分享嘉宾:
刘礼铭——bilibili人工智能资深工程师
一、B站AI的训练场景
机器学习平台介绍
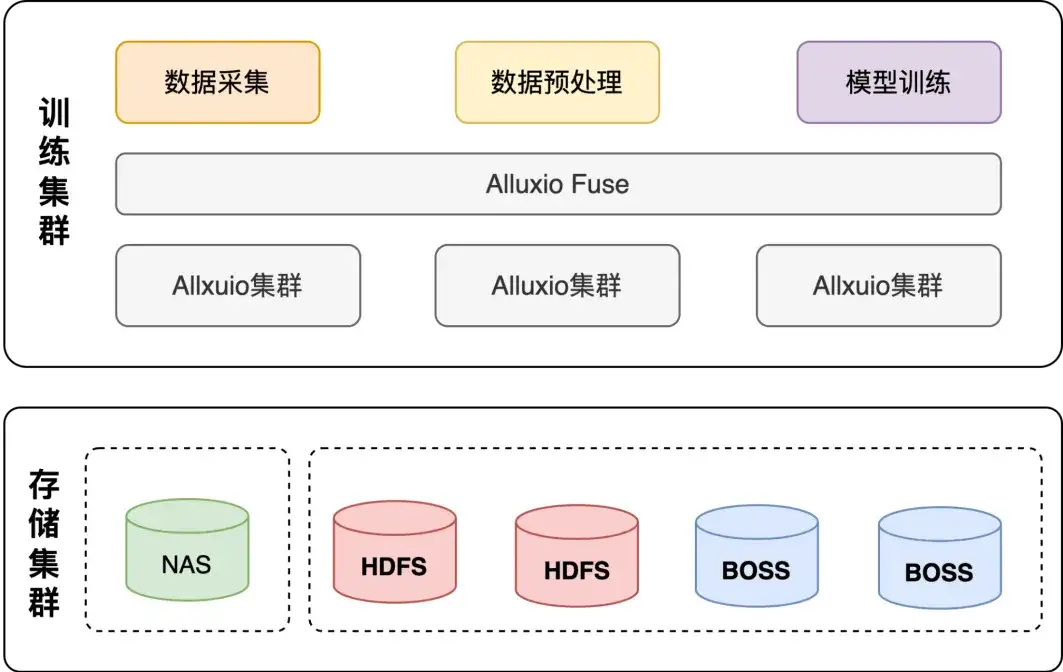
首先,简单介绍一下B站 AI 的训练场景,整个机器学习平台的架构如下图所示:
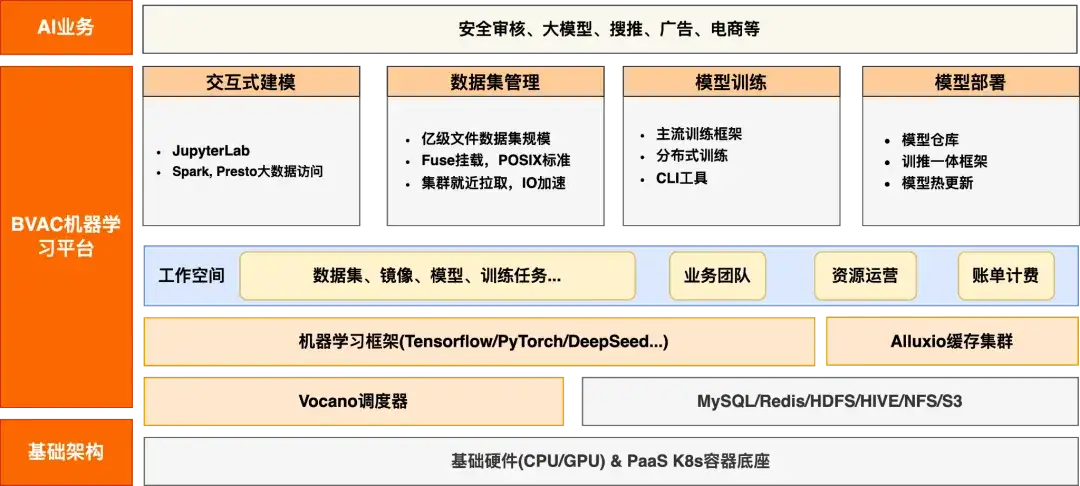
它具备了一个常规机器学习平台的能力,比如交互式建模、数据集管理、模型训练、模型部署等基础能力,用户也会有一些精确的数据集、业务团队以及资源运营相关的能力,同时对机器学习框架(比如业界流行的 TensorFlow、PyTorch、DeepSeed 以及自研的一些框架等)都需要兼容。同时,为了加速整个训练的收益,我们与 Alluxio 进行了很多合作,搭建了一个在 AI 训练场景的训练集群,调度器主要是 Volcano,是现在机器学习平台常用的。
已有存储方案介绍
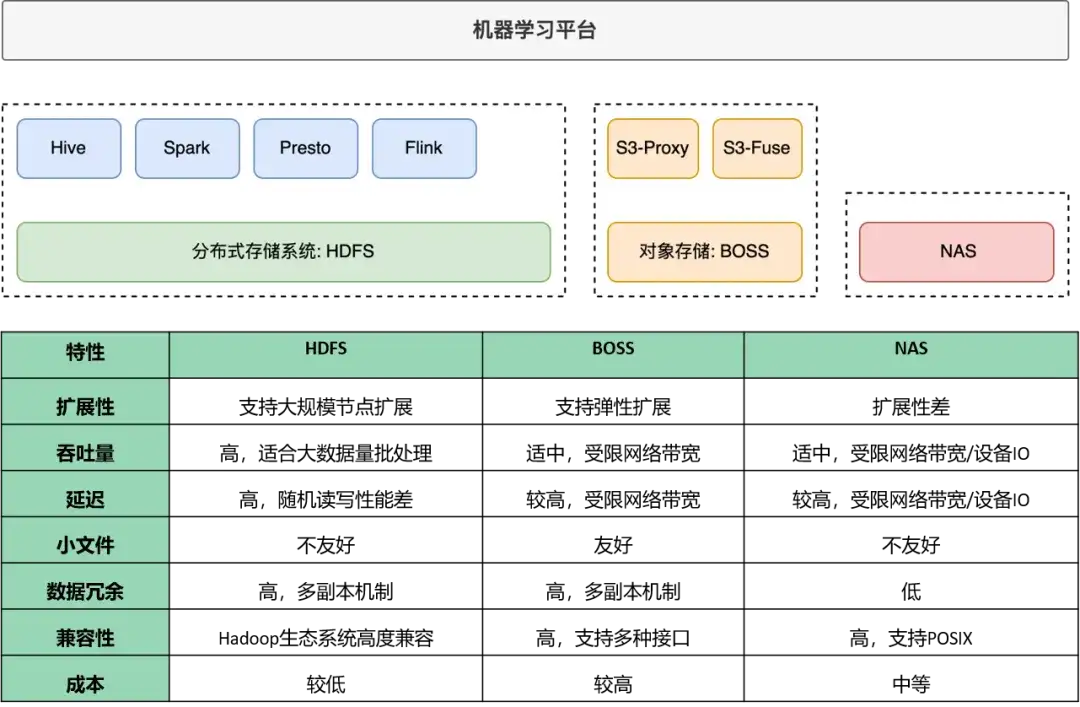
下图是我们搭建 Alluxio 之前的存储方案, HDFS 主要针对大数据的分析场景,B站自研的 OSS 存储叫 BOSS,还有一些 NAS 存储的系统,当然每个存储系统都有自己的优缺点,这里也简单的做了个对比。
AI 训练场景介绍
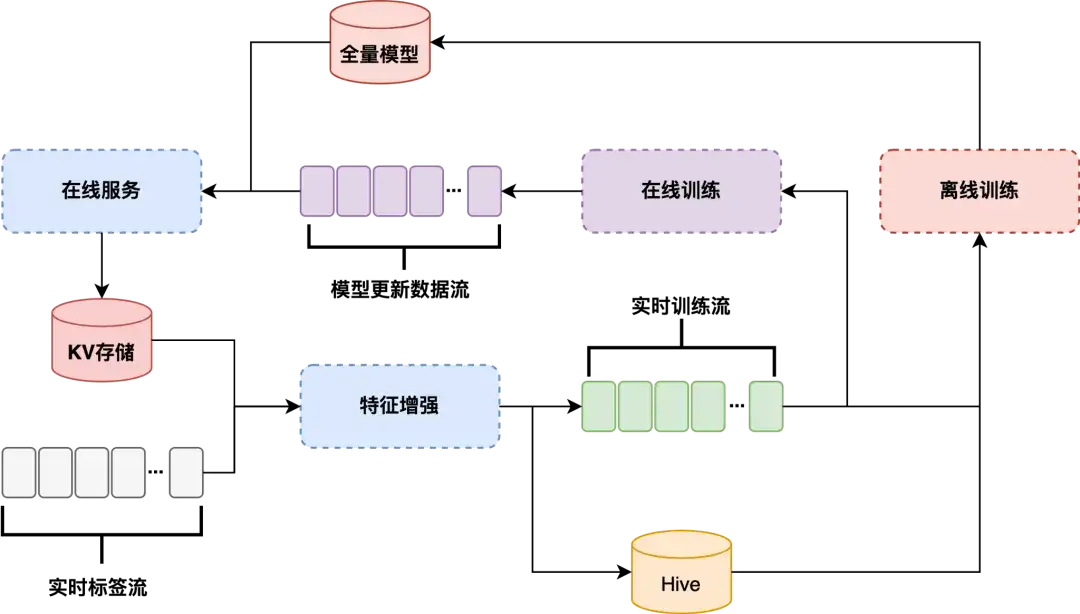
1. 搜推
一个是搜推,比如商业、广告、流量推荐,这种场景就是很明显的大数据存储的场景,跟 HDFS 这一套就非常的亲和。
2. CV/ 大模型场景
这个场景也是目前我们使用 Alluxio 的一个主要业务场景,这里有一个特点,单数据集的规模很大,比如我们最近在用的一个数据集,已经达到了 PB 级,文件数量大概在亿级别,基本都是小文件。CV 训练以图片、音频等为主,基本都是100KB、1M大小,数据比较多样,有图片、视频、音频、文本等。
AI 训练存储痛点
我们在训练过程中发现了几个存储方面的痛点:
1. 存储容量:
-
因为现在随着大模型的引入,数据量会越来越大,对数据容量的要求会越来越高,像我们现在大数据集,可能会达到上百T;
-
这是一个快速增长的过程,而且特别是最近的 Sora 带火了 TTV 这种场景,所以视频的规模会非常大,存储系统需要具备高扩展性以应对不断增加的数据需求。
2. 性能瓶颈:
-
高吞吐:AI 训练需要频繁读取和写入数据,存储系统需要支持高吞吐量以保证数据加载速度;
-
低延迟:数据读取的延迟应尽可能低,否则会影响训练效率,导致 GPU/NPU 等计算资源的浪费。
正如大家所熟知的,现在买卡非常难,如果 GPU 由于 IO 导致利用率低,那肯定是不划算的;
3. 成本、安全:
-
高成本:存储大量数据尤其是高分辨率图像和视频数据,存储成本很高,需要平衡性能和成
-
访问控制:需要对数据访问进行细粒度的权限管理,确保数据安全。
基于 Alluxio 的训练存储架构
为了解决这些痛点,我们在调研之后,采用了 Alluxio 的方案,主要有三大吸引点:
- 统一命名空间:将不同存储系统(如 HDFS、BOSS、云存储)抽象为一个统一文件系统接口,对用户来说不用感知底层的 HDFS,只需要挂 Fuse;
- 内存或 NVMe 缓存:结合内存和 NVMe 存储缓存,提升访问速度,降低 I/O 延迟,用的比较多的是 NVMe 的场景,大量 GPU 都会高配这种 NVMe;
- 多存储后端:兼容 HDFS、对象存储等多种存储后端,扩展性强。
二、Alluxio 在 AI 训练场景的应用
为什么选择 Alluxio ?
这里先介绍一下 Alluxio 的主要优势:
- 性能高:低延迟高吞吐的数据缓存能力,对于 AI 训练尤其重要;
- 兼容性强:支持 S3/HDFS 后端,提供了广泛的数据源兼容性;兼容 POSIX 协议;
- 运维成本低:运维成本在大规模数据存储和处理环境中尤为重要,有助于减少整体运维投入;
- 大规模数据处理:Alluxio 支持亿级的数据量规模,能满足 AI 训练需求。
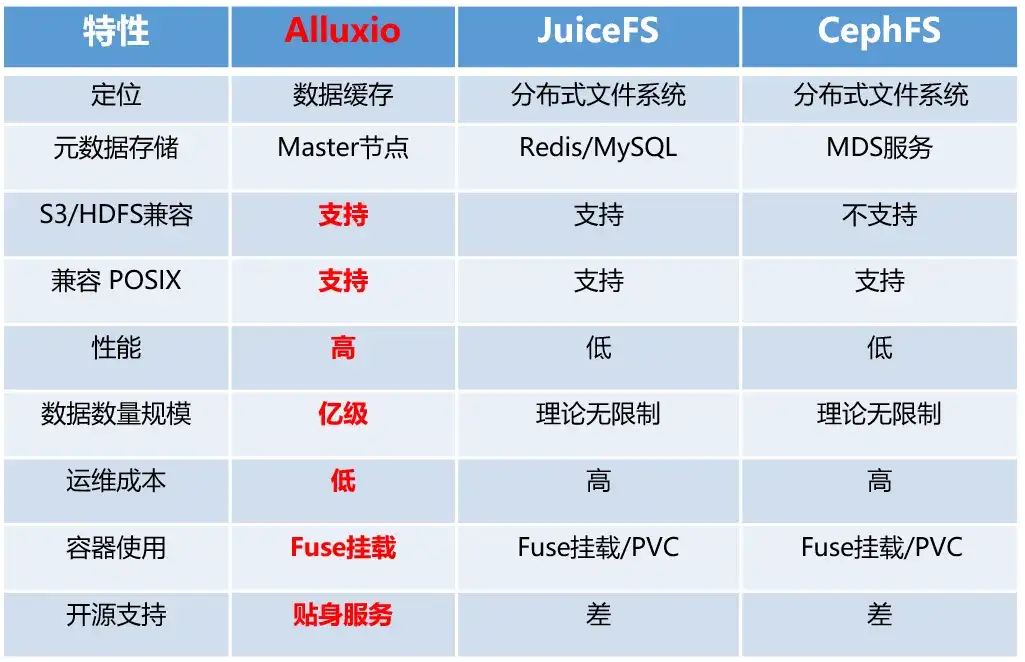
在做技术选型的时候,我们也对业界常用的几个系统做了调研和分析,基于B站的体量,我们没有人力单独为 AI 做存储的维护,所以第一个优先考虑的就是成本,需要投入更低的成本、更低的运维,支持更强的性能。在调研过程中 Alluxio各方面表现优势明显,最终我们选择了 Alluxio。
单集群 or 多集群?
在部署的时候 Alluxio 采用的是一种多 Master、多 Worker 的方式。但B站在大数据集场景是一种单集群部署的模式,优势是:一个集群可以集中管理、运维成本比较低,可以实现资源的高效利用;缺点是现在社区版2.9.4的元数据存储在 Master ,很容易碰到天花板,扩展性比较有限,如果我们单个集群出现了问题,对业务的影响是比较大的,所以在 AI 场景我们最终采用的是多集群部署的方案。
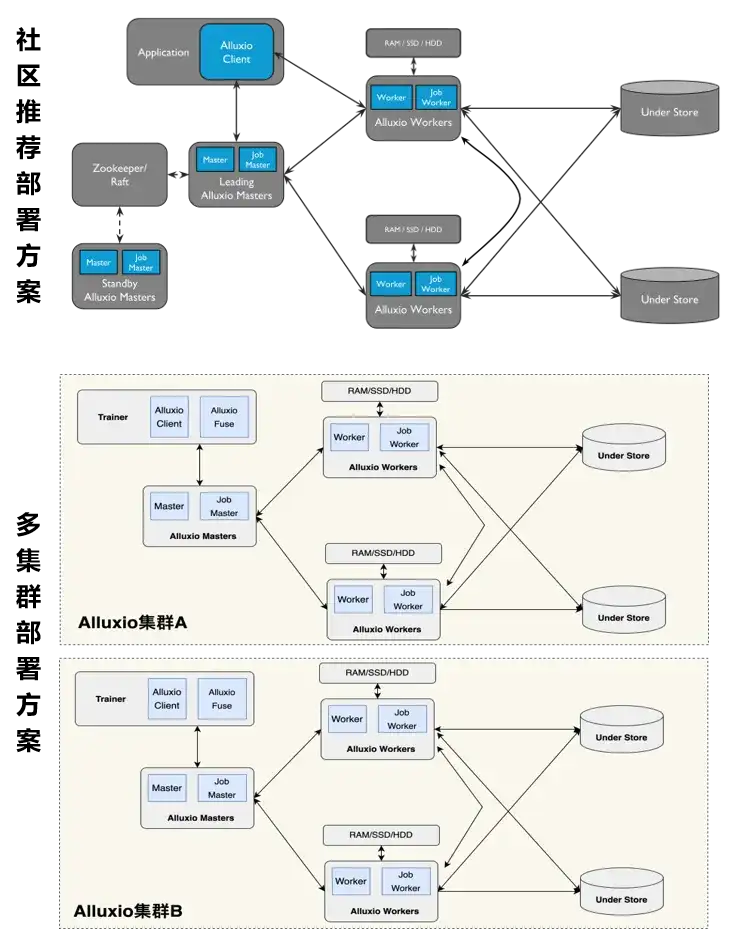
基于整个集群的存储规模,集群的划分会按照业务或者是数据集,好处是某个业务或者数据集需要更强的能力,我们则会投入更多的资源,而对于那些不怎么重要的业务,或者是低优先级的业务,则需要把它隔离开,从而不至于让低优先级的业务影响到高优先级的业务,这是我们最终采用的方式。
通过多集群的方式,在部署运维方面会增加更多的成本,那么如何解决这个问题?
基于 Fluid 的云原生多集群部署方案
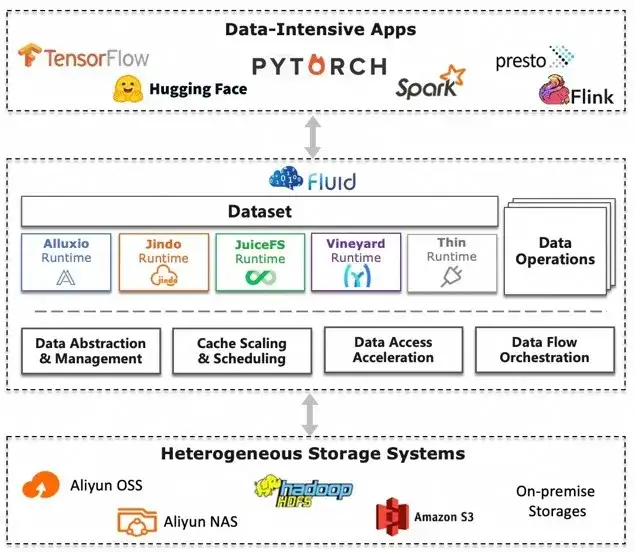
这里我们引入了 Fluid。Alluxio 是对底层存储的抽象,Fluid 又是对 Alluxio 这一层 Runtime 的抽象。通过 Fluid 之后,我们可以更好的在 K8s 上,更自动化的部署多集群的方案,目前我们应该有百机规模的集群。
调度优化
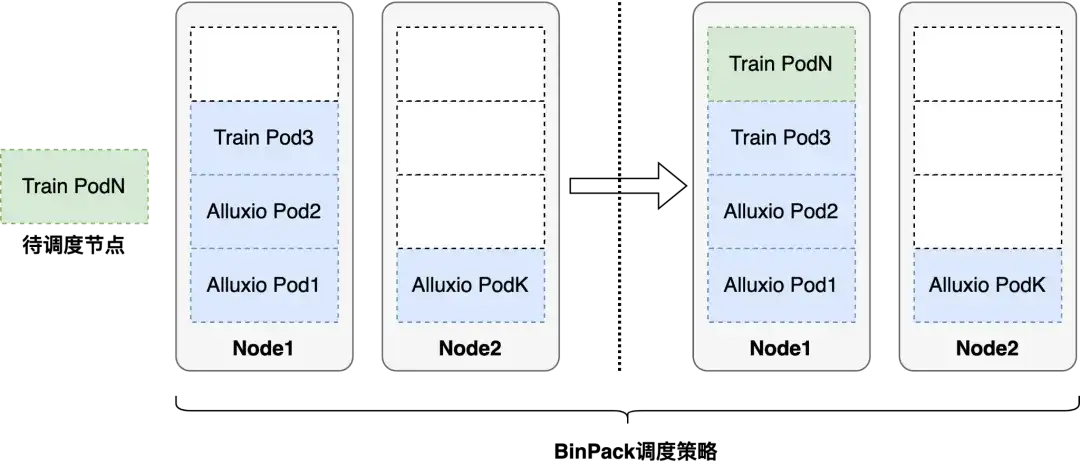
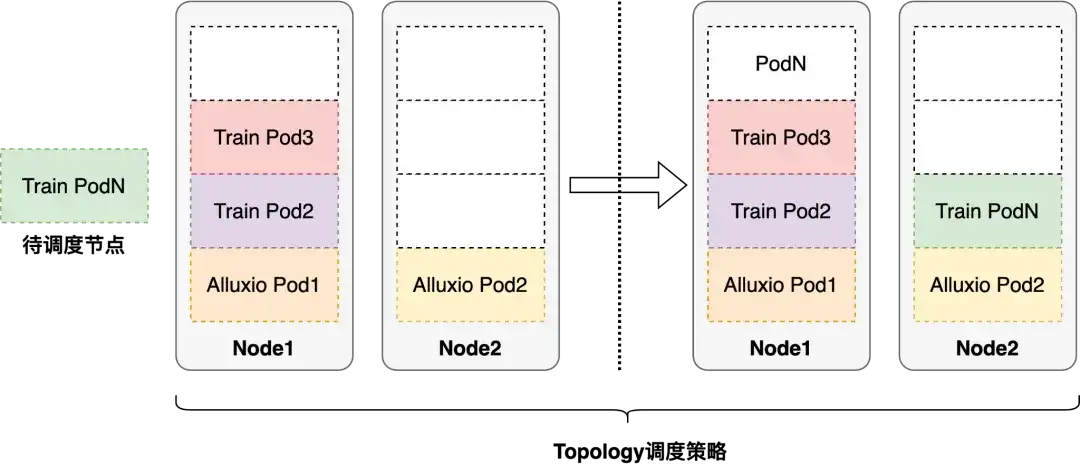
另一个问题是,我们在实际应用中使用的是 volcano 调度器,主要是 binpack 为主,binpack 的策略是尽可能的把单台机器塞满,对我们这种 IO 密集型的业务,如果把所有的节点都调度到单台机器上,很容易造成单点故障,给 IO 造成瓶颈,另外也会带来网络拥塞、资源利用不均等问题。
解决办法:我们结合了业务特点以及本身的缓存加速场景,采用的是拓扑感知的调度策略。首先,会尽可能的让 Alluxio 的节点分散到我们集群的每台机器上,尽可能的把 IO 打散。其次,在任务调度的时候,我们也会去感知 Alluxio 的拓扑分布,尽可能做到任务与 Alluxio 节点的亲和,这样亲和之后相当于在读本地硬盘。
元数据同步加速
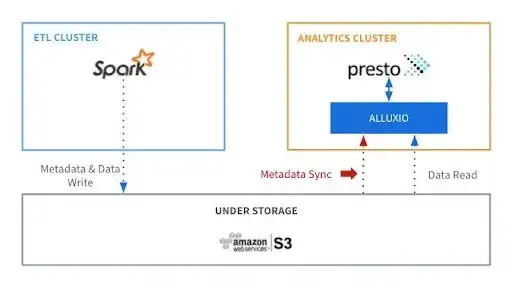
元数据同步的必要性:
- 元数据同步在 Alluxio 中至关重要,因为它确保 Alluxio 文件系统与底层存储系统中的数据保持一致
这个问题我们也同样遇到过。当数据量大了之后,如果我们按照官方的元数据同步方法,对整个集群的稳定性和性能都会有很大的影响,所以我们最终采取了一种按需同步的方法。因为我们已经把集群暴露给用户,他可以直接操作他的集群,知道什么时候数据是更新的,由他来决定;另外,如果是那种亿级别的数据集要做 Meta 同步,至少是小时级别,这个肯定是不可接受的,所以我们也在要求用户最小化他的同步单元,尽可能的减少无效的同步计算。
具体同步方式:
- 基于时间的自动同步:设置alluxio.user.file.metadata.sync.interval 属性 来定时同步;
- 手动同步:使用 loadMetadata 命令或 API 手动触发同步。
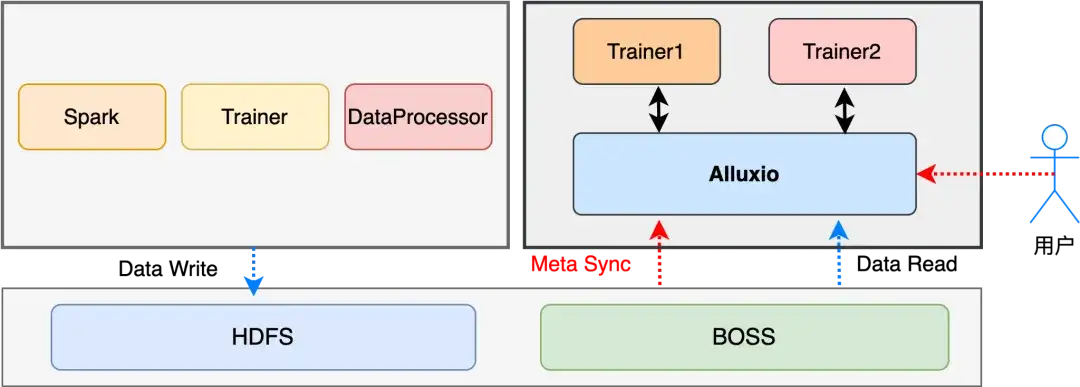
加速方式:
- 按需同步:只在需要时触发;
- 最小范围同步:最小范围同步,减少无效同步计算。
超大规模小文件优化
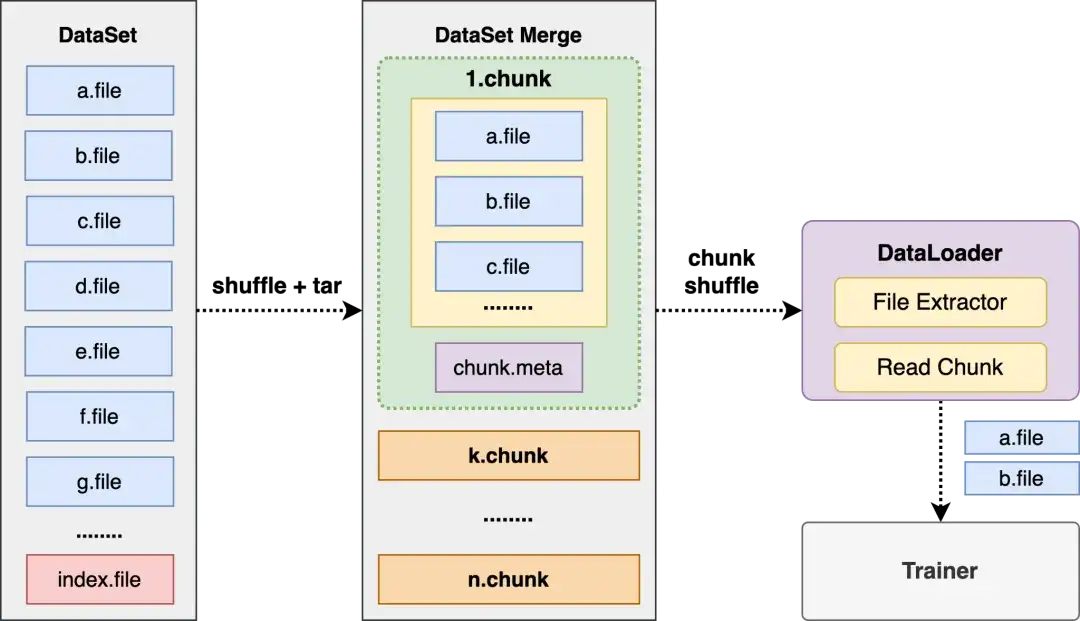
我们很多场景的数据都是以小数据为主,如果只是简单的把数据给到 Alluxio,然后什么都不做,这样就会有两个问题,一个是 Meta 会很多,本身我们采用的就是 Master 的架构,整个集群对 Master 的压力会很大;另一个就是用户会无组织的去用,因为他根本就不知道该做哪些组织才有利于数据的 IO。这块我们主要是做了数据合并,也是我们在训练场景用的比较多的一种方式,把一个图片做成一个 chunk,chunk 里边再做一个下浮,我们可以做到指数级的降低文件的 Meta 信息,并对整个训练的效果都不会有太大的影响。
Alluxio 带来的效益
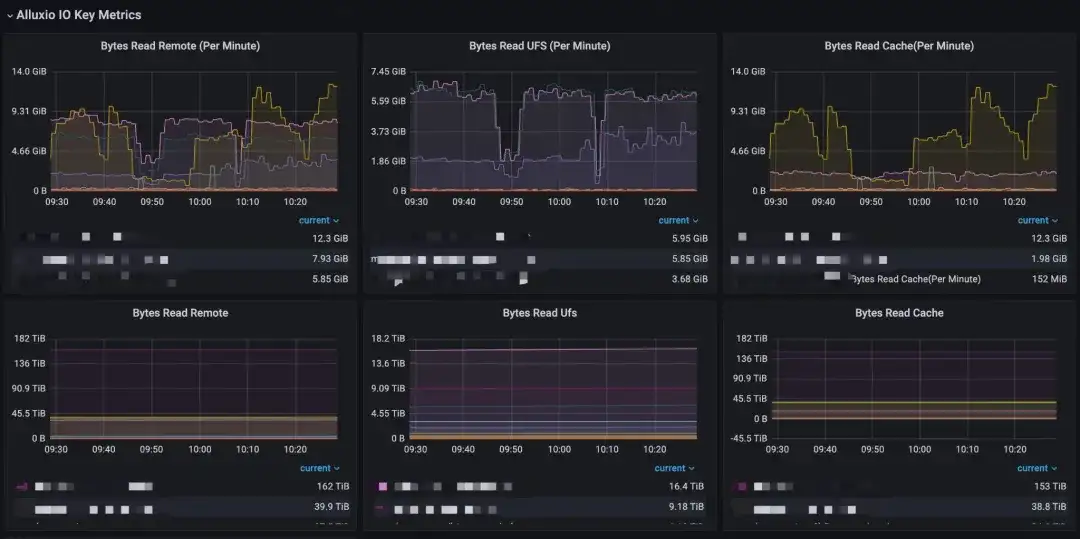
在我们实际应用过程中测下来,亿级别的单节点性能基本能达到 IOPS 在 3000+ 以上,整个业务包括我们的审核、大模型,都在用这一套,我们现在已经缓存的数据集大概在几百T规模左右。
三、未来规划
Alluxio 之前介绍过知乎的推理场景,这个场景B站也有比较大的痛点,所以我们也在尝试探索更多的可能。另外就是现在 Master 元数据管理是一个很痛的点,在这种场景下 Alluxio 最新的 Dora 框架可以带来多大的收益,也是需要我们进一步去调研的,同时,因为我们是一个机器学习平台,应用场景非常单一,我们也在跟B站的存储专业团队做一个更大规模、更通用的 Alluxio 解决方案,这是我们现在在做的,也是后续打算去推的。








