大规模训练中被忽视的 checkpoint 隐性成本
如今,分布式训练的大量时间并非用于模型迭代,而是消耗在 checkpoint 的写入与等待上。
每个 checkpoint 周期,都需要数百张 GPU 将数百 GB 的模型参数同步写入后端存储。像 PyTorch Distributed Checkpoint、DeepSpeed 和 Megatron-LM 这样的主流框架,都会通过 POSIX 文件系统接口来执行 checkpoint 操作,这意味着其写入路径必须经过挂载在训练节点上的共享文件系统。当该文件系统由对象存储或远程并行文件系统提供支持时,每一次 checkpoint 落盘都会变成一项受网络带宽限制的操作,从而导致整个训练任务陷入停滞,直到最慢的那个计算节点完成写入。
这种下游效应会不断叠加并产生复合影响。 写后即读的下游场景——任务重启恢复、微调续训、评估任务读取刚写完的 checkpoint——都会重复同样的高延迟问题
针对这一核心挑战,Alluxio AI 3.9 应运而生。
Alluxio AI 3.9 新特性
Alluxio AI 3.9 引入了两个全新的功能特性:
- POSIX 写缓存:扩展了 Alluxio 的写入缓存架构。该架构最初在 3.8 版本中针对 S3 工作负载引入,现已延伸至 POSIX 文件系统接口,而几乎所有的分布式训练框架都在使用该接口。
- RDMA 读加速:为读路径增加了 RDMA(远程直接内存访问)传输支持,从而在具备 RDMA 能力的训练集群上实现接近线速的吞吐量。
POSIX 写缓存:全面加速训练技术栈写入能力
回顾:AI 3.8 版本推出 S3 写缓存
Alluxio AI 3.8 推出 S3 写缓存,它的核心思想是:应用写入不再受对象存储的速度限制——写操作先落到 Alluxio Worker层所在的本地 NVMe 上,再异步刷到 S3。该版本大幅降低了 S3 场景下 AI 工作流的 PUT 延迟和写后即读(read-after-write )延迟。
痛点:训练场景依赖 POSIX 接口
然而,分布式训练并不是通过S3进行写入,而是统一使用 POSIX 接口。PyTorch、DeepSpeed、Megatron、Ray Train 等框架及其配套存储工具,均依赖挂载式文件系统。在此之前,训练团队可以通过 Alluxio 的 POSIX FUSE 接口来加速读取,但却缺乏同等的写入端加速 —— checkpoint 的写入仍然需要同步跨越网络传输到后端存储。
AI 3.9 持续升级:POSIX 写缓存填补空白
Alluxio AI 3.9 新增 POSIX 写缓存特性,将 3.8 版本中的写回缓存架构(先写本地缓存、再异步持久化至后端存储)延伸到了 POSIX 路径中:
- 训练任务把 checkpoint 写入通过 POSIX 挂载的 Alluxio 文件系统;
- 写入数据会直接落在 Alluxio worker 基于计算侧 NVMe 盘组建的缓存池上;
- 数据异步持久化至后端底层存储,全程不阻塞训练进程。
对训练框架而言,一切如常。文件系统挂载的工作方式与之前完全一致,唯一变化是写入速度实现质的飞跃。
为何 checkpoint 会拖慢 GPU 训练?
GPU 训练的“经济账”让 checkpoint 的延迟变得格外昂贵:
- 一个拥有 70B 参数的模型,其 checkpoint 文件大小可超过 250 GB。
- 当该 checkpoint 通过远程文件系统进行同步写入时,整个训练步骤都会阻塞在集群中最慢的那个写入节点上。
- 成百上千张 H100 GPU 被迫空转,I/O 等待时间直接吞噬训练收益。
这不是偶发的突发负载问题,而是贯穿整个训练过程的持续性问题:绝大多数的大规模训练任务,每隔数百至数千步就会执行一次 checkpoint 操作,这意味着存储写入路径在整个训练过程中都在被反复压测。缓慢的 checkpoint 不仅会拖慢故障恢复时间,还会直接拉低有效训练吞吐量。
POSIX 写缓存从两个方面破解了这一难题:
- 写入速度:从受限于网络传输速度,提升至接近本地 NVMe 盘的写入速度;
- 写后即读:诸如故障/错误重启、断点续训、下游数据消费等任务,同样能够以本地 NVMe 的速度高速执行。
性能实测:单节点 7.6 GiB/s,三节点线性扩展至 20 GiB/s
为了验证 POSIX 写缓存在真实的、类似于 checkpoint 工作负载下的性能表现,我们采用 256KB 块大小,通过 FIO 工具对 Alluxio POSIX 接口进行了基准测试。
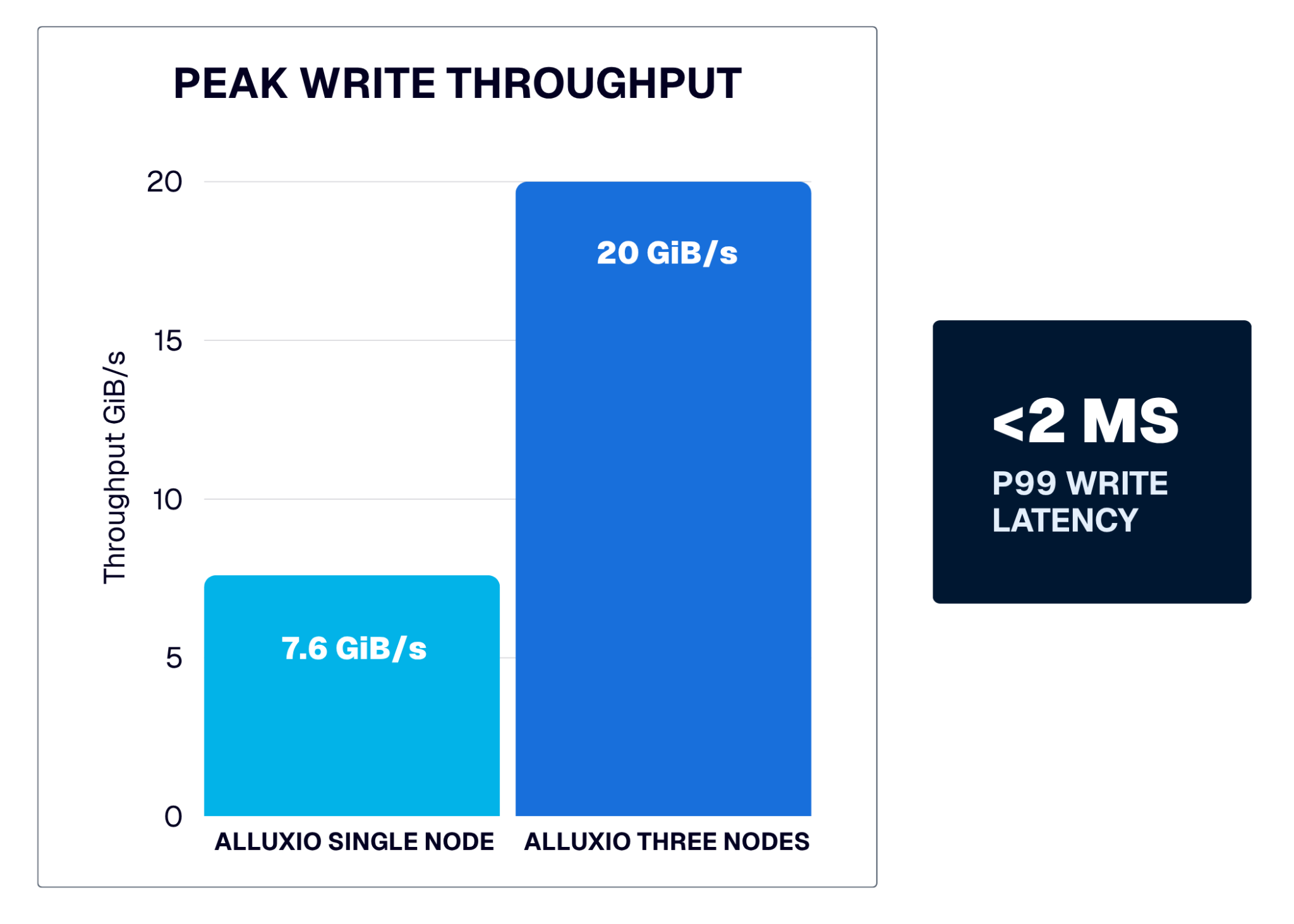
图 1:Alluxio AI 写缓存基准测试结果
(Alluxio 集群:worker-i3en.24xlarge; client-c5n.18xlarge)
关键测试结论:
- 吞吐量接近线性扩展:随着 worker 数量增至 3 倍,总吞吐量提升约 2.6 倍,这证实了性能可随计算层同步增长,不再受限于后端存储。
- P99 延迟稳定可控:两种集群规模下,P99 延迟均稳定低于 2ms。对 checkpoint 工作负载而言,决定同步 checkpoint 步骤耗时的是尾部延迟,而非平均延迟,因为整个任务的进度受限于那个最慢的计算节点。
为 AI 团队带来的核心收益
对分布式训练团队而言,POSIX 写缓存可直接带来四大核心收益:
- 更快 checkpoint 周期:无需牺牲训练吞吐量,即可提高 checkpoint 频率,降低任务故障损失;
- 更快的任务恢复与续训:在遭遇节点抢占、硬件故障或计划内重启后,能够实现更快速的任务恢复与断点续训。
- 更高的GPU 实际利用率:通过消除同步 checkpoint 写入期间的 GPU 闲置时间,可显著提升 GPU 的有效算力利用率。
- 突发 I/O 下的稳定性能表现:由于高并发写入会被 Alluxio 缓存层直接吸收,而不会在后端存储排队积压,从而确保了性能的可预测性与稳定性。
Alluxio 提供对 RDMA 读加速支持
Alluxio AI 3.9 同时为读 I/O 加速引入 RDMA 传输能力,适配搭载 InfiniBand 或 RoCE v2 网络的 GPU 集群。通过绕过内核网络协议栈,RDMA消除了数据路径上的 CPU 开销与内存拷贝,从而在训练和推理过程中让 GPU 始终保持满载状态。该版本将 RDMA 加速应用到了客户端与 Alluxio worker 之间所有的 FUSE 客户端读取 I/O 中,同时也涵盖了诸如文件状态(file status)和目录列表(directory listing)等元数据操作。
基准测试结果表现强劲。在配备了 Mellanox ConnectX-6 和 ConnectX-7 网卡的 Azure 虚拟机上,RDMA 在 200 Gbps InfiniBand 网络下达到了 23.2 GB/s 的吞吐量 —— 占链路容量的 92.8%;而在 400 Gbps NDR 网络下达到了 49.5 GB/s —— 占链路容量的 99.0%。同时,尾部延迟表现也十分亮眼:在 4KB 小文件读取中,P99 延迟保持在 100 微秒(µs)以内(200G 网络下为 64µs,400G 网络下为 59µs)。这对于 checkpoint 元数据访问以及单次操作开销占主导地位的小文件训练数据集而言,至关重要。
RDMA 与 TCP 的对比最清晰地体现了该协议的优势。在峰值带宽利用率下,RDMA 达到了 92.8%,而 TCP 仅为 76.8% —— 实现了 16 个百分点的效率优势。在生产级的并发规模下,这一差距进一步扩大到了 24 到 29 个百分点。这是因为当并发数超过 16 后,TCP 的性能就会开始劣化,而 RDMA 则能够继续保持线性扩展。
RDMA 传输采用的是附加式设计,它可与标准的 TCP 传输共存。如果 RDMA 硬件不可用,系统会自动回退到 TCP 模式,并且整个过程不需要进行任何数据迁移或 API 变更 —— 现有的 FUSE 挂载和兼容 S3 的访问路径均可继续正常工作。写入侧的 RDMA 支持将在后续版本推出;在当前的 3.9 版本中,写入 I/O(包括 POSIX 写缓存)仍将继续使用 TCP 传输。
总结
Alluxio AI 3.9 继续承接 3.8 版本的演进路线:
- 3.8 版本:S3 写缓存,解决云原生工作流中的对象存储写入瓶颈;
- 3.9 版本:POSIX 写缓存,直击分布式训练核心痛点 —— 阻塞 GPU 训练的同步 checkpoint 写入瓶颈。
凭借单个工作节点 7.6 GiB/s 的吞吐量、跨三个工作节点线性扩展至 20 GiB/s 、P99 延迟稳定低于 2ms的优异表现,Alluxio 让 checkpoint 写入不再成为训练步骤中的短板!
准备好从您的训练基础设施中消除 checkpoint 瓶颈了吗?欢迎申请演示以观看 Alluxio AI 3.9 的实际运行效果,或者在《Alluxio S3 写缓存介绍》中阅读关于写缓存架构的技术深度解析。








