 |
| 将现有的云对象存储升级为面向 AI 的高性能存储,实现亚毫秒级延迟、Alluxio单集群达到TB/s 级吞吐与线性扩展性能——无需迁移任何数据。 |
云对象存储(Amazon S3,GCS,Azure Blob,阿里云OSS等)是现代数据平台的支柱——性价比高、持久可靠、扩展性强。随着 AI 时代的到来,AI 工作负载对存储提出了更高要求:亚毫秒级响应时间、支持追加写(append)与更新操作、并能在跨云与本地数据中心无缝扩展。Alluxio 正是为此而生。它为对象存储提供高性能的数据加速层,在保持 S3 的扩展性、持久性与成本优势的同时,带来支持下一代 AI 工作负载所需的速度与效率。
为什么仅靠云对象存储不足以支撑AI?
通过Alluxio赋能云对象存储, 加速AI工作负载
 |
| 客户验证:Alluxio 在 AI 场景中的真实表现 |
面向LLM的数据湖智能体记忆
低延迟特征存储
模型训练与调优
Alluxio 核心指标与性能基准
 |
| 首字节延时(TTFB):数值越低越好 |
 |
| 吞吐量(GiB/秒):数值越高越好 |
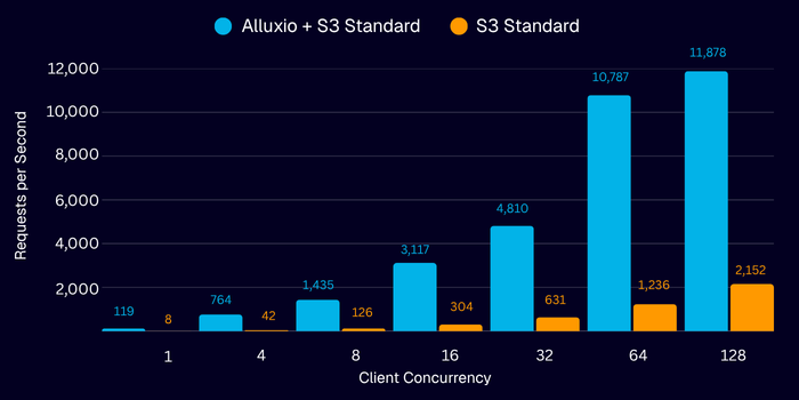 |
| 操作并发度(每秒操作次数):数值越高越好 |
结论
👉 继续将 S3 作为唯一的真实数据源(Source of Truth)
👉 叠加 Alluxio,实现极致吞吐与超低延迟的 AI 体验








