以下文章源于DeepTech深科技,作者胡巍巍
社会各行业都在进行数字化转型,以保持自身的竞争力,从而导致数据本身越来越多,而基于数据的存储产品以及数据分析、机器学习等数据产品都在增加。
Alluxio 创始人兼CEO 李浩源
“越来越多的企业架构已转向混合云和多云环境。虽然这种转变带来了更大的灵活性和敏捷性,但也意味着必须将计算与存储分离,这就对企业跨框架、跨云和跨存储系统的数据管理和编排提出了新的挑战。”
独立扩展计算和存储的趋势,对象存储的兴起,混合云和多云的日益普及都进一步加剧了与数据访问相关的挑战。
数据被孤立在各种存储系统中,使得用户和应用程序很难有效地找到和访问数据。

例如,当一位工程师或科学家想写一个应用程序来解决问题时,他需要花费大量的精力来让应用程序高效地访问数据,而不是专注于算法和应用程序的逻辑。事实上,只要应用程序框架、存储系统或部署环境(云与内部部署)发生变化,开发人员就需要重新编写数据访问的程序。
数据编排,数据世界缺少的一块拼图
在计算机领域所有的问题,没有任何一个问题不能通过添加一层抽象来解决。这句话来自于著名的计算机专家David Wheeler。
为了从根本上解决数据访问的挑战,世界需要一个在计算框架和存储系统之间架设的新的一层——即数据编排平台。
Alluxio应运而生
Alluxio系统是全球首个分布式超大规模数据编排系统,孵化于加州大学伯克利分校AMP实验室。自项目开源以来,已有超过来自300多个组织机构的1100多位贡献者参与开发,包括全球最头部科技公司、最顶尖的计算机科研院所等,现已成为发展最快的开源大数据项目之一。
Alluxio是一个开源的基于内存的分布式存储系统,同时是面向云环境的的开源数据编排软件的创建者,现在已成为开源社区中成长最快的大数据开源项目之一。Alluxio内存至上的层次化架构使得数据的访问速度能比现有方案快几个数量级。

李浩源本科毕业于北京大学计算机系,随后在康奈尔大学攻读硕士,后赴UC Berkeley AMPLab 获得博士学位,师从分布式系统和网络领域泰斗Ion Stoica教授和Scott Shenker教授。
他在SOSP/NSDI等国际顶级会议发表论文10余篇,Google Scholar引用量3000+,并担任Alluxio开源社区主席和Apache Spark成立委员会委员。
李浩源博士在读期间创立了Alluxio(曾用名Tachyon)技术原型,并随后创建Alluxio公司并致力于推广技术商业化,该公司先后由Andreessen Horowitz,Seven Seas Partners和Volcanics Venture提供风险投资。
在题为《Alluxio: A Virtual Distributed File System》的博士论文中,李浩源提出了一个架构,将虚拟分布式文件系统(Virtual Distributed File System, VDFS)作为计算层和存储层之间的一个新层。
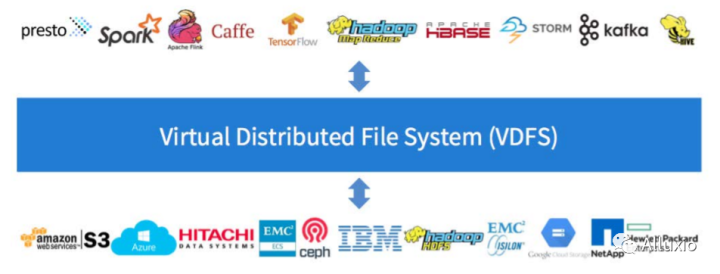
从上图中可以看到,VDFS新层充当着数据中转站的功能,利用抽象的方法分类存储数据,使得数据能够在不同的开发程序、数据库抑或框架之间流动。
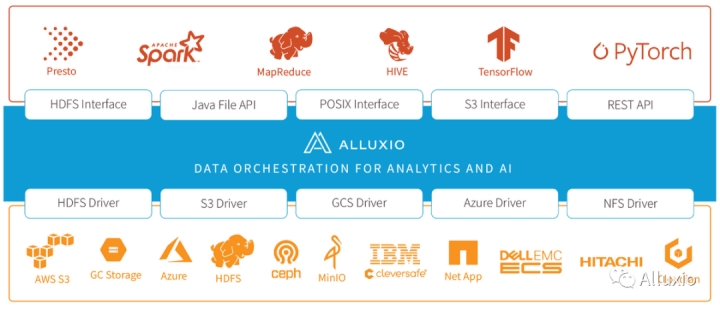
在大数据生态系统中,Alluxio位于数据驱动框架或应用(如 Apache Spark、Presto、Tensorflow、Apache HBase、Apache Hive 或 Apache Flink)和各种持久化存储系统(如 Amazon S3、Google Cloud Storage、OpenStack Swift、HDFS、GlusterFS、IBM Cleversafe、EMC ECS、Ceph、NFS、Minio和 Alibaba OSS)之间。Alluxio 统一了存储在这些不同存储系统中的数据,为其上层数据驱动型应用提供统一的客户端 API 和全局命名空间。从而使得所有上层的数据应用如Spark、Presto、TensorFlow、Pytorch等的性能能够提升几倍乃至几十倍,其最终价值在于帮助客户在相同条件下更高效地产出。
值得一提的是,AMP实验室成功孵化了诸多商业项目,涉及各行各业,包括软件开发、机器学习、生物医疗、基因诊断(MLbase, Cancer Tumor Genomics, DNA Processing Pipeline)等。
Alluxio新一轮迭代聚焦人工智能性能与成本同时优化
11月17日,Alluxio宣布完成5000万美元C轮融资,该轮融资由新投资方高瓴创投领投,战略投资方和原股东a16z、Seven Seas Partners、火山石投资跟投。同时,Alluxio发布了新的2.7版本。
Alluxio的全新一代数据编排创新技术于去年10月在Alluxio 2.4中推出,它具有增强的元数据服务,用于混合云和多云部署的全新管理控制台,以及更多的云原生部署方式支持。
本次发布的2.7版本通过并行数据加载、数据预处理和训练工作流,可将机器学习训练的I/O效率提高8-12倍,从而显著降低成本。新版本还提供了更强的性能分析,并能更好地支持Apache Hudi和Iceberg等时下最热门的开放表格格式,使得对数据湖的访问更易于扩展,从而实现了Presto和Spark的分析提速。
“Alluxio 2.7版本进一步巩固了Alluxio在云上人工智能(AI)、机器学习和深度学习方面的重要地位,”Alluxio创始人兼首席执行官李浩源表示。“随着数据集的增长以及CPU和GPU计算能力的增强,机器学习和深度学习已成为AI主流技术。这些技术的兴起推动了AI的发展,但也凸显了数据和存储系统访问中存在的一些挑战。”
在Alluxio 2.7版本的新增功能中,敏捷性和易用性是关注的重点。
例如,与NVIDIA DALI一起部署用于加速基于Python的机器学习应用,其Alluxio数据平台上的端到端训练与传统解决方案相比实现了显著的性能提升。批处理通过使用内置执行引擎处理数据加载等任务,减少了管理控制器对资源的需求,从而减少了系统配置的工作量,降低了成本。此外,智能缓存新功能,名为Shadow Cache,能够动态分析缓存大小对响应速度的影响,从而轻松实现高性能和低成本之间的平衡。
Alluxio加速全球化布局,将持续渗透新行业
随着越来越多的大数据和AI应用容器化,Alluxio正在成为大型企业和机构的首选,作为加速数据分析和模型训练的中间层。
Alluxio能够在跨集群、跨区域、跨国家的任何云中将数据更紧密地编排接近数据分析和人工智能/机器学习应用程序,从而向上层应用提供内存级别速度的数据访问。
目前,Alluxio的智能数据分层和数据管理功能为金融服务、高科技、零售和电信等诸多领域客户提供了长期业务支持,并已在全球Web规模的现代化数据服务的生产环境中得到验证。目前,全球十大互联网公司中已有包括Facebook、Airbnb、Uber、阿里巴巴、腾讯和字节跳动在内的八家企业部署了Alluxio,还有更多大型企业在生产中运行Alluxio。

从行业的角度来说,渗透率最高的是科技行业,第二名是金融行业,第三名是电信行业,第四名是基因制药行业。全球前五名的制药公司,有一家已经在产品线中应用Alluxio。当一个行业数字化进程越深,应用Alluxio带来的价值就越高,渗透率就会越高。
Alluxio 2021财年营收比2020财年增长3.5倍,创历史新高,并实现正现金流。在这一年中,Alluxio实现了为全球排名前六公有云中的五家提供数据编排层,用于各种环境中的分析和AI工作负载,包括多云和混合云。
扎根国内,基于开源商业化经验加速研发和市场化
2021年1月,为响应国家十四五规划和2035远景目标,期望在推动数字经济发展中贡献自己的力量,Alluxio中国区总部落地北京中关村,进行自主开发和研发,成为了一家拥有独立自主知识产权的本土企业。
与此同时,Alluxio几乎拿到了所有在数据行业主流的奖。不仅如此,Alluxio开创的数据编排技术已经在不同垂直领域的国内外头部公司被广泛应用,包括腾讯、阿里巴巴、中国联通、星展银行、脸书等。

Alluxio通过在开源的基础上开发企业版本实现商业化。李浩源谈到,从战略层面来讲,Alluxio是没有竞品的。同时,Alluxio具有非常好的Github社区运营经验,一方面快速而深入地迭代软件,使它的价值越来越深,同时保障用户在使用过程中的技术支持。
凯文凯利在《必然》一书中写到,任何技术都将不断面临升级的需求和风险。Alluxio最初以内存级的速度表现最为突出,而现在需要把更具战略性的价值往前提升,这是一个迭代的过程。
对于整体技术发展方向,从介质的角度,Alluxio与英特尔和英伟达这两家公司都是战略合作伙伴。最核心的方向仍旧是支持Alluxio上面的数据应用,使数据被高效地应用。新版本中有三个核心:第一是加强和加深了对大规模数据分析的支持;第二是加强和加深了对人工智能和机器学习的支持;第三是通过增强与kubernetes(K8s)的整合让平台的用户使用更容易。
在未来,Alluxio将继续在科技、金融、电信及基因制药行业大力探索,特别是与国内企业的持续合作,以利用产品和市场进一步驱动增长。据悉,Alluxio将为国内基地招募大量大数据方向的技术人才,以发挥团队最大的战斗力,并加速对于研发和市场化的投入。
参考
[1] Alluxio: A Virtual Distributed File System, Haoyuan Li, University of California, Berkeley, Technical Report No. UCB/EECS-2018-29
[2]https://www.alluxio.io/blog/data-orchestration-the-missing-piece-in-the-data-world/








