活动回顾
2021 Alluxio Day V 系列活动中,来自Boss直聘的基础架构工程师周佩洁,为我们介绍讲述了Alluxio在容器云k8s平台的建设实践。
周佩洁—Boss直聘基础架构工程师
毕业于东北大学软件工程专业,曾负责离线实时数仓建设,及基于flink的实时计算平台建设,目前主要致力于大数据组件在云平台的落地,组件内核优化及大数据组件与AI生态系统的混合建设。
Hello大家好,我是来自BOSS直聘的基础架构工程师周佩洁。主要负责BOSS直聘算法平台的数据流链路的架构和设计。下面由我介绍Alluxio+Fluid在BOSS直聘算法平台的落地实践,我们本期的分享主要分为以下几个内容:
首先,我会介绍一下Alluxio在我们这边使用的背景,另外我会介绍一下我们在使用过程中遇到的挑战。再之后我会介绍我们的整个架构设计,最后我会介绍一下使用Fluid管理Alluxio在k8s集群上的落地,以及我们实现的Alluxio在k8s集群上的动态扩缩容的实践。
Part 1 Alluxio使用背景
Arsenal深度学习平台是一个集数据预处理,大规模分布式训练,模型优化,模型在线推理等多位一体的一站式算法平台,我们也一直致力于打造更高效的一体化算法链路,这其中也包括数据部分的建设和加速,Alluxio正是作为训练链路加速的一个重要组件而被引入到算法平台中来的。在模型训练之前,我们会使用spark将训练数据从其他异构数据源加载到算法平台的ceph中,作为模型的训练数据,数据的导入速度直接决定了日更模型的上线速度。 这里就会有一个问题,如何更快,更稳定地将训练数据导入到算法平台的环境中以便于快速地进行后续的训练。
Part 2 主要挑战
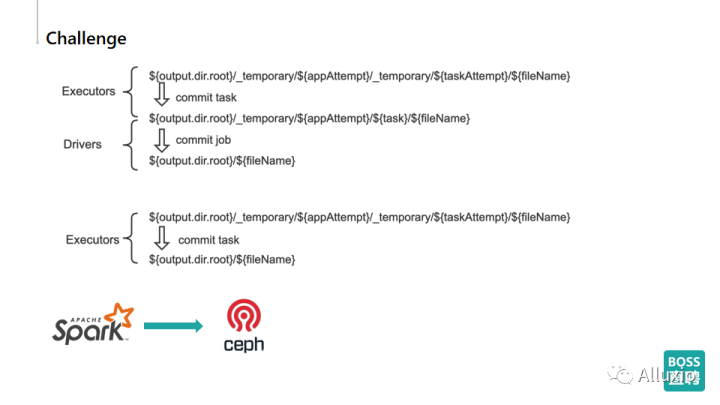
我们发现,我们使用Spark在进行算法平台数据导入的过程中,Spark本身的文件在写入的时候,为了保证一致性,做了一个两段式或者三段式的提交协议,比如在 spark v1版本的提交协议中,在Spark写入的时候,会创建一个双重的temporary的目录,在commit task的时候会将目录移到外层,然后在driver commit job的时候再往最外层移动到我们实际的目录里,那在v2的Spark版本的提交协议里面,它也是会最开始写两层temporary目录,最后会把这个目录移到最外层。
其实v1和v2版本在Spark写入ceph都有一些问题是无法规避的,主要就是ceph并不像文件系统一样可以直接进行rename的操作,对ceph来说rename意味着数据的迁移,也就是如果我把3个TB的数据写入到ceph里,那实际上在我移动目录的时候,ceph的worker节点会出现3TB*n(n按照spark v1,v2的提交协议会有不同的值)的大规模的数据传输。这样不但会给ceph整个集群带来比较大的网络负载,同时也会使整个ceph集群处于一个极度不稳定的状态。

除了这样一个问题外,我们在原有的架构Spark写入ceph的过程中还发现了一些其他的问题:
① 比如说没有办法做流量的控制,因为Spark是以比较快的速度对ceph进行写入的,如果在没有流量控制的情况下,就会导致整个集群的稳定性受到影响。
② 另外我们的算法平台主要是支持多种的大数据处理框架,比如说Spark/Flink/Ppresto等等,同时也会支持多种的机器学习和深度学习的框架,比如说TensorFlow,PyTorch和其他用户自研的学习框架,这个时候我们就缺乏一套统一的数据读取和数据写入的API。
③ 使用ceph大集群,我们也没有办法很好的做到网络隔离以及读写隔离。网络隔离的话,比如说我们的ceph可能是一个n个节点的ceph,那在写入的时候就会遇到一个系统瓶颈,这个瓶颈在于这个n台ceph节点的网络带宽是多少,比如说有一个用户的写入任务把ceph的网络带宽或者磁盘的IOPS全部打满,这个时候就会影响其他用户的读写和写入。
④ 如何从一个大集群里为不同用户拆分权限和容量也成了一个比较困哪的问题。
⑤ 我们希望数据可以尽快地进入到算法平台的环境用于训练,但是对存储底层的组件来说,我们希望可以有流控,而流控和写入速度本身就是相互矛盾的指标。
因此我们就引入了Alluxio来解决这样的一些问题。
Part 3 架构设计
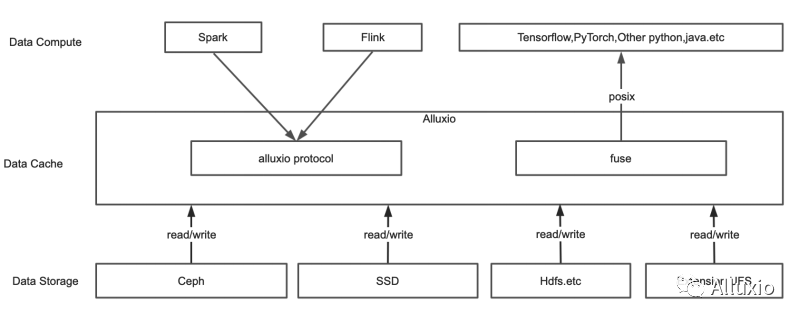
现在大家看到的就是我们调整之后的架构,我们会把整个的数据算法平台的数据层分成三层:
① 最上层是我们的数据计算层,这部分我们使用Spark和Flink框架,把数据从异构的数据源写入到我们的算法平台,然后数据计算层其他的,比如说像TensorFlow,PyTorch或者是其他的计算框架,会通过Alluxio的fuse从我们的缓存层读取数据;
② 缓存层我们主要是使用Alluxio进行实现,然后对同名的读取API进行了封装。
③ 最下层是我们算法平台的数据存储层,包括ceph,TiDB等等。
使用这样的模式就解决了我刚才提到的一些问题。
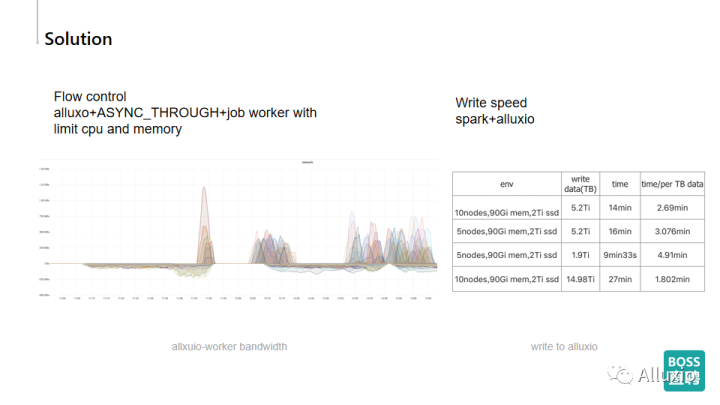
首先就是一个流控的问题,在流控部分的话,我们使用了Alluxio去进行数据的缓冲,通过控制Alluxio的job worker使用限制的CPU和内存,异步写的方式对写入到ceph的流量进行了有效的限制。
如上图所示,我们可以看到上侧是进入到Alluxio的流量,下侧是Alluxio写到ceph的流量,我们可以看到这里有比较明显的限流,写入到ceph的数据流速是一个比较稳定的状态,这样可以最大程度保证ceph集群的稳定性。
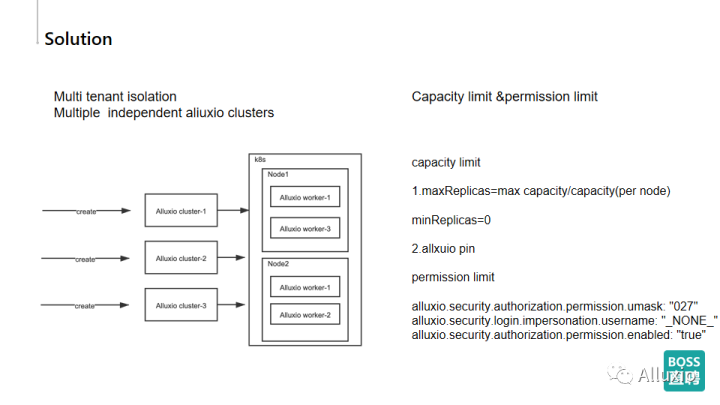
我们说到了ceph具有稳定性,它是一个大集群,对于多个组的用于算法训练的同学,它的使用并不是友好的,所以我们在k8s集群里会根据用户的需求搭建多种独立的Alluxio的小集群,而CNCF的Sandbox项目Fluid中Dataset和Runtime的抽象正好和我们的初衷不谋而合。
我们按照用户的需求去创建Alluxio cluster的集群,并且在k8s上的同一个节点会部署不同集群的不同worker,用于spark写入数据到Alluxio,以及Alluxio同步数据到ceph里,这样就可以最大限度的保证用户想要的容量和权限的限制。权限限制的话,我们统一在Alluxio上进行了控制,并对一部分权限源码进行了改造。容量部分我们使用Fluid结合k8s HPA实现,后续会在HPA里详细的讲到。
Part 4 Alluxio在k8s上的实践
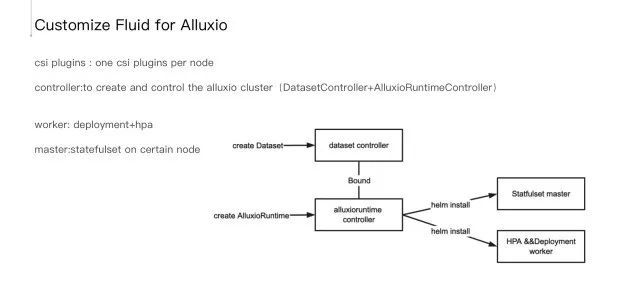
下面我主要介绍一下使用Fluid在k8s管理Alluxio集群生命周期的实践,首先我们会有一些相应的pod固定地部署在k8s集群里用于allxuio集群的部分调度和管理,我们使用Fluid在集群中创建了一个dataset controller和一个AlluxioRuntime controller,并对Fluid的调度层和Csi Plugin部分进行了二次开发,新增了Fluid HPA动态扩缩容逻辑。当用户尝试去创建一个Alluxio集群的时候,我们会创建AlluxioRuntime CR, AlluxioRuntime controller在接收到这个 CR之后,会对alluxio values进行渲染,并通过helm install安装alluxio的 master和worker节点,同时我们为了实现Alluxio每一个小集群在k8s上的动态扩缩容和调度,我们将原Alluxio的worker的DaemonSet更改为Deployment,并在上面嵌套了k8s HPA。 另外在k8s集群的每一个节点上,我们都部署了一个csi plugin,主要是用于当Tensorflow作业或者是PyTorch的作业读取Alluxio数据的时候,使用csi plugin做远程挂载。
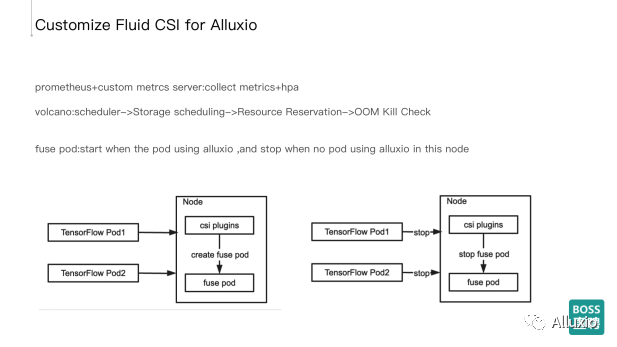
下面的两张图主要介绍了csi plugin以及训练作业在进行挂载时的处理流程。我们的TensorFlow或者PyTorch去使用这个数据集的时候,我们会动态为TensorFlow的pod或者是PyTorch的pod里默认地去绑定Alluxio的pvc。
当TensorFlow pod被调度到集群的某一个节点的时候,csi plugin会相应的去调用NodeStageVolume和NodePublishVolume,然后去动态地创建Alluxio fuse pod, fuse pod会建立Alluxio集群的远程连接,从而去开始一个训练。在发稿时,这种Lazy启动的能力Fluid也已经支持了。比如说我们有第二个训练, 被调到这个节点上之后,我们将会复用这个已经创建的fuse pod。当这个节点上没有任何使用Alluxio集群的训练任务的时候,csi plugin会尝试去把fuse停掉,我们通过这样的方式就保证了多个alluxio集群和训练节点在k8s集群调度最大的可控性以及灵活性。
为了实现Alluxio集群在k8s上的动态扩缩容,我们还引入了一些其他的组件,首先我们引入了prometheus,对整个Alluxio以及Alluxio相关的指标进行了采集,作为HPA的判断条件,在调度层面上我们通过二次开发引进了volcano调度器,定制了我们内部的磁盘调度逻辑,资源的预留逻辑以及OOM Kill pervent,在fuse的调度流程里,比如TensorFlow pod可能使用的是20个GB的一个存储,fuse本身也需要10GB的存储,所以我们使用volcano为这个节点进行一部分的资源预留。

在下面这个PPT里面,我们主要说一下使用Alluxio集群动态扩缩容的一些指标,以及具体的HPA。如上图所示左侧,我们可以看到有一些指标,指标来自于两部分,一部分是AlluxioRuntime默认提供的一些metrics,这部分metrics被我们使用prometheus收集到,通过cluster metrics可以进行HPA的控制。
如何在不丢失数据的情况下对alluxio集群进行缩容是我们比较关注的,为实现缩容我们对Alluxio java client和Fluid缩容逻辑也进行了二次开发,从而在Fluid中开发了一个指标叫dataset client number,这个指标是通过prometheus的exporter动态地去监控整个集群里有多少应用在使用某一个数据集。如果是有一个应用在使用的话,我们就会把这个数量进行固定的加1,然后我们对上面提到的这些指标进行一些加权计算,组成了一个固定的算法重新生成了capacity_used_rate这个metrics,用于控制 HPA的扩缩容。在右侧,我们现在看到的HPA的CR里会有一个min replicas和max replicas。当用户去申请一个固定容量的Alluxio集群的时候,比如说他申请了1个10T的Alluxio集群,我们会用10T除以每个节点可以分配的内存,求得1个最大的worker副本数。比如说是每个节点1个T,那这样的话将会有10个节点,就是说Alluxio集群最大可以有10个worker,最小的容量一般设置为1或者0,也就是说在没有人使用的时候,Alluxio集群将会被缩容到1个副本或0个副本,这样可以最大限度的节省集群的资源,也可以最大限度地保证所有的Alluxio集群的节点都可以在k8s上进行动态的扩缩容,同时可以保证数据不会发生丢失。
在下面的behavior里我们做了一些特殊的处理,为了保障当用户使用Alluxio的时候,Alluxio的worker可以尽快扩起来,我们使用了一个速率,比如说300,每次扩3个副本。在缩容的部分我们是选用了每60秒缩容一个副本,比如说有两个应用在使用Alluxio的集群,可能两个应用都停掉了,在一分钟之内又有别的应用被调度上,这个时候Alluxio集群是不会进行缩容的。
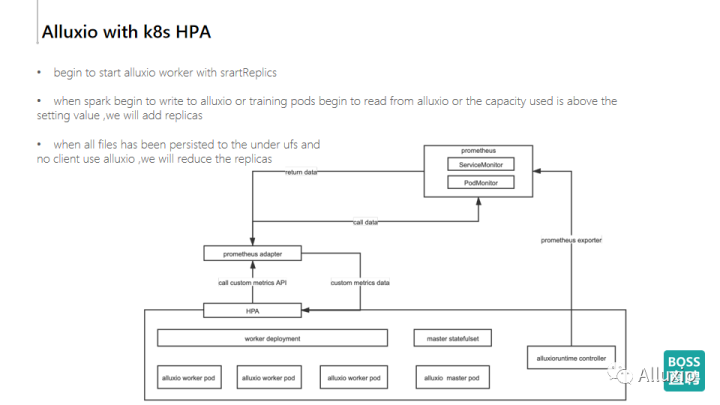
上图我们做了一个比较大的图,显示了HPA的整体流程,首先在集群的最下层我们使用worker deployment替换了daemonset,管控Alluxio worker pod,同时会有一个master statefulsets.apps.kruise.io用于管控Alluxio的master,这里我们将Fluid原有的statefulset替换为kruise的statefulset,提高master HA模式在滚动重启时的稳定性。另外还会有相应的一个controller,AlluxioRuntime controller会使用prometheus的exporter把自定义的指标汇报给prometheus,最后通过prometheus adapter做为HPA的metrics。
通过这样的方式,可以保证比较高的数据写入以及模型训练的速度,且在没有数据丢失的情况下,实现了worker 在集群中动态进行扩容和缩容,下面我们主要介绍后续想要对Alluxio进行的一些扩展。
Part 5 下一步计划

在我们整个的生产实践中,我们发现Alluxio worker在Spark进行大规模的写入的时候,它会占用比较多的堆外内存,对我们的集群会有比较大的负担。因此我们下一步会和社区进行合作,减少每一个Alluxio worker的直接内存的使用。
另外从fuse的角度来说,因为fuse的一些不稳定情况会直接导致TensorFlow训练任务或者PyTorch训练任务的失败,因此我们正在尝试调度层面以及csi plugin的层面做一些fuse pod的remount,比如说fuse pod出现一些异常行为的时候,我们会在TensorFlow或者PyTorch的pod里重新把操作系统进行一些挂载,使训练可以继续往下进行。
另外,因为我们数据的流向是通过Spark到Alluxio,再到ceph的这样一个流向,我们目前在写入的过程中会把Alluxio数据pin˙住,保证数据一定是全部写到了ceph后才会进行驱逐,因此我们这里将会拓展数据的驱逐策略,也就是说数据在保存到ceph里之后,就可以进行驱逐。
最后,十分感谢Alluxio社区范斌老师,邱露老师,朱禹老师,Fluid社区车漾老师对我们的大力支持及夜以继日的努力工作。对Alluxio和Fluid的修改我们将尽快反馈给社区,期待和Alluxio,Fluid社区的进一步深度合作。
观看视频回放,了解更多精彩!








