| 扩展性 |
单集群可支持的对象数 |
100 亿 |
| IO 性能线性扩展 |
支持 |
| 集群管理 |
Kubernetes Operator |
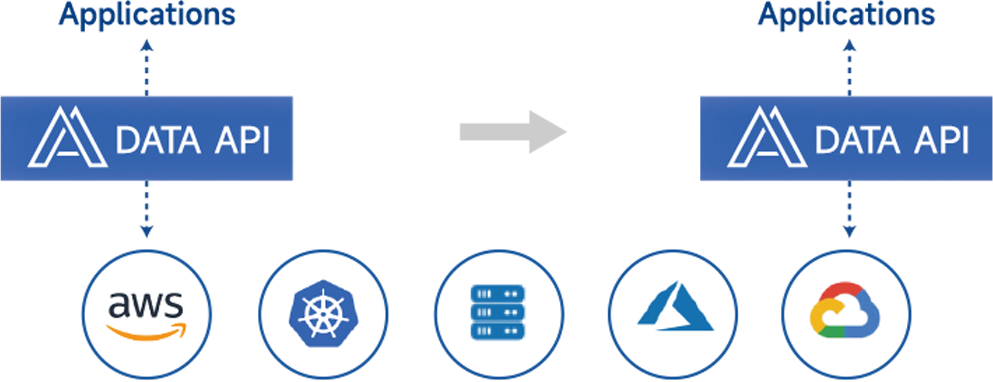
引入 Kubernetes Operator 简化集群部署和管理,确保不同环境中的部署一致性,优化硬件利用率,提供持续监控,并将常规任务自动化:Pod 配置、服务配置、挂载 UFS 卷 |
| 作业调度器(Job Scheduler) |
内置于 Alluxio Core
通过将 job scheduler 集成到 Alluxio Core 中,简化部署和管理 |
| 异构 worker 资源 |
支持具有异构资源配置(CPU, 内存, 网络, 磁盘)的 Alluxio Worker 节点加入同一个 Alluxio 集群,提供更高灵活性 |
| 数据访问 |
统一命名空间 |
支持 |
| UFS 集成 |
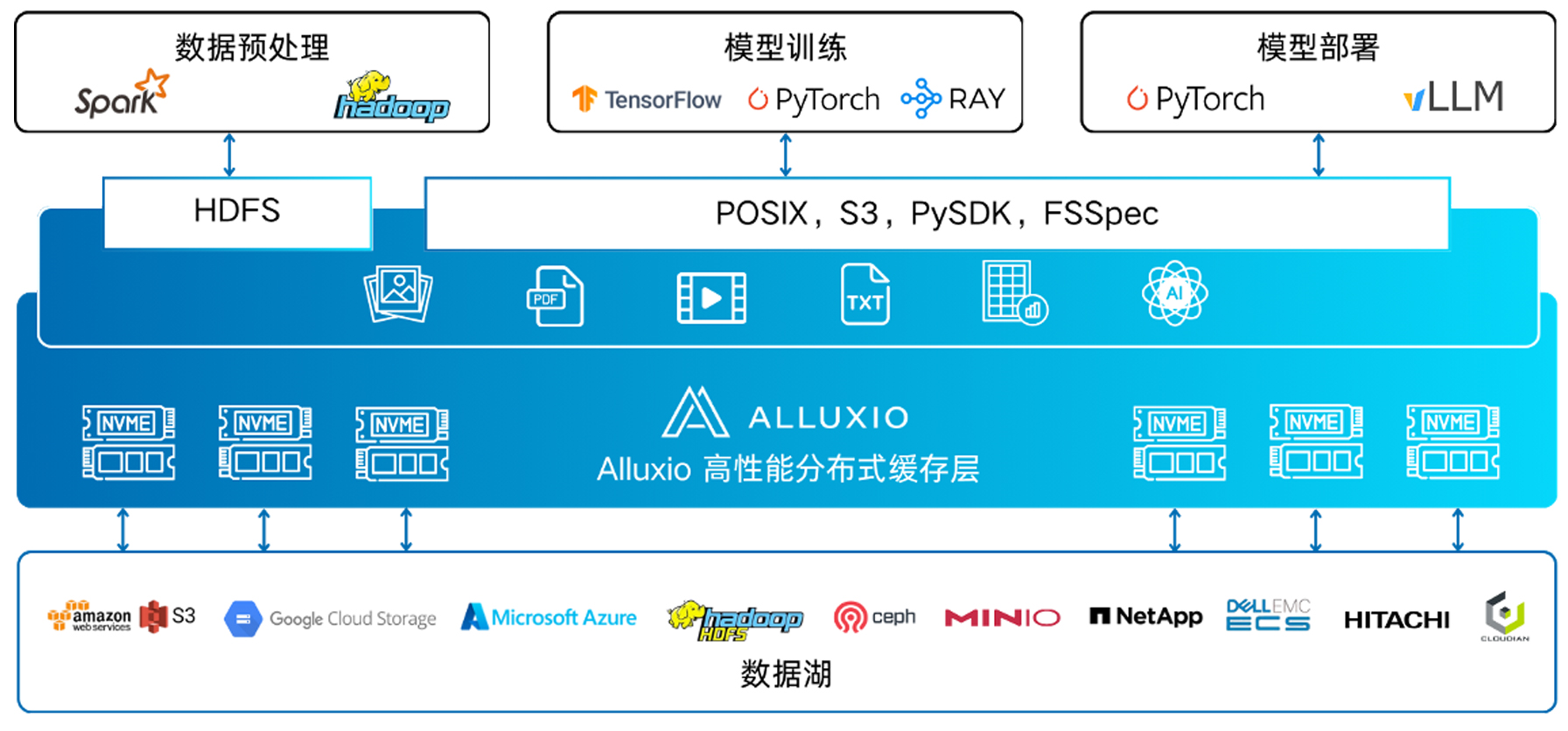
云存储:AWS S3、阿里云OSS、腾讯云COS、TOS、GCS(v1/v2)、Azure blob、百度BOS;
本地存储:S3兼容存储、HDFS、NAS |
| Client 侧 UFS 回退机制 |
客户端UFS回退功能仅在企业版中可用,当 Alluxio Worker无响应时,Alluxio Client 可无缝访问底层文件系统(UFS)中的数据,从而提供对应用程序的持续性保障 |
| 访问接口 |
POSIX(FUSE), S3, PythonSDK/FSSpec |
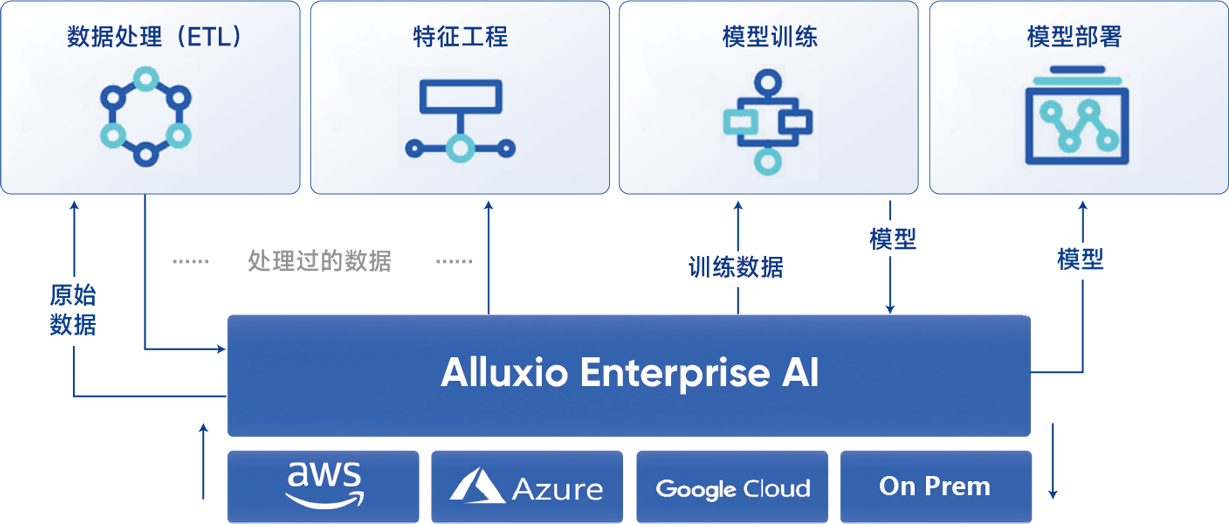
| 透明数据集集成 |
透明数据集集成功能使应用程序代码能够通过现有文件系统路径(例如 s3:///)访问Alluxio中的数据 |
| UFS 读取速率限制器 |
管理员可通过设置速率限制,控制单个 Alluxio Worker 从UFS 获取数据时的最大带宽,实现资源优化利用 |
| 缓存管理 |
数据加载器和缓存释放 |
支持基于子目录或文件列表的加载/释放
对数据加载器(缓存预加载)和缓存释放(手动驱逐数据)功能升级,除目录外,新增基于文件列表的灵活加载和释放 |
| 配额管理 |
顶级目录和嵌套目录 |
| 缓存存储单元 |
Page (4MB)
使用更小且高效的基于page的缓存存储单元(≤ UFS block 大小,可配置) |
读放大<20%
企业版中基于page的缓存将社区版5-10倍的读放大系数降低到不到原先的20% |
| 基于优先级的缓存驱逐 |
允许管理员为特定目录/文件设置缓存驱逐优先级,高优先级目录/文件即使本应被驱逐也会保留在缓存中 |
| 缓存过滤 |
缓存过滤功能允许管理员设置过滤规则,管理哪些文件会被缓存、是否需要检查以及按照什么频次检查底层文件系统(UFS)的元数据或数据变化 |
| 异步缓存驱逐 |
通过异步驱逐数据提高性能,尽量避免在缓存写入时驱逐数据,管理员可根据缓存容量及最大可缓存page配置异步缓存驱逐策略 |
| CLIENT 和 SDK |
S3 API 网关 |
内置于Alluxio Core
S3 API 网关内置于Alluxio Worker进程中,通过移除代理进程,消除了 Client 与 Worker 间的额外线程,同时在Kubernetes环境中降低了由于管理代理进程而导致的部署复杂性 |
| 网络传输优化 |
高性能零拷贝网络传输
高性能零拷贝网络传输零拷贝传输通过消除Protobuf序列化降低了CPU占用,同时使用更优化的内存管理机制,有效缓解了内存不足问题 |
| Python SDK |
基于 FSSpec 的原生 Python SDK,强化与主流 AI 框架的集成 |
| 安全性 |
TLS 支持 |
包含TLS支持,可确保Alluxio组件之间以及Alluxio与底层文件系统(UFS)之间安全通信 |
| CVE 补丁 |
Alluxio会监控常见漏洞与披露(CVE)记录,并在必要时及时向企业版客户提供补丁 |
| 安全审计日志 |
Alluxio审计日志功能提供对所有数据访问和操作的完整可视化追踪。每一次与Alluxio交互都会被自动记录句括:用户身份与认证信息;执行的操作(读取、写入、删除等);精确时间戳;被访问的资源与路径。 |
| 可靠性 |
可用率 |
99.95% |
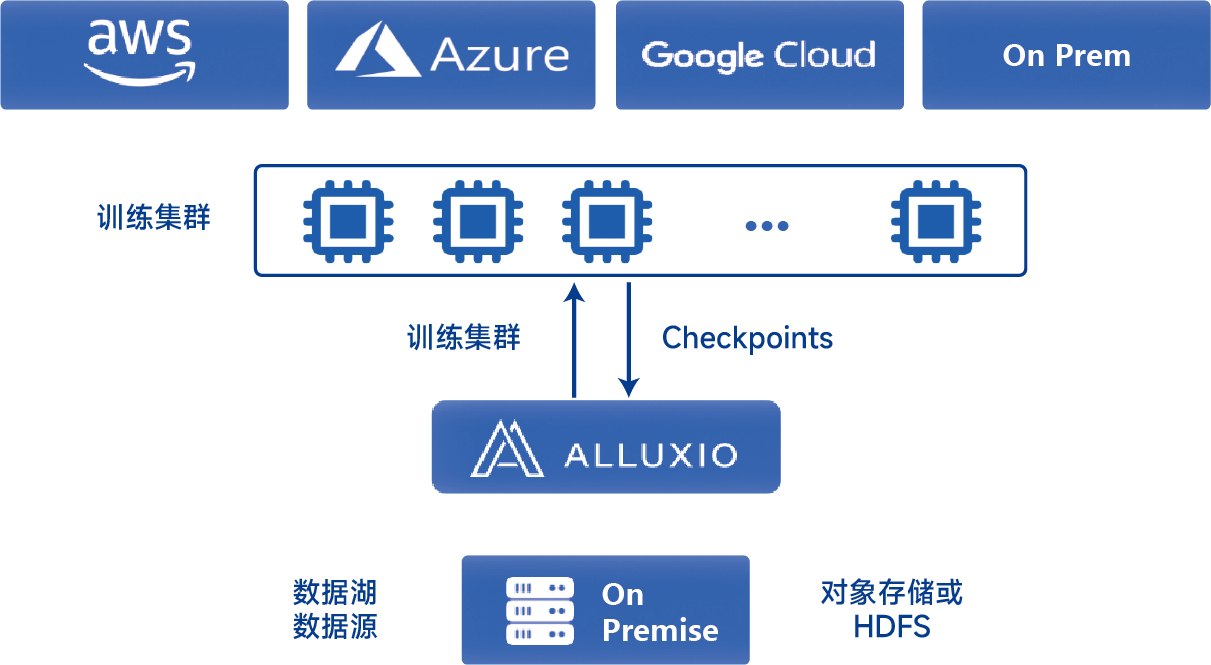
| 高可用性 |
客户端到UFS的故障转移、文件复制、多可用区高可用性支持 |
| 可观测性 |
指标 |
支持 |
| 仪表盘 |
支持 |
| 产品支持与服务 |
7x24小时技术支持 |
支持 |
| 紧急修补 |
支持 |
| 专业服务-运维状态检查 |
支持 |
| 服务与最佳实践 |
支持 |
| 部署 |
操作平台 |
K8s(1.22+),裸金属机(Linux操作系统,内核版本5.4+) |
| 硬件平台 |
X86, Arm64 |
| 网络协议 |
TCP/IP、IPoIB |
| 是否支持异构节点 |
支持 |
| 多网卡 |
支持 |














 京公网安备 11010802040260号
京公网安备 11010802040260号



