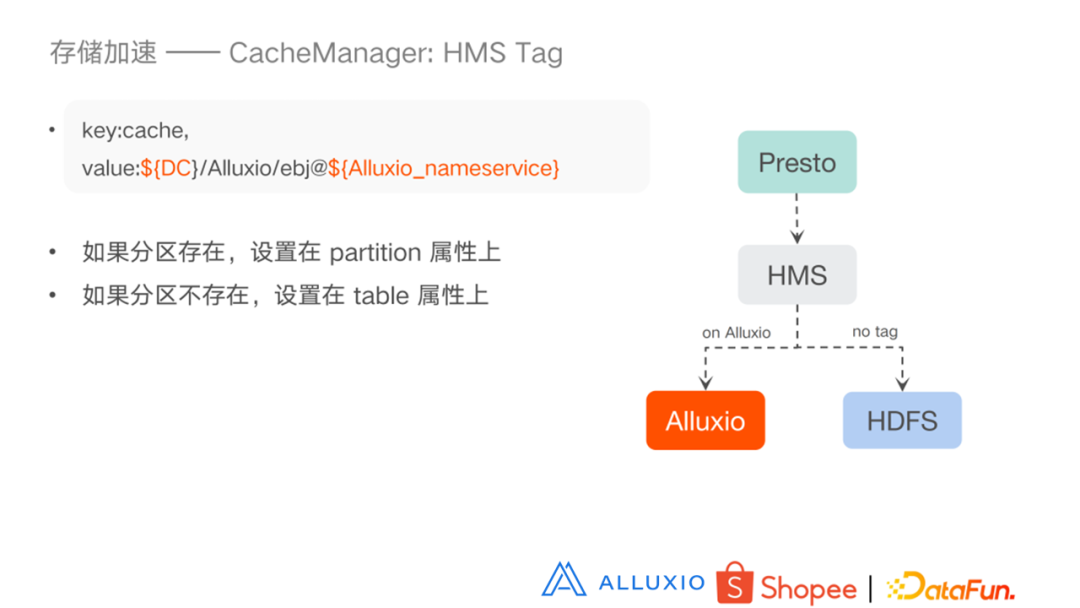
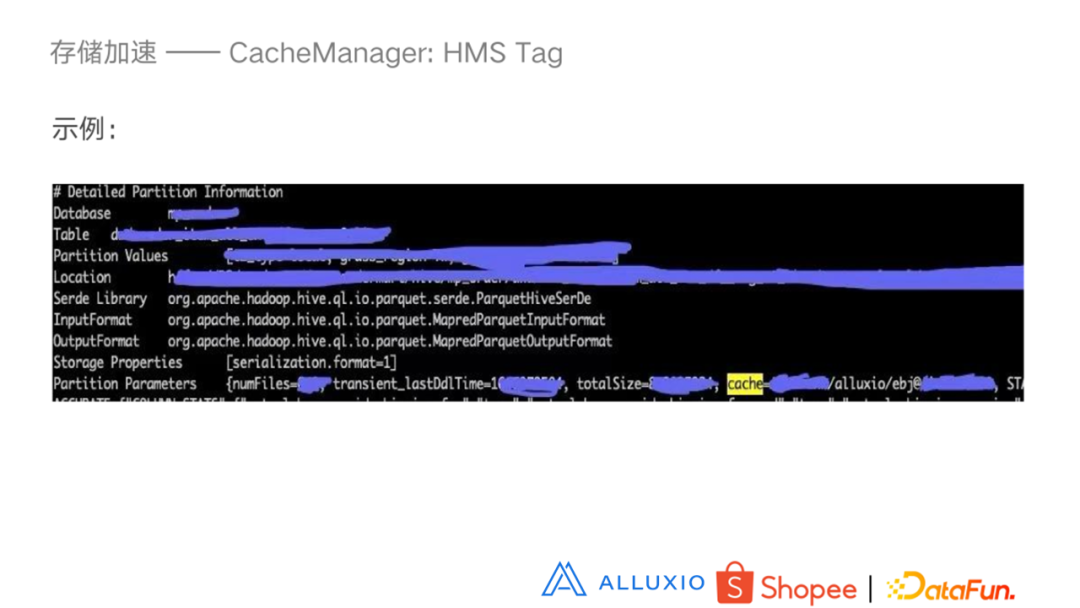
Key 是 Cache,Value 是数据中心,然后是 Alluxio 以及 Alluxio 的NameService,我们会有多种 Alluxio 的服务。如果分区存在,会设置在 partition 属性上,如果分区不存在,则设置在 table 属性上。右图表示的是 Presto 去 HMS 查询,如果在 Alluxio 上就去 Alluxio 查询,如果不在就去 HDFS 查询。
3. 效果展现
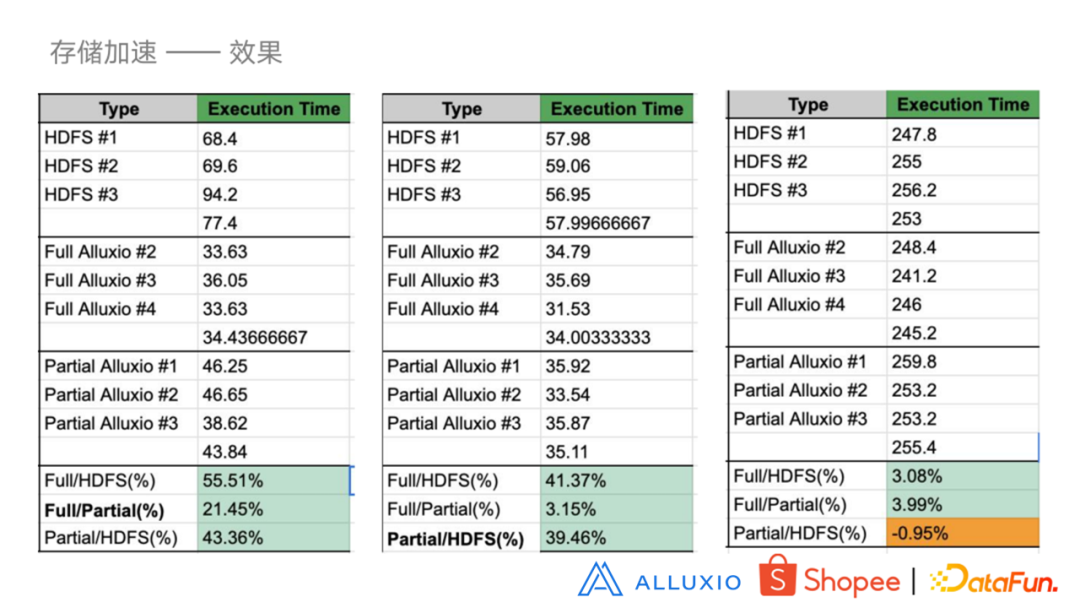
目前 Alluxio 正在上线中,数据采集不完全,但现有的测试数据可以看出全部从 Alluxio 读比全部从 HDFS 查询最高可以达到 55.51% 的提升。
4. Alluxio 社区贡献

三、存储服务化
1. 业务痛点问题
2. 解决方案
为了给业务人员提供更成熟便捷的访问方式,从存储服务化的角度出发,结合我们对 Alluxio 的调研,提供了以下两种解决方案。(1)Fuse for HDFS:在 Fuse 中可以像在本地访问数据一样来访问 HDFS 的数据,我们提供了两种部署模式:物理机部署 Alluxio Fuse 服务,以及 Kubernetes 部署 Alluxio Fuse 服务。(2)S3 for HDFS:通过 S3 API 访问 Alluxio 服务。S3 对多种语言支持,可以解决开发语言差异的问题,同时 Alluxio 对 S3 接口兼容,使用 S3 接口访问 HDFS 中数据非常便捷,我们最终决定采用这种方式来提升用户体验。
3. 了解 Fuse
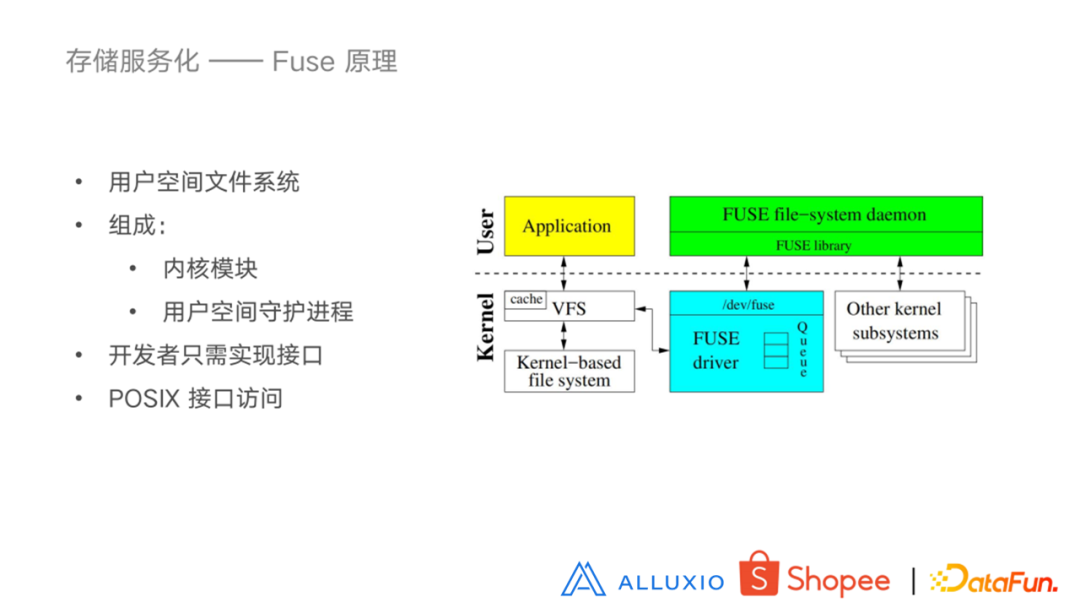
Fuse 属于一个用户态的软件系统,由两部分组成:内核模块以及用户空间守护进程。Fuse 给用户和开发者带来了极大的便利。在内核模块的支持下,开发者只需要实现标准的 POSIX 协议接口就可以拥有一个自定义的文件系统。右边这幅图是一个 Fuse 服务的架构图,当用户在被挂载的目录执行文件操作时,就会触发系统调用,VFS 将这些操作路由至 Fuse driver,Fuse driver 创建请求将其放入到请求队列中,Fuse daemon 通过块设备从内核队列中读取请求,进而执行自定义的逻辑操作。
4. 物理机部署 Alluxio Fuse
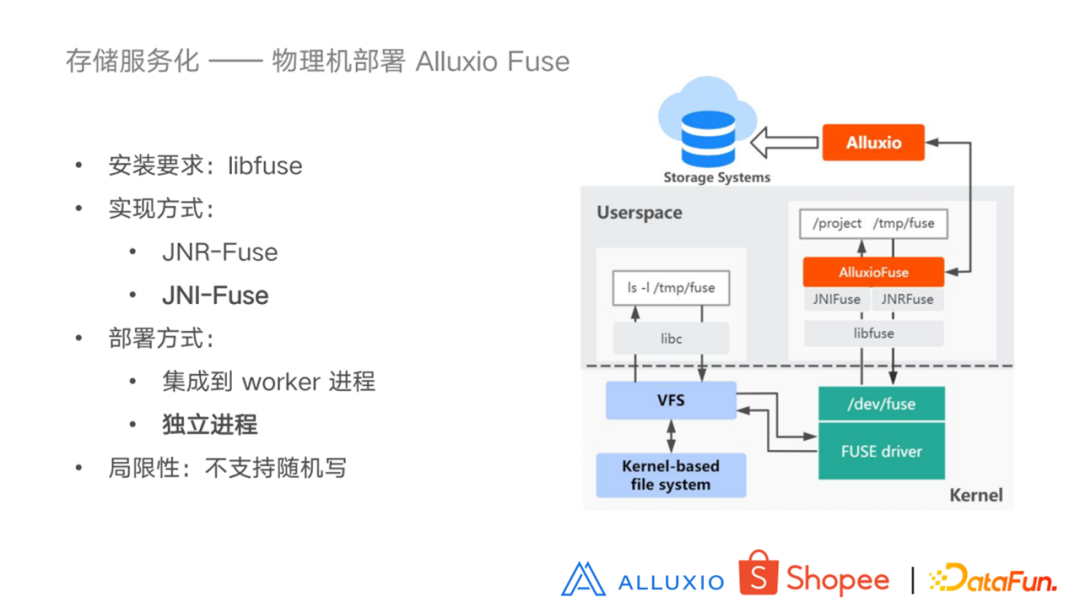
先看一下右边的这幅图,Alluxio Fuse 的服务就相当于前面讲的 Fuse deamon,在启动 Alluxio Fuse 的时候,相当于进行了一个挂载操作,它会调用 libfuse 的方法,向 kernel 去注册挂载点以及回调函数。在挂载目录下执行的操作就是执行的回调函数逻辑,像图中描述的 ls 指令最后得到的结果就是对挂载的 Alluxio 目录执行的list操作的结果。在使用 Alluxio Fuse 之前,我们需要安装 libfuse 。目前社区的版本是支持 libfuse2 的,libfuse3 应该也在开发过程当中。实现方式现在有两种,一个是 JNR-Fuse 一个是 JNI-Fuse。JNR-Fuse 是一个个人维护的项目,所以出现问题的话不一定能够及时地的解决。而 JNI-Fuse 是由 Alluxio 社区来维护的,并且在并发场景下 JNI-Fuse 性能更佳。于是我们选择了 JNI-Fuse 作为我们的实现方式。Alluxio Fuse 有两种部署模式,一种是集成到 worker 进程,这样能够省去 rpc 调用,另一种是单独部署在一个客户机上,目前我们使用的是单独部署的模式,因为我们的用户应用客户端不一定和 worker 在同一个节点,所以选择更为灵活的独立部署模式。
虽然 Alluxio Fuse 支持标准的 POSIX 协议,但是它的重点是提供读服务,因为目前的主要使用场景是加速 AI 训练,这是一个典型的读的场景。对于随机写的支持目前还不够好。而我们的服务化需求可能不单单是读请求,这也是我们后面需要改进的点,以更好地支持用户需求。
5. K8s CSI 部署 Alluxio Fuse
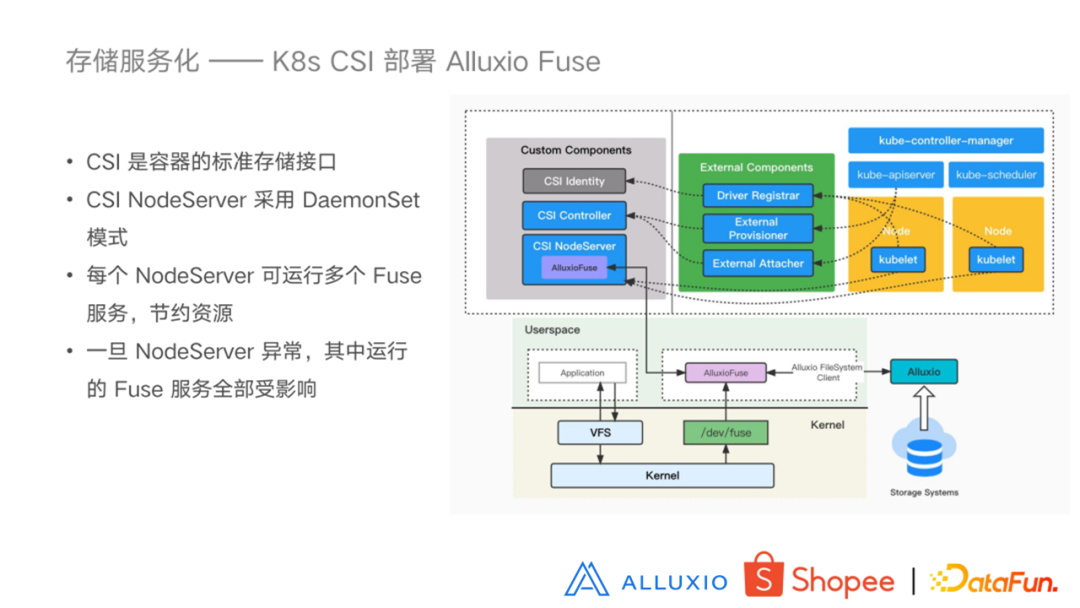
在介绍完物理机部署之后,我们再来看一下如何在 K8s 集群部署。利用 K8s的 CSI 可以将 Alluxio Fuse 服务部署到 K8s 上,CSI 是一个容器的标准存储接口。借助 CSI 的容器编排能力,我们可以将任意的存储系统暴露给容器,从而使用这些存储服务。右边这幅图就是 Alluxio 如何使用 CSI 的原理图。我们可以看到上面部分主要是 CSI 部分, 其中一部分是由 K8s 社区维护的组件(右边部分),而我们更需要关注的是左边需要开发者去定义的部分,主要包括 CSI Controller 和 CSI NodeServer。Controller 作为控制端,实现了创建、删除、挂载、卸载等功能。而 NodeServer 端是进行具体的 mount 操作的节点。在 Alluxio 的 CSI 当中,NodeServer 以 daemonset 模式部署到每个 Node 节点上。要使用定义好的 Alluxio Fuse 的服务,只需用户在定义 PV 时,指定使用 Alluxio CSI 这种服务来提供数据挂载服务就可以,并且需要指定好 Alluxio服务系统中以业务的目录作为挂载点。然后在创建业务 POD 的时候,它就会在 NodeServer上去启动一个 Alluxio Fuse 服务,同时业务 POD 就可以访问挂载在 Alluxio 当中的目录了。这种模式下,一个 NodeServer 上可能会有多个 Fuse 进程,这样能够节约资源。但是它有一个弊端就是一旦这个 NodeServer 出现了异常,那么其中运行的多个 Fuse 服务都会受到影响,与其对应使用这个 Fuse 服务的 Container 都会受到影响,我们必须重启所有的业务 POD 才能正常访问文件。
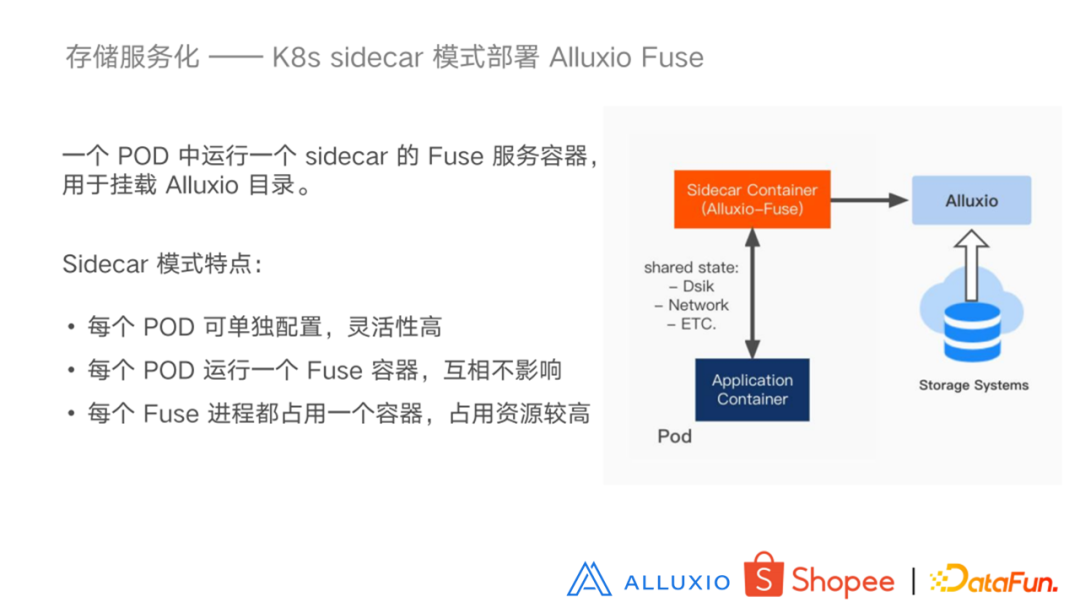
为了避免 NodeServer 挂掉之后产生的影响,我们又引入另外一种模式。就是 K8s 的 sidecar模式,sidecar 模式就是在用户配置业务 Container 的YAML文件中,会配置一个 Alluxio Fuse 的服务。相当于在启动一个业务 Container 的时候,会额外地提供一个 Alluxio Fuse Container 。这个 Alluxio Fuse Container 主要就是用来挂载 Alluxio 目录用的,并且这两个 Container 可以共享存储网络等资源的。这样业务Container 就可以访问Alluxio Fuse挂载的目录。这种模式下每个 POD 都可以有一个 Container,部署配置比较灵活,而且每个容器之间互不影响。但是因为每个 Fuse 进程都会占用一个容器,这样会额外消耗一部分资源。部署模式总结:

简单回顾一下这三种模式的特点:
独立性方面,物理机部署因为采用的是独立部署,不会受 worker 的影响,也不会影响 worker。每个业务使用的 Fuse服务也是互相不影响的。K8S CSI 模式因为是在NodeServer 上可以部署多个 Fuse 进程,所以可能会受到 NodeServer 的影响。K8S sidecar 模式也是独立部署的,不会产生任何影响。
7. 了解 S3
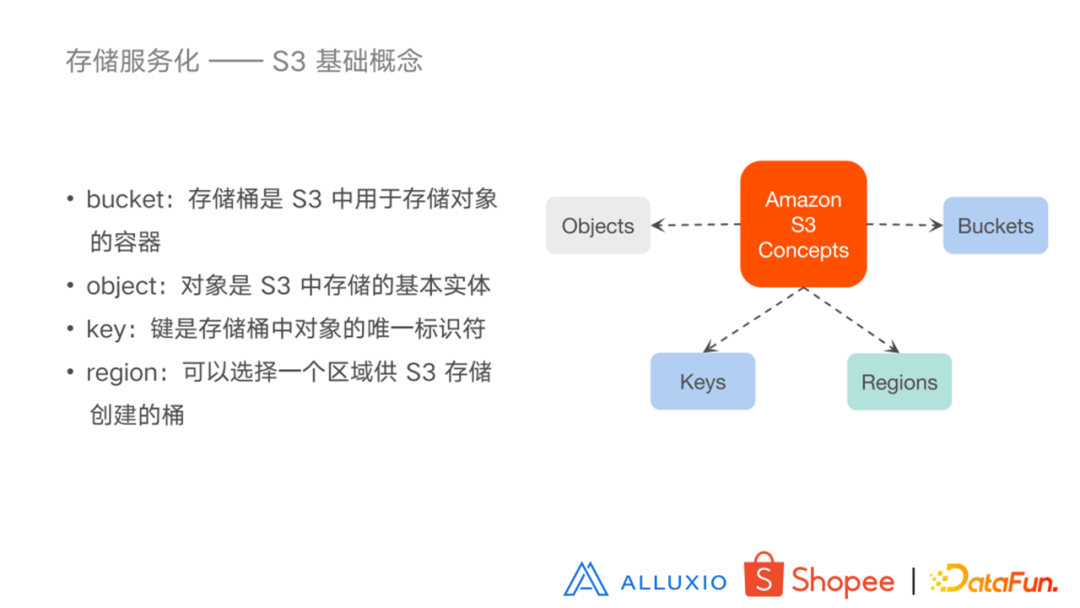
除了挂载操作的方式之外,我们还提供另外一种服务化的方式,就是使用 S3 SDK。S3 是亚马逊的一个公开的云存储服务系统,是存储对象用的。其特点是提供了丰富的客户端 SDK,我们就是要借助这些丰富的 SDK 来实现对 Alluxio 当中文件的访问。在此也介绍一下 S3 的一些基本概念。Bucket 是 S3 中用于存储对象的容器;object 是 S3 中存储的基本实体;Key 是存储桶中对象的唯一标识符;region 在 S3 的服务中可以选择一个区域供 S3 存储创建的桶。下面看一下我们是如何利用 S3 的 SDK 来提供存储服务的 。
8. S3 for HDFS
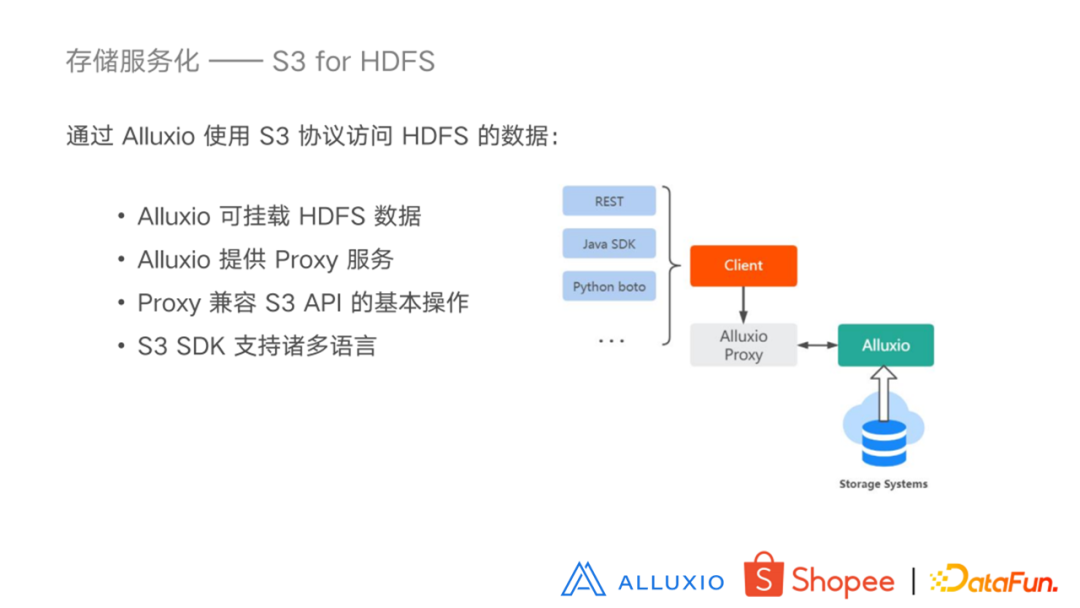
利用 S3 的 SDK 来访问数据主要是依赖于几点:首先 Alluxio可以挂载 HDFS 数据。Alluxio提供了 Proxy 的服务,Proxy 服务是兼容 S3 API 的,所以可以支持更多的用户通过更多的语言,使用 S3 SDK 来通过发送请求到 Alluxio Proxy,解析成对 Alluxio 的请求,从而来访问数据。
9. Proxy 映射关系
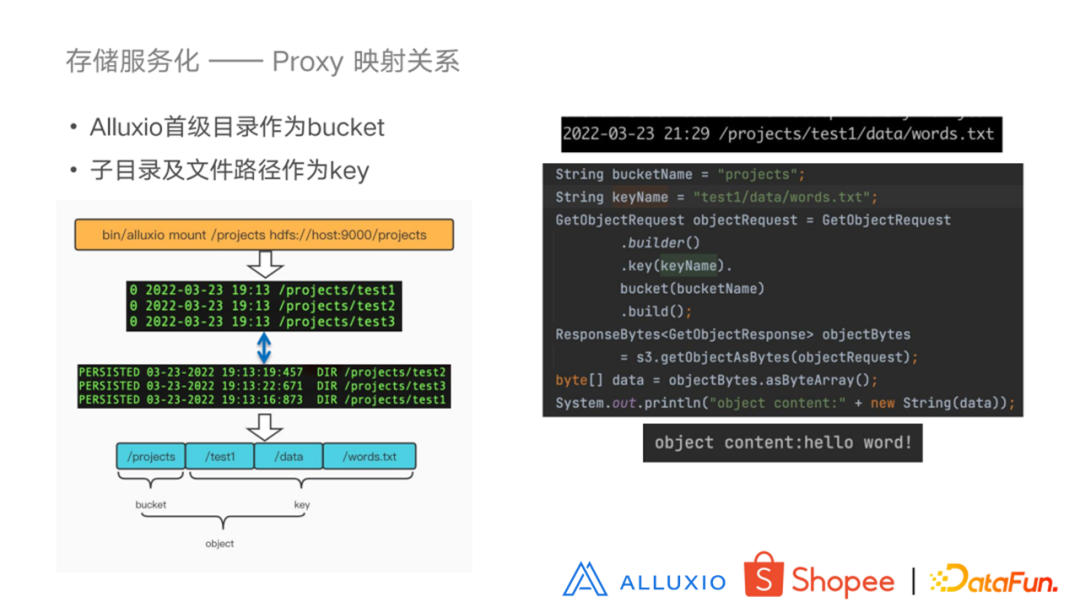
左边这幅图执行的是一个 mount 指令。将 HDFS 当中的 projects 目录挂载到 Alluxio当中的 projects 目录。下边分别是 HDFS 中的路径以及 Alluxio 当中的路径,它们是一一对应的关系。Proxy 服务在做解析的时候,把 Alluxio 的一级目录作为 bucket 来进行映射,其子目录和文件构成 key,相当于通过这个 bucket 和 key 我们就可以得到一个 object 对象。右边的图就是一个 S3 的 Java SDK 请求 Proxy 服务的 demo,可以看到,其bucket设置为首级目录,目录的其余部分作为 key 可以获取到这个对象。
10. 实现 Proxy Authentication
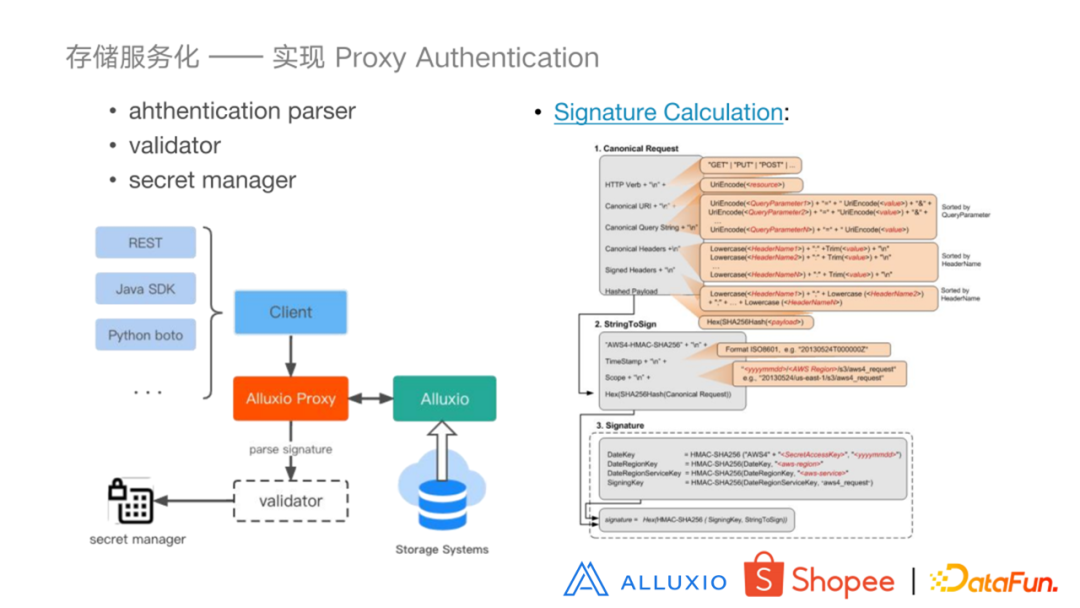
现在社区提供的Proxy服务并没有提供 S3 所具有的认证功能,于是我们自己为 Proxy 服务添加了认证功能。S3 的 SDK 发动请求时,会将请求转换为 REST 请求,并且在客户端根据拿到用户的 ID 以及 secret ,再加上请求当中的请求信息,生成一个签名,然后把这个签名放到请求当中。我们在 Proxy 服务中添加了用于解析认证请求和校验认证的方法。因为在请求中带有 ID 信息,我们可以拿着 ID 去 secret manager 取出它的 secret 信息,重新在 Proxy 服务端生成新的签名,与请求中带来的签名进行比较,从而判断这个认证是否通过。
右图是亚马逊官网给出的计算步骤,我们可以看到它就是解析 request 请求和计算签名的一个过程。使用了加密算法,多次加密之后得到了三个字段,然后进行最后的编码以及加密编码,才得到的这个签名。
11. 服务架构
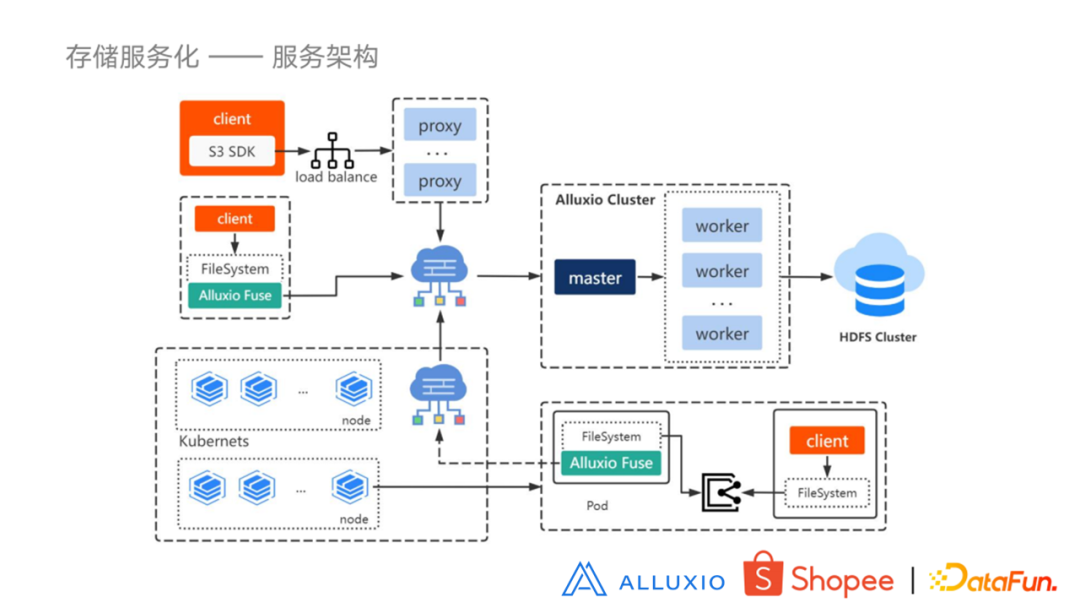
再来看一下我们整个的服务架构。图的右半部分是一个集群,它的后端是HDFS 的数据。我们把刚才介绍到的服务模式都在这个图上进行了展示。可以看到有三个橘黄色客户端,上面是一个使用 S3 的 SDK 的客户端,它通过负载均衡,将请求发送到某个 Proxy 服务,经网络发送到 Alluxio 集群进行解析之后,数据就会返回到客户端。下面这个客户端使用的是在物理机部署的模式,在本地物理机去部署一个 Alluxio Fuse ,用户通过访问 Alluxio Fuse 挂载的目录,进而获取到 Alluxio 当中的数据。最下边是一个 K8s 集群。右边是集群里的一个 pod。这是一个 sidecar 模式,一个客户端和 Alluxio Fuse 的 Container,它们之间共享存储。因为 K8s 是有自己的网络服务定义的,通过这个网络连接到外边的网络服务,进而可以拿到 Alluxio 中的数据。
12. Alluxio 社区贡献

我们在使用 Alluxio 服务的过程中也发现了一些问题,并积极地反馈给了社区,主要是 proxy 与 fuse 相关的问题。
四、未来规划

未来规划主要在以下两大方面:









