 |
| Inferless 借助 Alluxio 实现大语言模型部署 10 倍提速,冷启动时间 10 倍缩短。 |
扩展 LLM 推理基础设施面临的 I/O 挑战
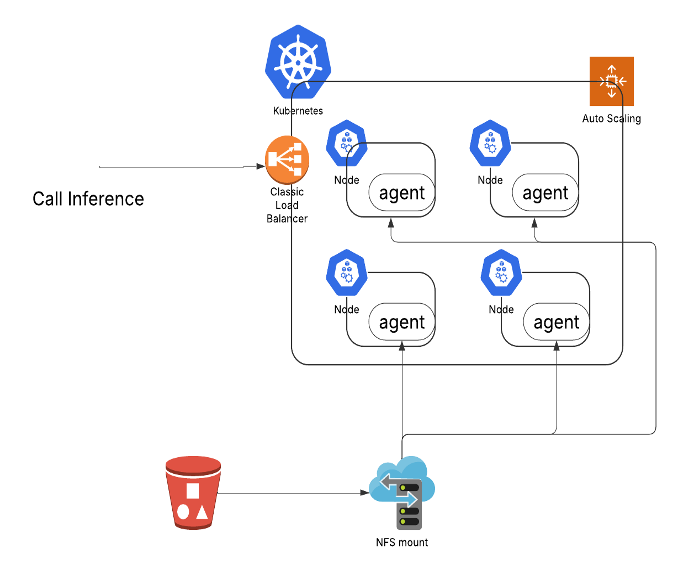 |
| LLM推理的基础架构 |
在扩展 LLM 推理架构过程中,我们主要遇到了以下瓶颈:
通过 Alluxio 将模型加载速度提升10倍
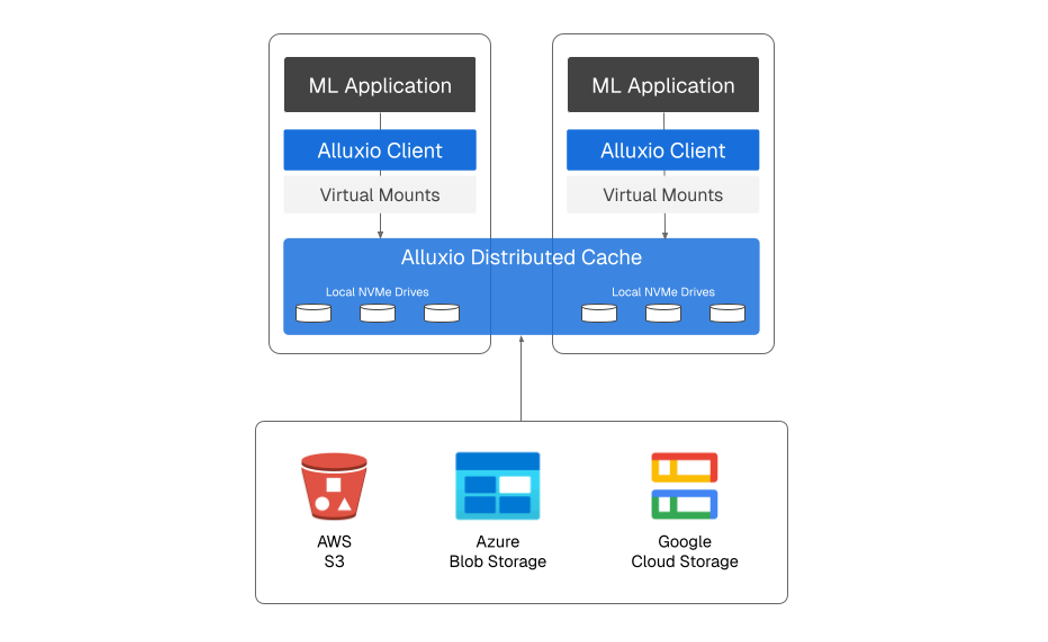 |
| 基于Alluxio的三层存储架构 |
热存储层(Alluxio)——支持POSIX文件接口的本地NVMe
温存储层(Warm Tier)—— 集群内文件共享
冷存储层(Cold Tier) —— 云对象存储 (S3, Azure Blob, GCS)
性能基准
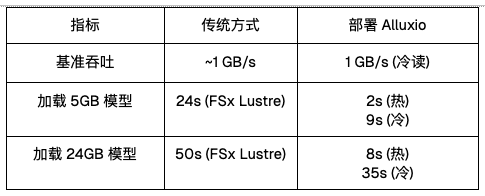 |
| 性能基准 |
效果显著:LLM服务性能实现质的提升
部署 Alluxio 后,我们的 LLM 服务性能实现了根本性提升。从过去模型初始化需花费数分钟,到如今只需数秒,实现了真正的按需扩展,大幅改善了客户体验。








