
在Alluxio近期举办的线上技术讲座中,Coupang资深后端工程师Hyun Jun Baek 分享了Coupang如何利用分布式缓存加速机器学习模型训练。本文提炼了Hyun分享的核心观点,重点介绍了Coupang的分布式缓存方案如何重塑其跨区域混合云机器学习平台。
👉 观看完整视频分享 👈
Coupang 是一家《财富》200强科技公司,采用多集群GPU架构来支持AI/ML模型训练。然而,这一架构也带来了诸多挑战,比如:
1、数据准备耗时与数据拷贝/迁移耗时严重;
2、GPU资源利用率难以提升;
3、存储成本居高不下且持续增长;
4、维护本地化数据孤岛导致运维负担过重。
为解决这些问题,Coupang AI平台团队部署了分布式缓存系统,其创新性体现在:
1、自动从中央数据湖获取训练数据;
2、显著提升数据加载性能;
3、为模型开发者提供统一访问路径;
4、实现数据生命周期自动管理;
5、轻松扩展至Kubernetes环境。
新架构带来六大收益:
1、模型训练速度提升;
2、存储成本下降;
3、跨集群GPU利用率提高;
4、运维成本降低;
5、训练任务具备可移植性;
6、相较并行文件系统实现40%的I/O性能提升。
关于Coupang
Coupang (NYSE:CPNG)是一家《财富》200强科技企业, 旗下拥有Coupang、Coupang Eats、Coupang Play和Farfetch等品牌,为全球消费者提供零售、餐饮配送、视频流媒体及金融科技服务。
Coupang AI/ML 平台
机器学习正在深度赋能Coupang的全商业生态,通过产品目录优化、智能搜索推荐、动态定价、机器人技术、库存管理和订单履约等核心环节,持续提升终端用户体验。

Coupang AI/ML 平台提供Notebook与ML工作流编排、 模型训练、模型推理、监控和可观测性以及训练和推理集群等核心服务。
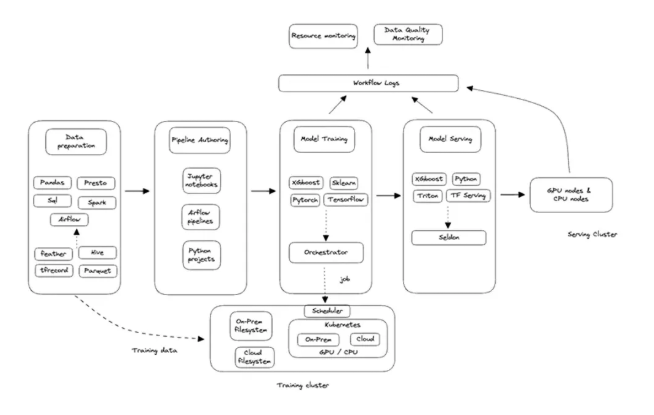 |
| 图表来源:揭秘Coupang机器学习平台:(https://medium.com/coupang-engineering/meet-coupangs-machine-learning-platform-cd00e9ccc172) |
混合云及多区域计算存储架构
为满足对计算资源、运行效率、高I/O吞吐量、开发者体验及云成本优化的内部需求,Coupang平台团队采用AWS多区域云服务与本地GPU集群相结合的混合架构。这一混合云+多区域策略有助于Coupang 应对全球范围内的GPU短缺问题,确保机器学习训练所需的大规模GPU资源供给。
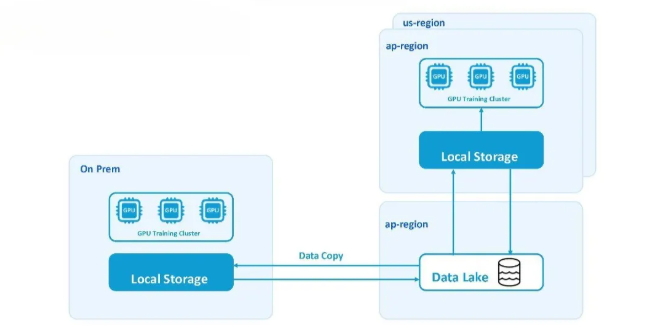
该架构图展示了GPU AI/ML训练集群在混合云及多区域基础设施中的部署方案。其中,AP region的数据湖作为训练数据的唯一可信源,而GPU训练集群则采用跨云平台与本地环境的混合部署模式。各集群的计算存储架构存在差异化配置:云端采用托管式Kubernetes服务,而本地环境则部署原生Kubernetes。
多集群GPU架构面临的挑战
该架构面临诸多挑战:
1. 训练任务前的准备步骤(数据拷贝与验证)在这种分布式 GPU 架构下,Coupang 在调度训练任务之前须进行准备步骤。用户需要将训练数据从数据湖(对象存储)拷贝到训练任务即将运行的集群中。该过程不仅耗时,而且不稳定,尤其是在传输大量数据时常常导致延迟。由于训练数据必须预先拷贝至任务所在的GPU集群,导致分布式基础设施中的GPU资源难以得到充分利用。例如,如果某训练任务最初分配至us-region集群,后续需要重新分配到其他集群时,必须先将数据完整拷贝至新集群才能启动任务。
2. I/O 瓶颈导致 GPU 资源利用率低下训练数据拷贝至GPU集群所在区域后,通常存储在性能较低的存储系统中。这类存储无法提供足够的吞吐量来充分释放GPU算力,造成GPU利用率低下。尽管云服务商提供性能更优的并行文件系统,但其成本高昂且无法有效扩展。
3. 管理数据孤岛的成本与运维复杂度不断增长将数据拷贝到多个GPU集群会形成数据孤岛,从而增加存储成本。存储维护带来巨大的运维负担。作为平台团队内部用户的ML工程师,常常未能及时删除冗余数据,导致磁盘空间不足问题频发。这不仅增加了平台团队的管理复杂度,还会导致训练任务失败。
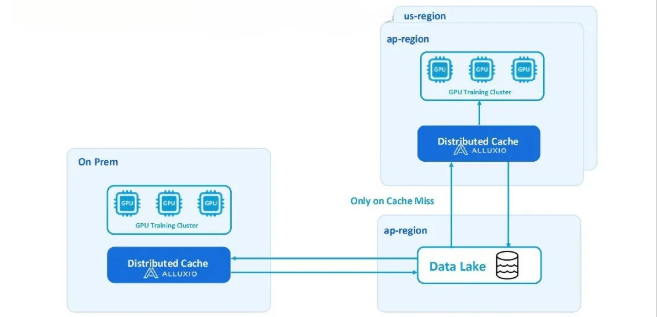 |
| 基于分布式缓存的新架构 |
Coupang的新型分布式缓存架构通过以下方式解决了上述挑战:
1、实现数据即时可用:自动从数据湖提取数据至各集群,彻底消除冗长的数据准备环节
2、提升跨区域GPU利用率:无需数据拷贝即可灵活调度训练任务至任意集群
3、提供更高I/O吞吐与更低延迟:性能超越传统文件存储及并行文件系统在云环境中,分布式缓存层部署在配有 NVMe 存储的实例上,而在本地部署中,则使用配有 NVMe 磁盘的 CPU 节点。
分布式缓存通过仅缓存热数据而非存储整个数据集,来降低存储成本。同时,它还消除了运维负担,因为缓存会自动管理数据生命周期,ML工程师无需手动删除冗余数据。Kubernetes Operator 简化了在整个 GPU 架构中部署和管理分布式缓存方案的过程,确保配置一致,并加快了新集群的部署速度。
分布式缓存工作原理
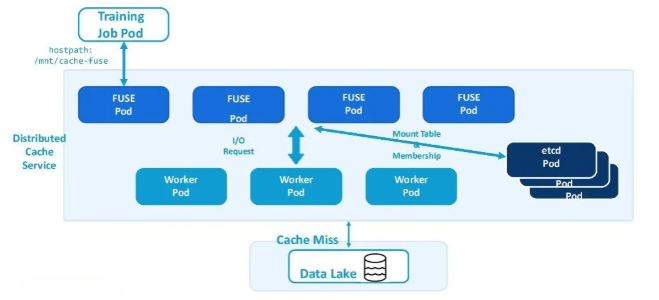 |
| 分布式缓存的部署方式 |
FUSE pod 为训练任务提供符合POSIX标准的文件系统接口。这些 pod 通过 hostPath 卷(如 /mnt/cache-fuse)挂载到训练任务的容器中,使任务能够直接访问缓存数据和底层数据湖,无需修改代码或了解缓存的内部机制。
每个 FUSE pod 会将 I/O 请求转发给一组后端 worker pod,由它们负责实际的数据读写操作。这些 worker pod 通常在配备 NVMe 磁盘的实例上运行,能够以高吞吐量访问存放热数据的本地存储池。
当请求的 page 不在缓存中(即发生缓存未命中)时,worker pod 会从底层数据湖中获取数据。一旦获取完成,数据将被缓存在本地,从而大幅加速后续的数据访问。
为了保持一致性并支持服务发现,etcd Pod 在整个缓存集群中管理挂载表和 Worker 成员信息。这确保了在不同部署中数据路径的一致性。例如,“bucket A” 中的文件始终可以通过 /data/bucket_a 访问,无论是在什么集群或节点上。这一机制实现了训练脚本的无缝可迁移性。模型开发者(即平台的用户)可以在任何有可用计算资源的地方运行训练脚本,而无需修改代码中的数据路径。
采用分布式缓存的优势
对模型开发者的价值
1、数据即时可用:新的架构让模型开发者能够立即执行训练任务,无需等待数据拷贝或缓存,训练作业可即时启动。
2、无需修改代码,无缝跨区域访问数据:该架构提供统一的数据抽象,所有集群都通过相同的路径访问数据,实现跨区域的无缝访问。由于代码具备可移植性,用户可以在任何有计算资源的地方运行训练脚本,而无需修改代码。
3、提升 GPU 利用率:在 GPU 使用高峰时段,工程师可以将训练任务提交至备用 GPU 集群,无需手动拷贝训练数据,从而确保更高的GPU资源总利用率。
4、更快的训练速度:根据性能测试结果,该分布式缓存方案相比云服务商提供的并行文件系统,在 I/O 性能方面提升约 40%。
对平台工程师的价值
1、降低存储与运维成本:对于平台工程师来说,新架构可避免采购全量存储并消除数据湖中的重复数据集,从而降低存储成本。此外,缓存可自我管理,无需协调清理缓存空间。平台还开发了内部工具,帮助用户自行加载缓存,从而在训练前预热缓存,提升训练过程中的 I/O 吞吐性能。
2、轻松扩容与运维:该架构可通过 Kubernetes 进行管理,使得在不同环境中的部署、扩容和维护简单高效、无缝衔接。
结论
Coupang 全新的分布式缓存架构带来了诸多优势,包括加速模型训练、提升运行效率、降低存储成本、提高GPU 利用率以及减少运维开销。此外,该架构还大幅提升了模型开发者的使用体验,可灵活调度任意可用GPU资源,免去了旧架构中为将数据加载至 GPU 集群所需的繁琐准备步骤。








