
最新的 MLPerf Storage v2.0 测试结果(文末“阅读原文”可跳转查看)显示,Alluxio 通过分布式缓存技术大幅加速了 AI 训练和 checkpointing 工作负载的 I/O 性能,在多种常见的由于 I/O 瓶颈导致 GPU 利用率不足的场景中,成功将 GPU 利用率提升至 99.57%。
虽然 GPU 本身算力极强,但其在 AI 训练中的实际效能取决于能否解决两个关键的 I/O 瓶颈问题:数据加载和Checkpointing(检查点保存)。我们曾在白皮书《Alluxio助力多GPU集群突破I/O瓶颈,高效释放AI算力》中提到,AI 训练基础设施的真正挑战并不在于算力,而在于如何避免因数据加载或模型 checkpointing 过慢而导致昂贵的 GPU 资源闲置。
I/O 加速至关重要,这是因为现代 AI 训练不但涉及在多个训练周期中反复读取海量数据集,还伴随着频繁保存百 GB 以上的模型状态。当 I/O 速度无法匹配 GPU 处理能力时,GPU 将处于空闲状态,不仅浪费每小时高达数千美元的计算资源,还会严重影响关键模型开发进度。因此,MLCommons 推出了 MLPerf Storage 基准测试,旨在以架构中立、有代表性、可复现的方式测量不同存储系统对机器学习(ML) 工作负载下的性能,此次发布是其最新的 v2.0 版本测试结果。
以下将探讨 Alluxio 的分布式缓存架构如何应对上述 I/O 挑战,分析其在最新版 MLPerf Storage v2.0 基准测试中的表现。
AI训练中的两大I/O瓶颈:数据加载和Checkpointing
模型数据加载:指将训练数据集从存储加载到 GPU 服务器的 CPU 内存的过程。当 PyTorch DataLoader、TensorFlow 的 tf.data 等框架发出混合顺序/随机读取请求时,存储系统往往难以维持稳定吞吐。在多周期训练场景下,同一海量数据集需被反复加载,进一步加剧了对 I/O 的压力。传统存储架构常产生难以预测的延迟峰值,导致 GPU 处于"饥饿"状态。当数据加载速度跟不上 GPU 处理速度时,将造成昂贵的计算资源闲置,显著拉长训练周期并推高基础设施成本。
模型 Checkpointing: 训练代码定期将模型状态写入磁盘的过程。当训练过程中发生故障时,可重新加载已保存的模型状态并从该时间点恢复训练。在 checkpoint 完成模型状态文件写入之前,训练计算会被暂停。大多数训练工作负载在每次迭代(即对单批数据完成完整训练)后执行 checkpoint。随着迭代进行,模型状态文件可能增长至数百 GB 甚至更大规模。因此,如果 checkpoint 写入因 I/O 缓慢而受限,端到端训练时间也会受到延误。
解读MLPerf Storage v2.0 基准测试
MLCommons 发布的新版 MLPerf Storage v2.0 测试结果,凸显了存储性能在 AI 训练系统中的关键作用。
测试模拟的训练工作负载如下,涵盖多个行业的常见 AI 模型训练类型,这些模型的训练负载涵盖了针对大、小文件的顺序读、随机读等多样化的 I/O 模式,旨在充分检验系统在不同 I/O 压力下的真实表现。
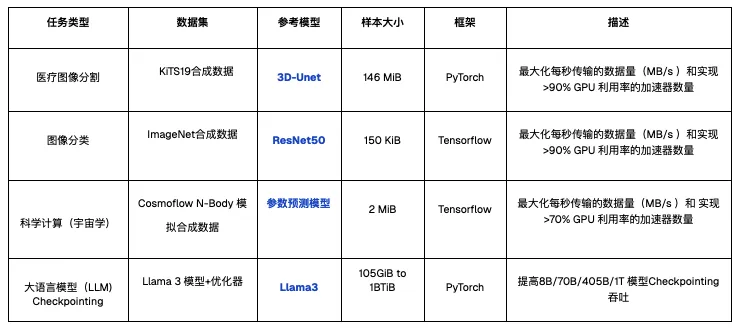
- 训练:读取带宽(GiB/s)
- Checkpointing:写入带宽(GiB/s)、写入时长(秒)、读取带宽(GiB/s)、读取时长(秒)
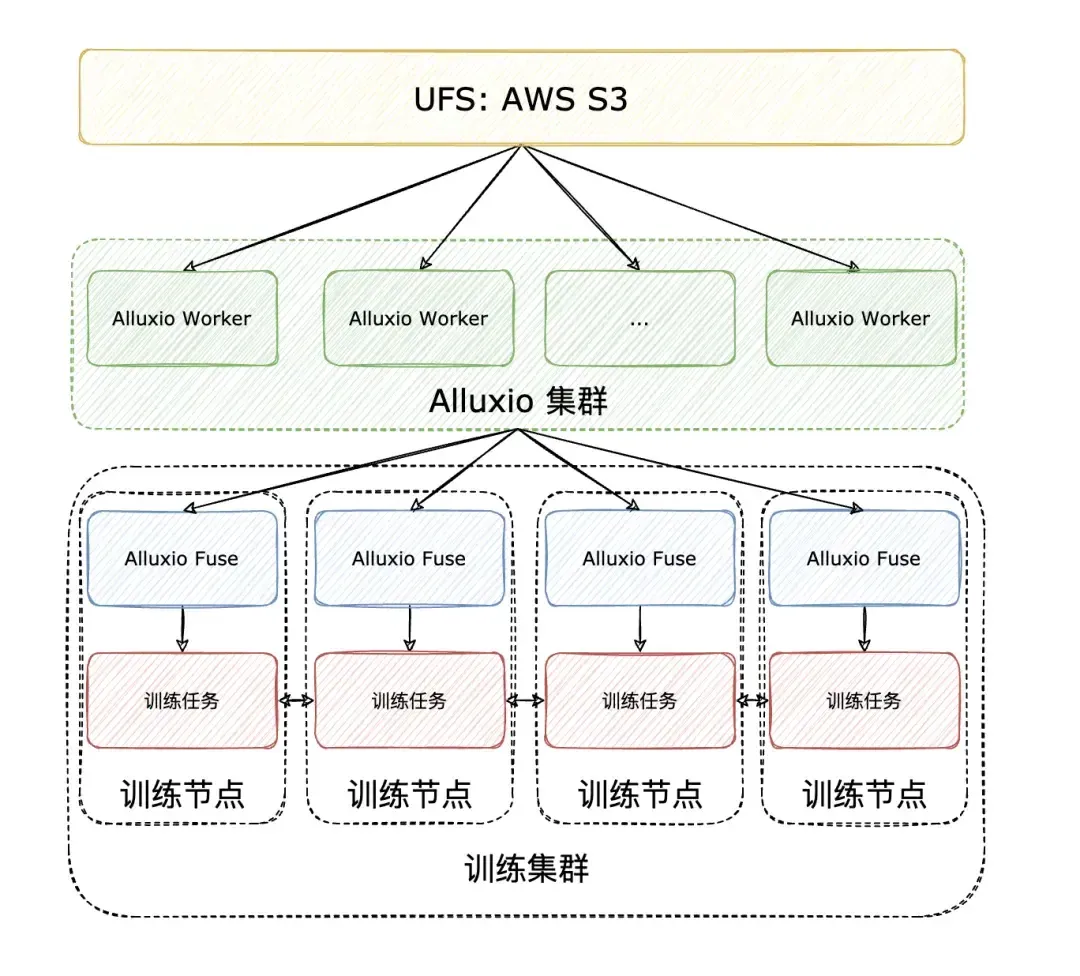
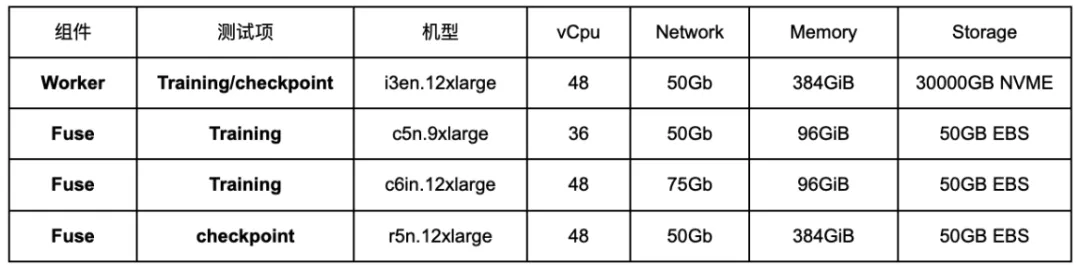
加速器利用率是衡量数据系统效率的黄金标准,也是 MLPerf 基准测试的核心要求。在此关键指标上,Alluxio 表现卓越:
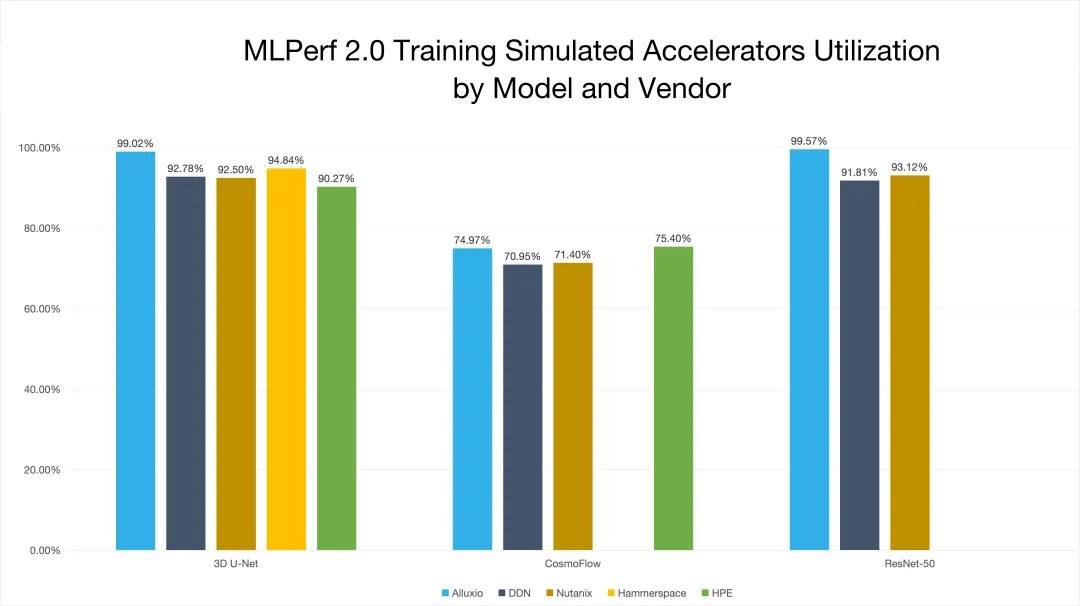
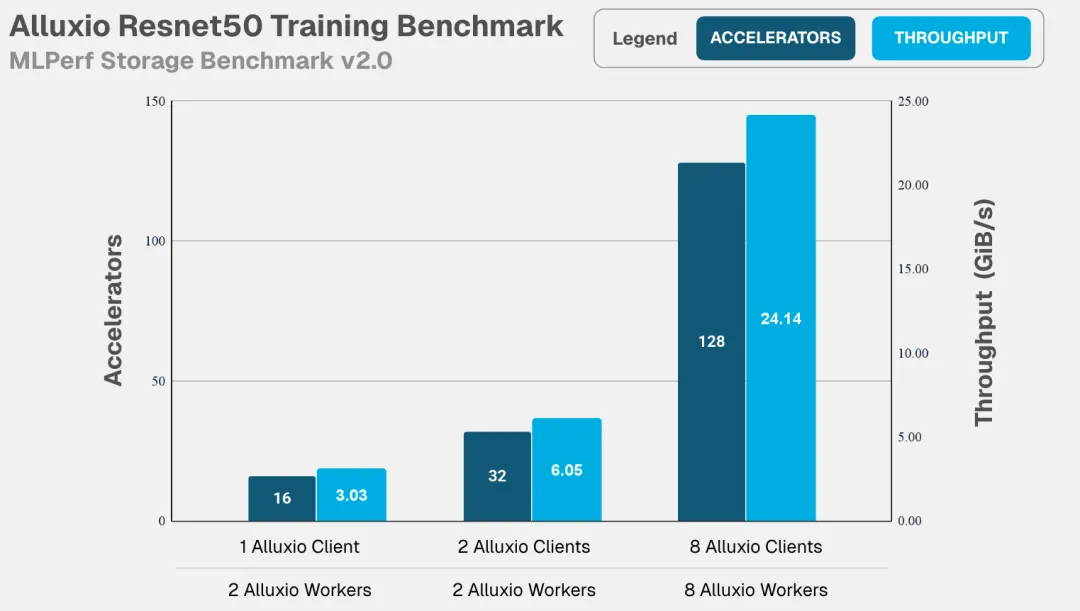
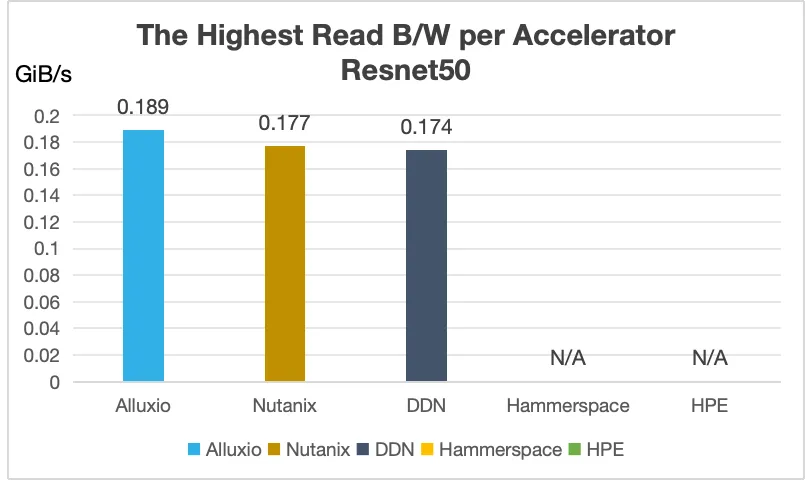
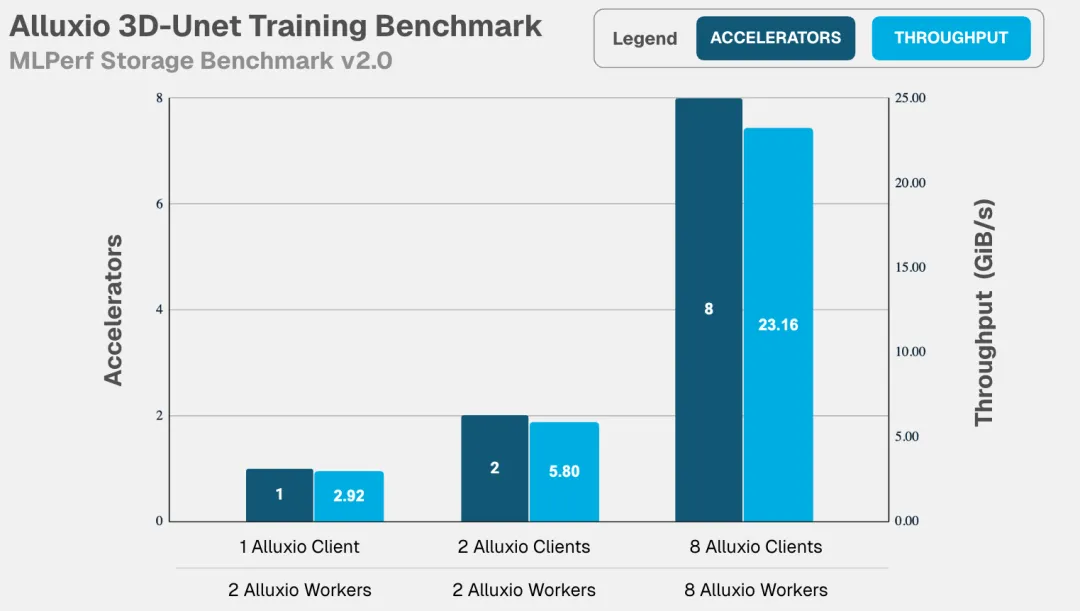
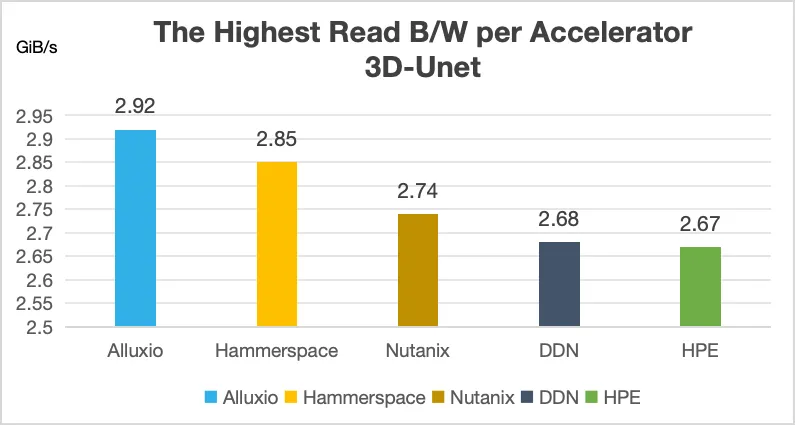
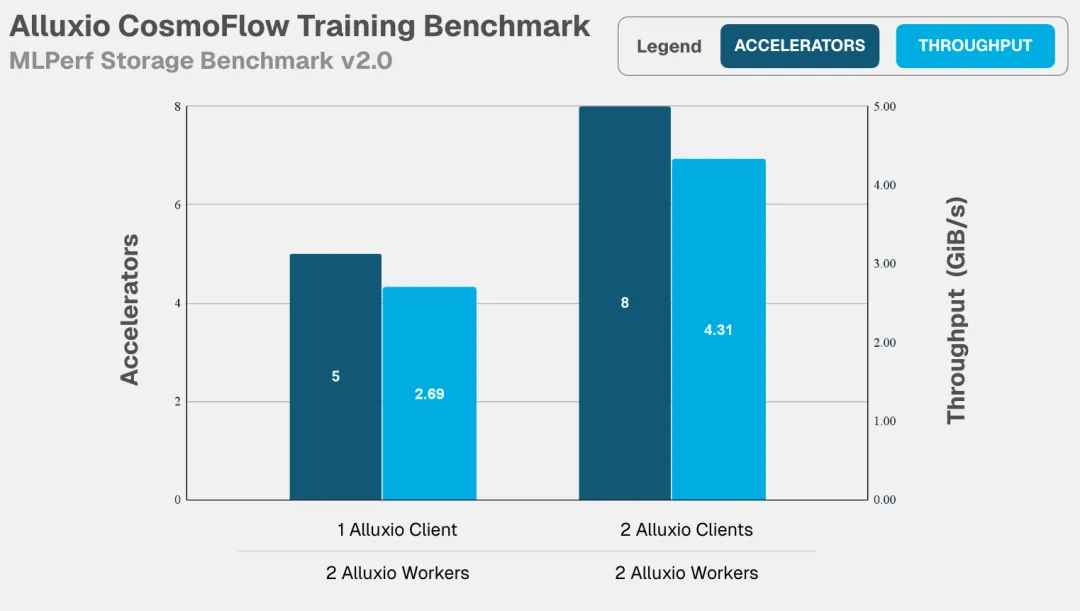
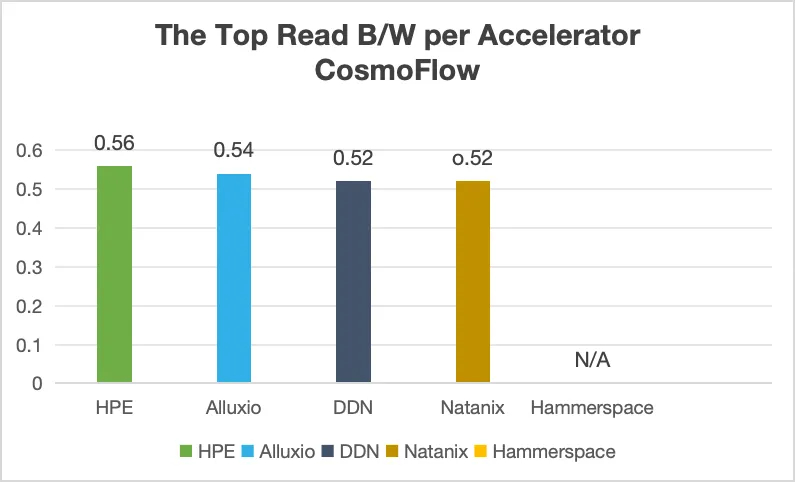
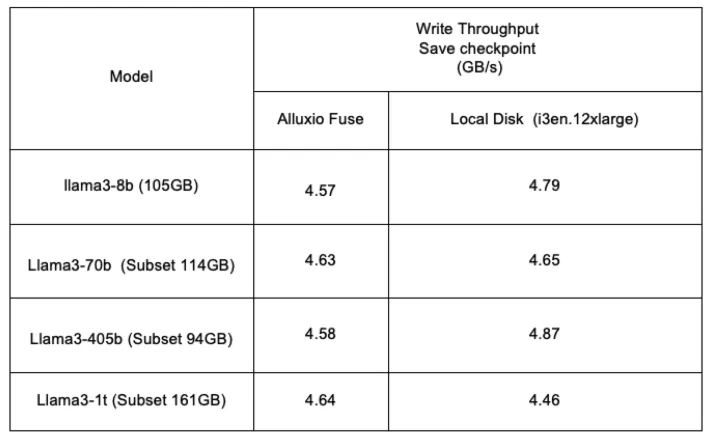
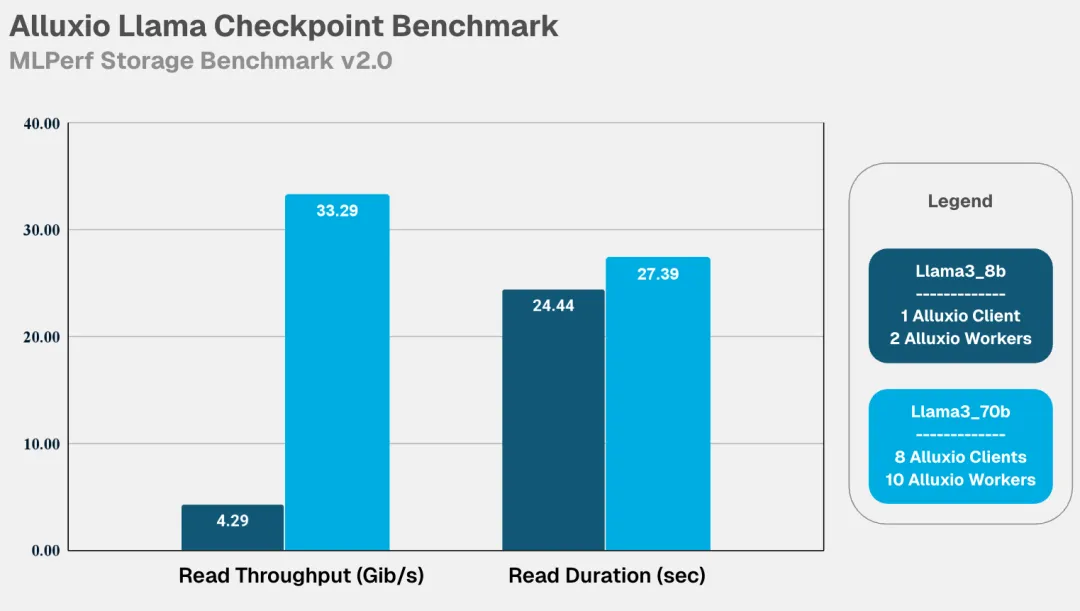
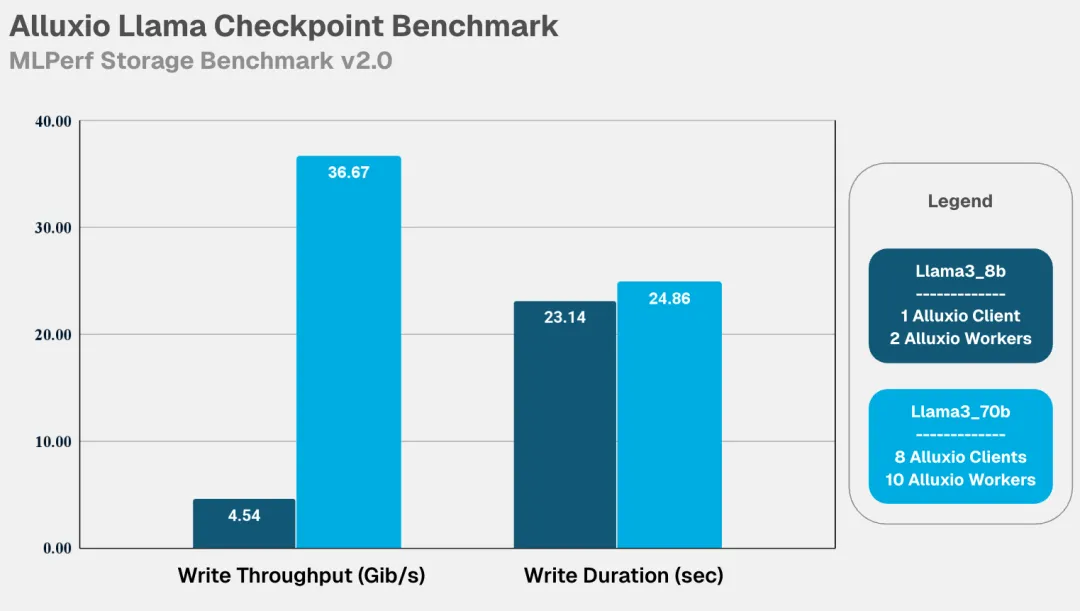
Alluxio表现出的核心优势
结语









