总体架构
急性子,想直接实操的,先绕过这个章节,直接看后边的实操步骤。把环境运行起来再看原理。Presto 的架构如下图所示,client 的请求,会递交给 Coordinator 进行处理,而元数据信息由 HiveMetaStore(HMS) 进行管理。那么表或分区的 location 信息,也在 HMS 中存放,因此,如果想把表或分区的数据放到其它存储系统里,则不得不修改HMS的信息,这增加了 HMS 的维护成本,而且HMS是全局共享服务,它修改了,其它计算框架就没有办法保持访问原来的路径了。
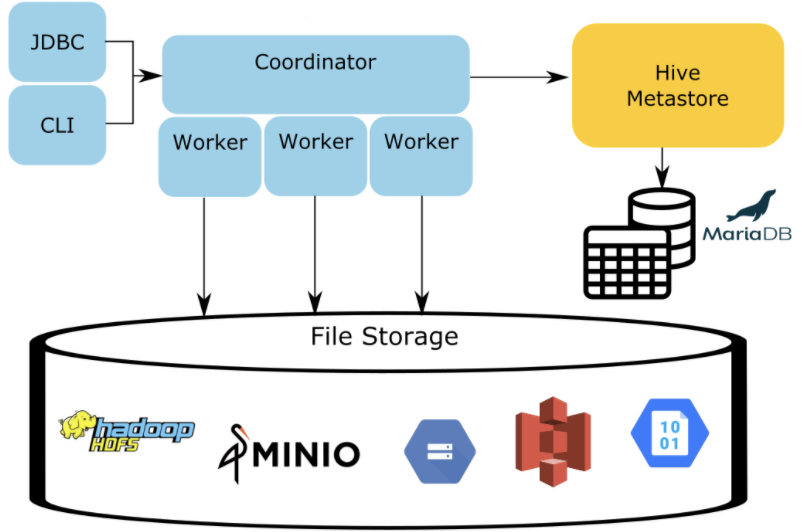
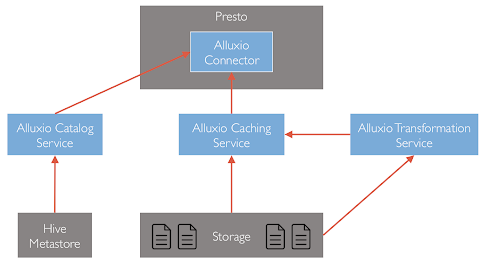
Alluxio Structure Data Service(SDS) 提供了一个位于 Presto 和底层 HMS 之间的服务,Presto 的 hive-hadoop2 connector 插件可以把 Alluxio master 当做 metadata服务,而 Alluxio master 中的 SDS 模块会与底层 HMS 通信,获取底层的 metadata,并且做一些处理,返回给 Presto 加工后的结果。Presto 拿到的位置信息,如果是 alluxio地址,则 Presto 将会从 Alluxio 读取数据,这样实现了不修改 HMS 也可以让 Presto 的访问转换到 Alluxio 的目的。
搭建过程
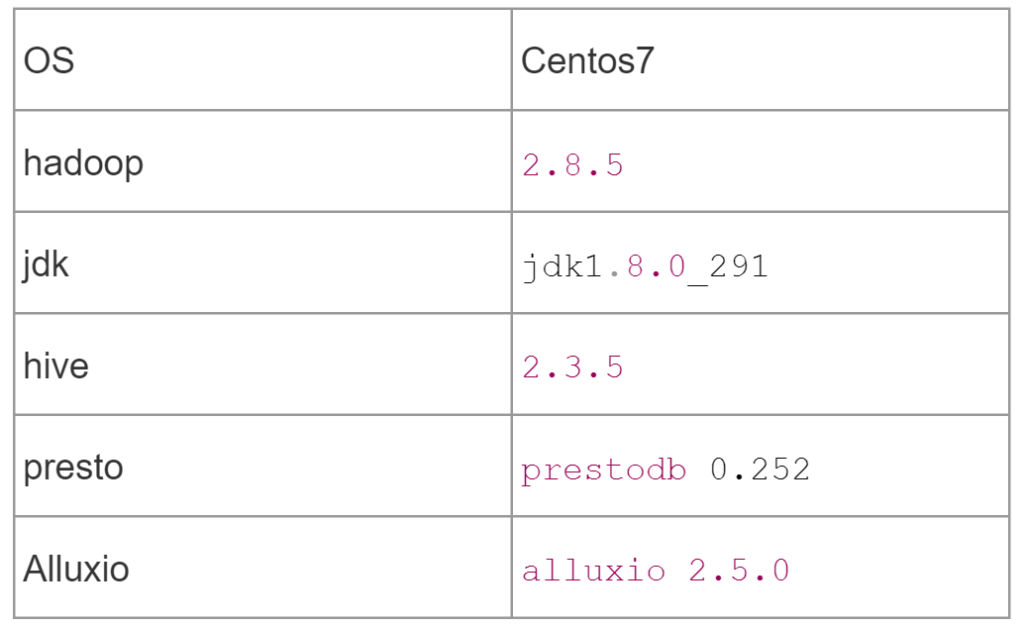
本文用以下软件环境进行搭建。由于 hive、presto、alluxio 都是以 hadoop 兼容文件系统 API 进行文件系统访问,因此底层存储,可以是本地,也可以是 hdfs 。本文重点并不是存储系统,因此使用 file sheme,以本地存储为底层存储。如果想使用 hdfs 进行搭建,可以参考“可选项”章节。
配置环境变量
export HADOOP_HOME=/softwares/hadoop-2.8.5 export JAVA_HOME=/usr/java/jdk1.8.0_291-amd64/ export HIVE_CONF_DIR=/softwares/apache-hive-2.3.5-bin/conf export HIVE_AUX_JARS_PATH=/softwares/apache-hive-2.3.5-bin/lib export HIVE_HOME=/softwares/apache-hive-2.3.5-bin
搭建过程
搭建 mysql
# 使用主机网络,或导出端口 docker run --net=host -p 3306:3306 --name mysql -e MYSQL_ROOT_PASSWORD=123456 -d mysql:5.7 # 创建 hive 用户,密码为 hive create database metastore; grant all on metastore.* to hive@'%' identified by 'hive'; grant all on metastore.* to hive@'localhost' identified by 'hive'; flush privileges;
安装 Hive 和 mysql connector
wget https://archive.apache.org/dist/hive/hive-2.3.5/apache-hive-2.3.5-bin.tar.gz
tar -xzvf apache-hive-2.3.5-bin.tar.gz
mv apache-hive-2.3.5-bin /softwares/
mv mysql-connector-java-5.1.38.jar /softwares/apache-hive-2.3.5-bin/lib以下是相关的配置文件设置
- conf/hive-env.sh
export METASTORE_PORT=9083- hive-site.xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://127.0.0.1:3306/metastore?createDatabaseIfNotExist=true&characterEncoding=UTF-8&useSSL=false</value>
<description>JDBC connection string used by Hive Metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>JDBC Driver class</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>Metastore database user name</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
<description>Metastore database password</description>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://127.0.0.1:9084</value>
<description>Thrift server hostname and port</description>
</property>
</configuration>启动 MetaStore
bin/schematool -dbType mysql -initSchema hive hive
bin/hive --service metastore -p 9083hive 创建 schema 和 table
- /root/testdb/person/person.csv 文件
mary 18 1000
john 19 1001
jack 16 1002
luna 17 1003create schema test;
create external table test.person(name string, age int, id int) row format delimited fields terminated by ' ' location 'file:///root/testdb/person';
搭建Presto
安装高版本 JAVA
# download jdk rpm package
yum localinstall jdk-8u291-linux-x64.rpm
alternatives --config java安装 Presto
wget https://repo1.maven.org/maven2/com/facebook/presto/presto-server/0.252/presto-server-0.252.tar.gz
tar -xzvf presto-server-0.252.tar.gz
mv presto-server-0.252 /softwares/
mkdir -p /softwares/presto-server-0.252/etc/catalog
# 以下这些配置文件,都需要创建和配置
tree /softwares/presto-server-0.252/etc
├── catalog
│ ├── hive.properties
│ └── jmx.properties
├── config.properties
├── jvm.config
├── log.properties
└── node.properties准备配置文件
- node.properties
node.environment=production
node.id=node01
node.data-dir=/softwares/presto-server-0.252/var/presto/data- config.properties
coordinator=true
node-scheduler.include-coordinator=true
http-server.http.port=8080
query.max-memory=2GB
query.max-memory-per-node=1GB
discovery-server.enabled=true
discovery.uri=http://localhost:8080- jvm.config
-server
-Xmx4G
-XX:+UseConcMarkSweepGC
-XX:+ExplicitGCInvokesConcurrent
-XX:+CMSClassUnloadingEnabled
-XX:+AggressiveOpts
-XX:+HeapDumpOnOutOfMemoryError
-XX:OnOutOfMemoryError=kill -9 %p
-XX:ReservedCodeCacheSize=150M- log.properties
com.facebook.presto=INF0- node.properties
connector.name=hive-hadoop2
hive.metastore.uri=thrift://localhost:9083运行 Presto Server
bin/launcher start运行 presto cli
wget https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.252/presto-cli-0.252-executable.jar
chmod +x presto-cli-0.252-executable.jar
mv presto-cli-0.252-executable.jar /softwares/presto-server-0.252/
./presto-cli-0.252-executable.jar --catalog hive --schema test
show schemas from hive;
show tables from hive.test;
select * from hive.test.person;
select count(*) from person;
搭建 Alluxio
安装 Alluxio[略]
- alluxio-site.properties
运行 Alluxio[略]
bin/alluxio-start.sh master
bin/alluxio-start.sh worker
Attach catalog
# 执行 attachdb 命令,会进行挂载 schema
bin/alluxio table attachdb hive thrift://localhost:9083 test
重配 Presto 使用 Alluxio SDS
修改 catalog 配置
- etc/catalog/hive.properties
# connector 还是 hive-hadoop2 是因为 presto 的hive-hadoop2 插件已经支持了访问 Alluxio 的功能
connector.name=hive-hadoop2
hive.metastore=alluxio
hive.metastore.alluxio.master.address=localhost:19998重启 Presto Server
bin/launcher stop
bin/launcher start运行 presto cli
./presto-cli-0.252-executable.jar --catalog hive --schema test
show schemas from hive;
show tables from hive.test;
select * from hive.test.person;
select count(*) from person;观察运行完 sql,对应的 person.csv 文件已经完全被加载到 Alluxio 中了。
可选项
搭建 hdfs(如果需要,可以搭建hdfs)
如果希望数据放到 hdfs,则可以搭建 hdfs
create schema test_hdfs;
create external table test_hdfs.person(name string, age int, id int) row format delimited fields terminated by ' ' location 'hdfs://localhost:9000/root/testdb/person';
./presto-cli-0.252-executable.jar --catalog hive --schema test_hdfs
show schemas from hive;
select * from hive.test_hdfs.person;总 结
利用 Alluxio SDS,底层的 HMS 中的分区表的 location 无需修改,也就是 HMS 没有任何改变,其它计算引擎完全没有变化。而 Presto 通过 Alluxio SDS 提供的元数据服务,可以进行一些定制化的改造,比如某些分区或表不经Alluxio访问,可以返回 原始的 location 信息。
展 望
Alluxio SDS 在 Presto 和 HMS 之间,搭建了一个 Catalog 代理服务,基于此,Alluxio 理解了数据的格式,因此可以做一些数据格式转换,比如 csv 转 parquet,小文件合并。如果还有其它的需求和好想法,也可以进行改造和开发。此外,可以根据本文,实现一个 All-in-one 的 docker image,让更多的公司可以体验到 Alluxio SDS 功能,将会有更多的开发者一起共建这个意义重大的特性。








