EN中文
在本地、云、混合或多云环境中,支持无缝访问、管理和运行您的数据和人工智能工作负载
* 海量多模态数据:在自动驾驶的模型训练环节中,数据集通常由数十亿到数百亿个小文件组成,每次训练需要使用数千万到数亿个文件。存储系统面临着管理数十亿到数百亿个小文件的挑战
* 跨地域、多云及混合云环境下的数据孤岛严重制约研发效率。智驾企业普遍采用”本地研发+云端训练”的混合架构,而具身智能公司更需要跨机房、跨地域的数据协同。数据在不同存储系统间的迁移和同步消耗大量时间,使得算法迭代周期被迫延长。
*现有的存储基础设施在面对高并发读取、低延迟数据流转时表现不佳。在仿真测试、模型训练等关键环节,多个计算任务需要同时访问同一数据集,存储系统很容易成为性能瓶颈,导致昂贵的GPU计算资源闲置浪费。
* 数据存储成本高,尤其是全闪NAS成本高昂:Robotaxi单台车每天产生4000GB数据量,按照一般云厂商的收费标准,存储一年的成本约35万美元(折合人民币约244万元)。一般自动驾驶企业都会把训练数据分布在多个低性能对象存储集群;在GPU服务器和对象存储之间一般会采用高性能全闪NAS作为缓存系统,从而维持高GPU利用率。但是全闪NAS成本高昂,随着训练数据集不断增长,扩容成本无法承受。
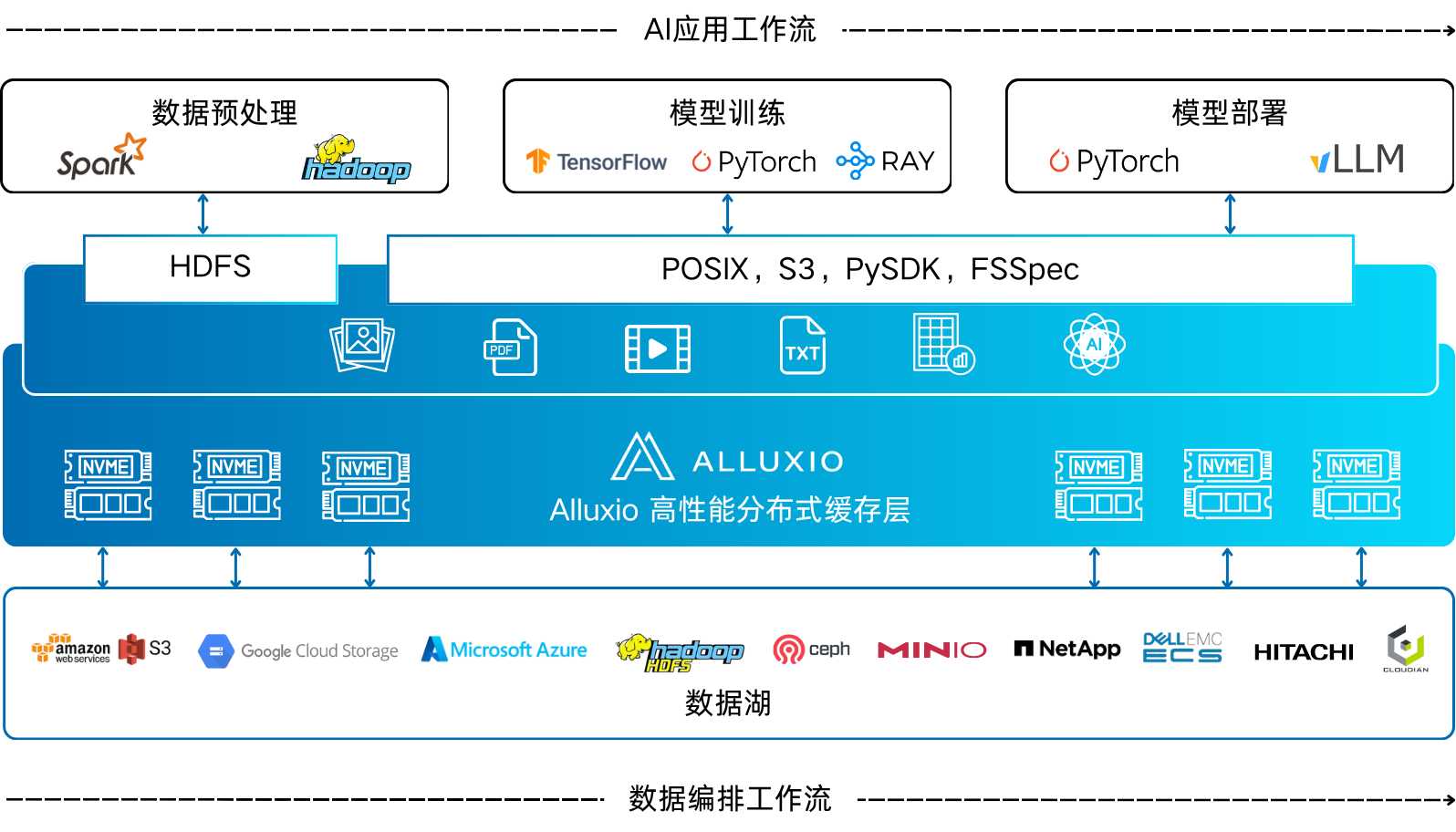
构建高效、统一、可扩展的数据存储底座,已成为突破智驾与具身智能规模化发展瓶颈的核心关键。只有打通从数据采集、数据预处理、仿真训练等全链路,才能让智能体在真实的物理世界中实现快速、持续进化。
《为企业生产环境下的AI负载选择合适的架构》
《Presto优化宝典》进阶版
大模型制胜宝典——解密AI高效数据访问策略










 京公网安备 11010802040260号
京公网安备 11010802040260号



