关于Dyna Robotics:真实世界的具身智能 (Embodied AI)
Dyna Robotics 致力于开发能够直接从物理交互中学习的具身智能系统 。与在合成模拟环境中训练的模型不同,Dyna Robotics的模型构建于真实世界的演示数据之上——涵盖了机器人叠毛巾、处理纺织品以及在生产环境中执行精细操作等任务 。
每一次机器人作业都会生成同步的多路视频和高频关节遥测数据,并封装为 HDF5 (H5) 轨迹文件 。在规模化生产中,这套系统每天都会产生数万个新文件和数十TB的崭新训练数据。
面临挑战:架构连续性与训练性能的博弈
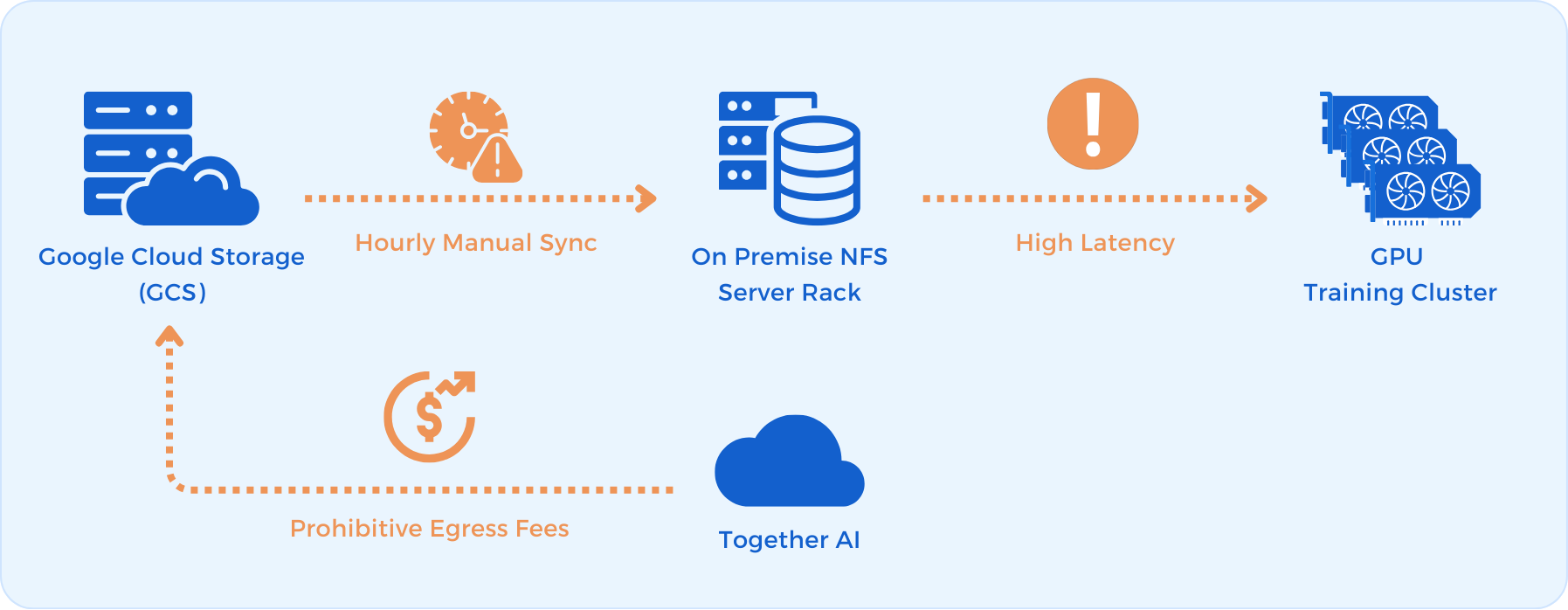
随着 Dyna Robotics 不断扩大其 GPU 集群规模(由 NVIDIA H100 组成),训练任务开始给对象存储访问路径造成巨大压力 :
- 元数据瓶颈:每次训练启动时可能需要检索 10,000 到 100,000 个文件,这种元数据检查加上大量小对象的并发读取,会成倍放大延迟;
- I/O 性能受限:即使在训练代码中加入了预取逻辑,直接从对象存储读取数据依然拖慢了训练速度 ;
为了弥补性能,团队曾引入自建 NFS 层,将数据集从 GCS(谷歌云存储)复制到 NFS 服务器上,以期改善数据访问的本地性。但该办法带来了新的运维挑战:
- 每块持久化磁盘容量被限制在 64TB;
- 数据需要人工分片到不同的服务器上;
- 随着并发训练任务增加,带宽争用导致周期性速度下降——在高并发时,性能降幅有时接近 30%。
- 数据集的生命周期管理变成了基础设施团队的一项额外负担。
核心诉求:打破数据与算力的耦合
最根本的问题是来自于架构上的强耦合:要扩展计算能力,就必须跟着调整存储架构。
Dyna Robotics 意识到他们需要的不是另一个存储系统,而是一个能打通现有 GCS(Google Cloud Storage)数据管道与高性能计算节点的统一数据访问层 。
为了解决这些问题,Dyna Robotics 制定了清晰的架构要求:他们希望利用 GPU 实例上自带、但往往闲置的本地 NVMe SSD,更倾向于采用纯软件的缓存方案,而不是引入额外的存储硬件。同时,GPU 服务器可能会因为各种原因被终止或崩溃——在 GCP 上有时会提前通知,但在其他云平台上可能毫无征兆。因此,任何解决方案都必须能容忍频繁的节点变动,不能将数据的可用性绑定在单个 GPU 实例上。
基于这些考量,Dyna Robotics 最初自己尝试为每个节点实现 SSD 缓存逻辑。但很快发现,将每台机器视为一个独立的缓存孤岛,会导致利用率低下,并且数据在多个节点间重复存储。他们也评估了像 Lustre 这样的集群文件系统,但为了避免完整的数据迁移,并将运维风险降到最低,最终更倾向于分布式缓存架构。
第一步:引入 Alluxio 透明缓存层
Dyna Robotics 将 Alluxio 直接部署在了他们的 GPU 节点上,作为一个分布式缓存层。Alluxio 的“缓存池”模式解决了上述问题——它将单个节点上的 SSD 整合成一个协同工作的统一存储层。由于 Alluxio 作为位于对象存储前方的缓存层,如需要,Dyna Robotics 也保留了回退(fall back)到直接访问对象存储的能力,这相比于采用完全托管的集群文件系统,大大降低了运维风险。
1. 透明集成,无缝衔接
至关重要的一点是,GCS 依然作为数据的最终存储系统。从“机器人 → GCS → 数据处理”的整个流程完全不变。Alluxio 只是向训练代码提供了一个标准的 POSIX 文件系统接口。对于研究人员来说,训练数据的读取路径和以前一模一样;但在架构层面,整个集群却获得了近乎本地读写的性能。
2. 汇聚本地 SSD,构建全局缓存池
在一个典型部署中,Dyna Robotics 运行着 16 个 NVIDIA H100 GPU 实例,每个实例都带有 6TB 的本地 SSD。他们为每个节点划出 5.5TB 空间给 Alluxio,从而构建了一个高达 88TB 的分布式缓存池。这和他们之前低效的“单节点缓存”设计完全不同,Alluxio 将这些孤立的磁盘转变为一个协调一致的数据层,能够自动保留热数据,并基于 LRU(最近最少使用)算法进行缓存淘汰。
第二步:实现跨云 GPU 的无缝迁移
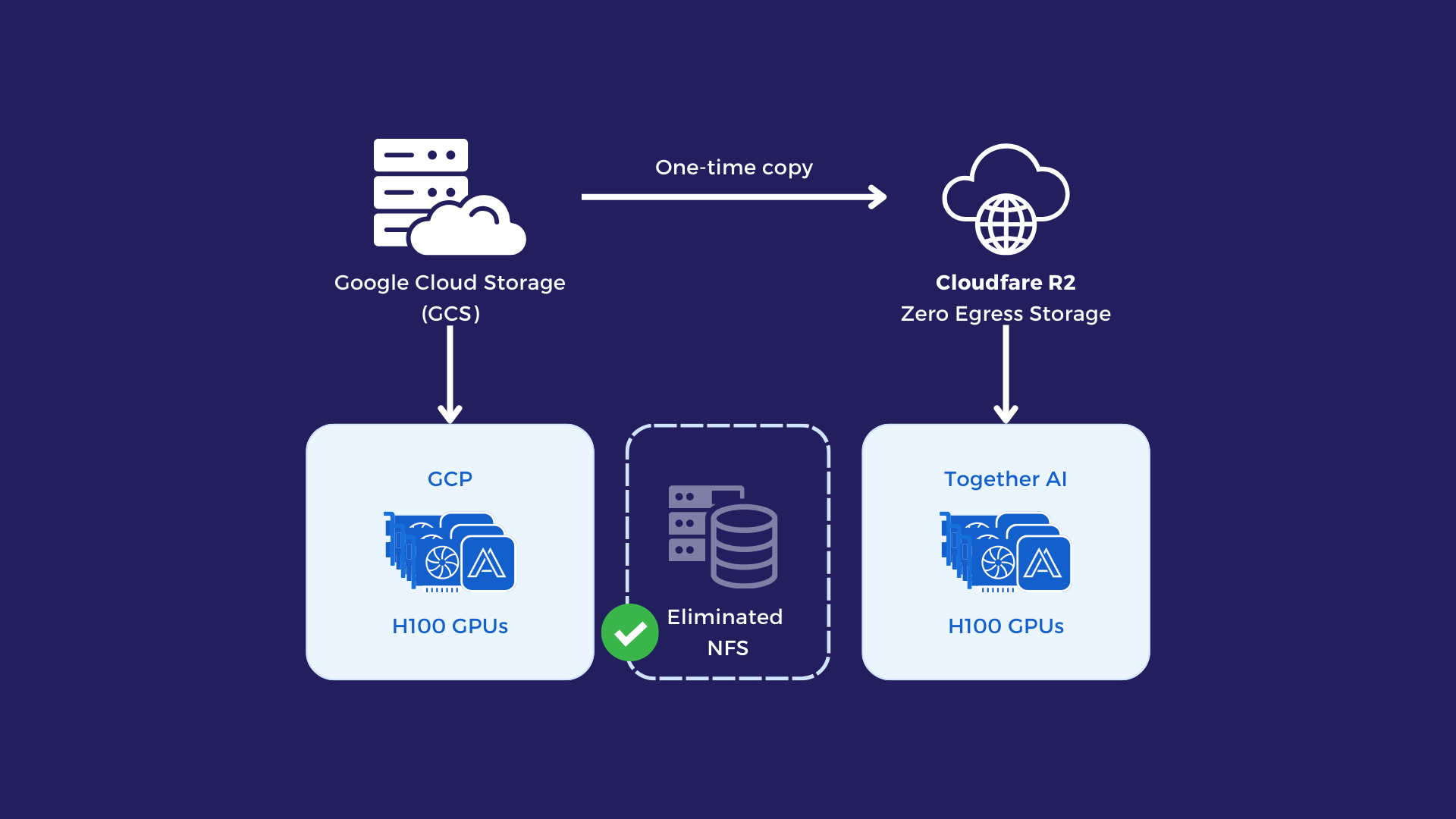
随着对 GPU 需求的增长,Dyna Robotics 开始使用 Together AI 平台。这带来了一个严峻的跨云挑战:如果跨越云边界从 GCS 读取训练数据,将产生大约每 TB 88 美元的数据流出费用(egress fee)。
为了避免这笔重复发生的跨云费用产生,Dyna Robotics 引入了一个中立的对象存储层:Cloudflare R2。虽然相比同在一个云环境内的 GCS,R2 的延迟更高,但 Alluxio 的分布式缓存能很好地弥合这部分差距——一旦数据集被“预热”加载到缓存中,训练任务将能保持稳定的吞吐量。
架构因此演变为:
- 处理好的训练数据依然写入 GCS;
- 新的数据集只需复制一份到 R2;
- 无论是在 GCP 还是 Together AI 上的 GPU 集群,都通过 Alluxio 读取数据;
- R2 的“零数据流出费用”模式,彻底消除了重复的跨云数据传输成本。
最关键的是,训练代码无需任何修改。在一个环境中,Alluxio 从 GCS 读取;在另一个环境中,它从 R2 读取。对于上层的应用程序来说,访问接口是完全一致的。这种抽象层设计,成功地将计算与存储位置解耦。
最终结果是,Dyna Robotics 现在可以根据不同云平台提供的最佳 GPU 可用性或价格,来灵活地分配训练任务——完全不需要重写工作流、重新导入数据集,或者调整存储格式,实现存储层面保持不变,而计算层面则变得可以自由迁移。
除了主要的训练数据集,Dyna Robotics 还有一个专门用于存放实验性数据或研究人员生成数据的共享存储桶。这个存储桶也通过 Alluxio 挂载到了两个云环境中。
当一位研究人员上传数据到这个共享位置时,数据在所有环境中都会立即可见。Alluxio 负责在每个集群本地进行缓存管理。而对象存储的凭证则集中在 Alluxio 的管理节点进行管理,无需再分发密钥到每一个 GPU 节点。
这种设计不仅简化了运维,还减少了安全风险,避免了凭证的泛滥。
生产环境下的运维与优化
- Slurm 与 Docker 自动化集成:Dyna Robotics 的运行环境是 Slurm,而非 Kubernetes。他们将 Alluxio worker 作为 Docker 容器来部署。通过自定义的启动脚本,可以在检测到机器重启后自动重新填充缓存,从而在这个动态变化的环境中保持高可用性;
- 元数据访问优化:由于训练任务启动时需要检查多达 10万个文件的状态,Dyna Robotics 对元数据访问进行了优化:改为检查目录级别的状态,并引入应用级的 Memcached 层来减少任务的“冷启动”时间;
- 安全的数据共享:对象存储凭证集中在 Alluxio 管理节点管理。研究人员可以通过一个独立的共享存储桶来分享实验数据,Alluxio 让这些数据在云之间立即可见,同时避免了将敏感密钥分发到每个 GPU 节点。
总结
通过部署 Alluxio 作为统一的数据平面,Dyna Robotics 在性能、运维和战略层面都获得了显著的提升:
- 训练延迟缩短 30% 以上:移除了在高并发下曾导致性能衰退的周期性 I/O 瓶颈,确保了稳定、以计算为核心的训练吞吐量;
- 大幅降低运维复杂度:告别了受限于 64TB 磁盘的手动数据集导入和分片工作,减少了 NFS 的管理开销,并实现了存储凭证的集中处理;
- 构建真正的多云 GPU 架构:成功将存储与计算解耦,使得工作负载可以在 GCP 和 Together AI 之间无缝切换,而无需重新导入或重构数据集;
- 打造高容错的数据层:保留了在必要时回退到对象存储的能力,与需要完整数据迁移的集群文件系统方案相比,大幅降低了运维风险。
最终,Dyna Robotics 成功将其基础设施,从一个受存储瓶颈限制的数据管道,转变为一个可扩展、可移植的 AI 数据平台。这使得整个团队能够将精力更专注于推进具身 AI 的核心技术,而不是疲于应对复杂的数据移动和管理工作。








