作者简介
邱 璐:机器学习工程师@alluxio,Alluxio PMC maintainer, 有多年开源贡献经验。Alluxio机器学习、深度学习、POSIX API方向负责人。熟悉Alluxio选举机制、日志、指标系统等核心组件。
孙守拙:毕业于杜克大学计算机系,目前在Alluxio研发团队担任研发工程师,主要负责机器学习场景下的数据供给开发,及Alluxio的容器化应用。
活动回顾
越来越多的公司在其机器学习平台中运用开源系统Alluxio加速训练任务的数据读取。为了帮助用户在机器学习场景下熟悉和部署Alluxio集群,更快的进行性能测试、分析以及调优,我们邀请到Alluxio团队的核心开发工程师邱璐和孙守拙介绍Alluxio在机器学习场景下的最佳实践。针对此场景下常见的海量数据、海量(小)文件、高度并发等数据挑战。
在【Machine Learning+Alluxio】系列活动中,介绍讲述了Alluxio在机器学习场景下部署、测试、调优的最佳实践。
我们将对以下内容进行探讨:
① 合理的Alluxio资源配置和参数设置
② 如何使用Alluxio内建工具一键自测试其POSIX API性能指标
③ 如何对集群的POSIX API排查故障、分析性能瓶颈并进行系统调优
(以下为本次活动的演讲实录)
Part 1 Alluxio在ML/AI学习场景下的最佳实践
Alluxio概览

相信很多人都非常熟悉, Alluxio是可以对各种不同的数据源,包括阿里云、腾讯云的数据进行缓存,以提升各种训练的性能,它上面包括了像PyTorch, Tensorflow等一系列训练的软件。
分布式缓存

而Alluxio与很多的缓存解决方案的不同点就在于我们其实是一个分布式缓存,数据如果在一台机子上放不下,我们把它分到多台机子上,共同为大家提供缓存功能。
统一命名空间
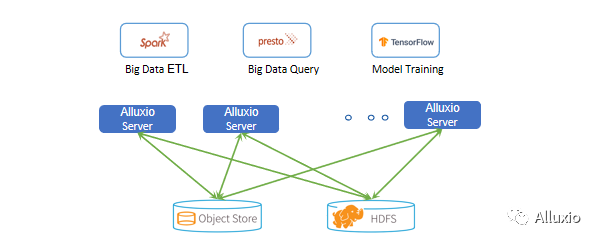
同时Alluxio提供一个统一的命名空间,来自不同的数据源的数据,都可以在Alluxio统一命名空间之下得以展示及使用。所以我们的各种应用就像使用同一个文件夹里面的文件一样,来使用各种来自不同数据源的数据。
多种API适用于不同场景

同时,Alluxio提供多种不同的API适用于不同的场景。在我们的训练场景下,提供了POSIX API,让训练可以像使用本地文件夹一样去使用我们的远端数据源。
通过Alluxio本地部署在训练集群加速I/O

首先应该如何去部署Alluxio,建议把Alluxio与我们的训练尽可能地部署在同一个机房里或者同一个集群中,这样我们训练读取来自Alluxio中的数据会更加的快,训练的I/O速度越快,训练性能可能会越好。在其他情况下,如果训练和Alluxio部署在同一个机房,甚至同一个地区也有助于我们对远端数据源进行缓存加速。
如何在云端部署Alluxio

机器学习场景下的挑战

提到机器学习训练场景,其实这个场景跟以往的大数据场景有非常多的不一样。主要体现在这几个不同点上。
训练数据更可能是海量的小文件,小图片,比如说陌陌,我们的用户有多于20TB的数据量,都是各种的图片,包括一些视频网站用户通过图片的形式存视频,文件数量极其庞大,而训练的数据规模很可能超过单机可用的存储容量,现在这个时代基本上上TB的数据量是非常正常的。
很多用户提出有超过TB级别的数据量需求,同时机器学习场景下,我们对训练的实时性要求非常的高,希望这个训练尽可能快,单机已经无法满足我们对训练时效的要求,所以就导致可能需要一个高并发度的分布式训练任务,这种训练任务还要求I/O有高吞吐。Alluxio的性能优化针对的是我们机器学习场景中的主要需求,海量小文件,分布式高并发以及读场景,这也是大量用户在实践中使用的一个场景。
Part 2 Alluxio性能优化
01 海量小文件读场景性能优化资源配置
Master内存

Master其实有几大资源块,其中一个是内存,一个是CPU。Master主要是存储元数据的节点,它保存文件的元数据信息,而且Master也需要能支援client worker所有的连接线程所需要的空间,就是一方面要保存这个元数据信息,另一方面要能支援client和worker想要获得这种元数据信息的所有的线程资源。
在保存数据信息方面,有两种方式,一方面是HEAP metastore,元数据是保存在内存当中,而另一方面可以使用ROCKS off-heap metastore。也就是我们的元数据不光保存在内存中,也保存在磁盘中,而这种方式是默认配置,并且推荐使用。特别是在海量文件的场景下,元数据的量非常的庞大,而ROCKS这种方式,因为磁盘的容量非常的大,其实可以存储更多的元数据,而不用担心Master可能存不下的问题。各大科技公司使用 alluxio 进行训练的时候也是设置ROCKS off-heap metastore。
我们要支持我们的客户端以及worker节点来向Master做索要元数据的各种操作所需要的内存。因为每个线程都是需要占用一定的内存空间的,在高并发的情况下,可能会有成千上万的并发的连接线程,需要给到足够的空间,以减少线程池的内存压力,来提高响应速度。而至于需要多少内存,可以通过一个指南,计算所需要的内存空间,但是无法非常准确地预计大家需要多少的内存空间。建议设置一个比较合理的值,比如说64GB或者更高的一个值,大家再实际监控内存的使用情况。如果大家发现我们的内存使用率非常的高,而且频繁GC,就调大这个数值,而如果我们发现可能内存设太多了,根本用不到这么多内存,那再把这个数值调小,就是前一两周进行内存的监控,调到一个合适的数值。
Master CPU

另一方面是Master端的CPU资源,CPU资源决定Master处理并发请求、并行递归操作以及周期性工作的能力。而在海量小文件场景下,Master CPU其实是决定了我们能处理多高并发的海量元数据请求。建议最低要求是4个core,在生产中至少把它打到16或者到32个core,可以根据所需元数据的ops计算基本配置,并且动态调整。
CPU资源的监控包括几个方面,一方面可以通过Master指标进行监控,可以看有多少请求正在等待处理Master metrics:RpcQueueLength,就是有多少个请求正在等待被处理,可能Master只能处理一秒钟10个请求,而你却有一秒钟20个请求,那就有10个请求在不停地累加到你的处理的等待池中,这样显然是一个不太健康的情况。另一方面可以去看Master元数据操作到底耗时多少,Master端的每一个元数据操作,我们都会对它进行时间的指标记录。如果这个元数据操作的耗时远远大于业务需求的话,那可能就是存在元数据跟不上需求的情况,可能也来源于CPU资源不够的情况。另一方面可以对RPC进行一个指标追踪,比如说Worker RPC可能一共花了一秒钟,但是在Master端可能只花了几十毫秒,剩下的时间都在等待,那就要想这个等待是来源于网络,还是来源于Master CPU资源的竞争。
Worker内存

提到worker内存,worker会使用off-heap来存储worker的元数据,所以这方面是无需过多的内存资源。所以我们认为worker的元数据,64兆基本上绰绰有余,但是worker之所以需要内存,是因为在worker进行传输数据的时候,会消耗大量的heap或者direct memory资源,其实是会影响到数据传输的并发度的问题。我们会建议根据读写并发度确定一个初始值,比如16GB和32GB,然后像类似监控master一样来监控worker的内存使用情况并动态调整。
Worker CPU

而worker的CPU也决定worker同步处理I/O请求的能力。在海量小文件场景下,我们要确保有足够的CPU资源来响应高并发数据请求,特别是每读写一个文件,可能都会发一个RPC请求,RPC请求是需要有足够的CPU资源在背后予以支撑的,可以跟着指南计算基本的配置,至少8-16 vCore,然后根据监控再动态调整。
Worker存储

Worker的存储,这主要指的是Alluxio用什么样的存储介质以及存储大小来缓存底层存储系统的一些数据,默认是用内存来进行存储的,但是如果是在海量数据的情况下,建议配置磁盘,用磁盘来进行数据存储更多的数据。
02 海量小文件读场景性能优化元数据缓存
Master
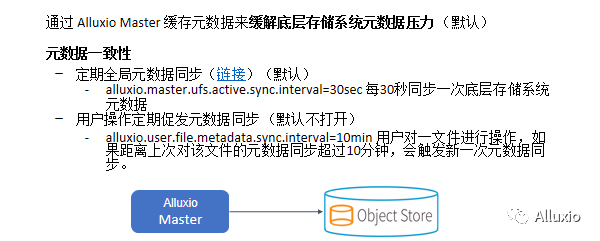
可以通过Alluxio master的元数据缓存来缓解底层存储系统的元数据压力,也就是说我们的应用可以直接来master端要元数据,而不需要一次又一次的去存储系统拿数据。很多公司找到Alluxio,也是因为他们的底层存储系统的元数据压力非常的大,HDFS cluster,ceph集群完全不能处理这么高的元数据请求,而使用master可以缓解这部分的压力。但是这会涉及到一个问题, Alluxio的元数据跟底层存储系统之间的元数据是否是一致的。为了保证元数据的一致性,一种方式是定期的全局元数据同步,这个是默认的配置。比如说每30秒会完全全局同步一次底层存储系统的元数据操作,而另一方面可以用用户操作来定期促发元数据同步,在每一个用户对一个文件进行操作之前,我们先看一下对这个文件的上一次元数据同步是什么时候发生的,如果超过了一个指定的数值,就再来一次元数据同步。
FUSE
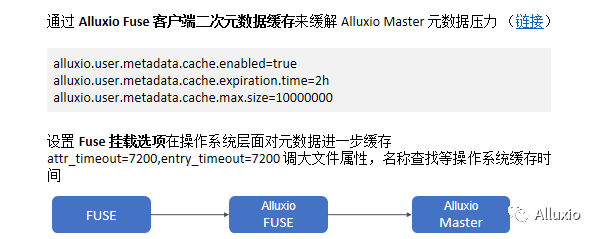
如何用fuse客户端来二次缓存元数据,缓解master节点的元数据压力。
可以通过配置metadata cache enable开启元数据缓存,而这个默认是不打开的,可以设置想要缓存多少元数据以及时间是多少,就非常适用于当我们训练的时候,对数据一致性要求不会很高,或者在短期内不太在乎元数据改变的情况,可以把这个缓存给打开,以提升训练性能。同时还可以进一步使用fuse的挂载选项。在操作系统层面对数据集进行进一步的缓存,可以调大一些文件属性,名称查找等操作的系统缓存时间。
03 海量小文件读场景性能优化数据缓存
提前缓存数据

讲到数据缓存,Alluxio可以帮助提前缓存数据以提升训练性能,而且提前缓存也可以在训练中进行,可以用一键来挂载数据集到Alluxio文件系统中,通过一键分布式缓存命令来一键缓存所需要的训练数据,而这种提前缓存也可以通过调整job worker的线程池大小加速分布式缓存。
alluxio.job.worker.threadpool.size这个配置代表说有多少个线程并发缓存数据。在海量小文件的场景下,建议把这个数字调的比较大一点,默认是建议调到2×core数目,但是在这种场景下,会发现调到10×core 数目会有更好的性能表现。大家可以进一步尝试看这个配置对所需要的场景有没有什么帮助。
数据读加速

数据读加速是使用Alluxio缓存数据来加速训练性能。这里面的一个默认假设就是读Alluxio缓存的数据是比直接去读底层系统更快的,如果发现不是,那通常是在Alluxio跟底层数据系统部署到同一个集群的情况下,但这种情况我们认为就没有太多必要去使用Alluxio了。
Alluxio最大的一个benefit其实是如果存储系统在远端,而获取数据非常耗时,且对你的存储系统有较大压力的情况下,我们是建议使用Alluxio来缓存数据,对数据I/O进行提速。
本机缓存-进程内读

数据读最快的方式当然是进程内读,也就是说数据已经缓存在本地机器上了,而fuse是起在worker进程中,可以减少不必要的RPC通信,fuse直接在进程内跟worker说要这个数据,然后worker直接从本机去拿到数据,给到fuse以及再给到应用。如果要配置fuse on worker的话,可以去打开worker的配置, alluxio.worker.fuse.enabled =true就可以了。
本机缓存-本机读

其次是可以使用单独的fuse进程,数据是存在本地机器上的,fuse是单独的进程, worker也是单独的进程,在这种情况下,worker跟fuse是分开的可以更加灵活。可以用多个fuse的挂载节点,针对不同的场景,读写的不同场景,进行个性化配置以及配置不同的应用权限。在这种情况下,因为fuse要跟worker进行多一层的RPC操作,这可能会带来一定的性能损耗或者资源损耗,会增加fuse和worker的CPU和内存的资源消耗,但不一定会影响性能,可能要根据实际应用场景进行选择。
本地集群缓存

另一方面也可以通过在本地集群缓存来提升读速度,可能本地的机器并没有那么多的空间,可能需要把数据缓存在隔壁的机器上,在这种情况下,可以通过本地的集群缓存来提升速度,而这种读主要受本地的网络I/O以及RPC的影响,其实主要是本地网络I/O的影响,性能肯定是快于从远程存储系统中去读取数据的。
UFS读并缓存

最慢的读取方式,当然是Alluxio并没有缓存任何的数据,那就不得不从远程的存储系统中把这部分数据读进来再进行缓存,以提升我们未来的读取速度。而这部分UFS读基本上是受远程网络I/O的影响,如果远程I/O比较慢的话,这部分可能读的性能会没有那么好。但是当第一次读进来并缓存之后,后续的读取都会立马加速。
04 海量小文件读场景性能优化其他优化
调高线程池大小

讲到其他的一些优化,包括可以去调高线程池的大小,线程池的大小决定了很多元数据,数据操作的并发度,也就会决定训练性能。可能I/O的元数据的延时,包括数据的并发,数据的吞吐这样的等等的数据性能,会影响训练性能。通过调高线程池的大小也许能用更多的线程来并发地执行这些操作以提高性能。这些线程池包括master、worker以及用户端的不同的线程池,这些线程池决定有多少个线程来执行操作,以及最多保留多少的线程来执行操作。
其他优化

有的时候可以针对用户特性,有时候可以减少不必要的Alluxio操作,比如说可以去除向master更新文件访问时间的元数据操作,可以表示这部分元数据不需要经常去更新这个文件最新访问时间是什么时候,这部分分析并没有用,那就不需要去更新这部分信息,可以大大减少RPC的操作。而有的时候数据如果已经缓存在一个本地集群中,而本地集群的读取性能已经足够好的情况下,我们不需要再去促发一个本地的二次缓存,因为可能二次缓存也提升不了特别多的速度。同时可以加速对底层存储系统的读速度,可能要根据不同的存储系统进行个性化配置,比如要从s3中读大量的数据或者元数据,那我们可以调大s3的线程池的大小,从而提升对s3的元数据和数据操作的并发度,以提升在海量小文件场景下的性能。
使用Fluid一键搭建Alluxio集群
大家也看到,整个Alluxio的配置调优可能并没有那么简单,它涉及到各种各样的不同的问题,如果只是想要简单的适用Alluxio的话,完全可以使用Fluid来一键搭建Alluxio集群。你只需要定义你想要使用什么样的数据集, Fluid会帮你去配置Alluxio的参数,配置Alluxio的资源,搭建整个Alluxio集群以及管理这个集群。大家就不需要去考虑种种优化,可以先试用一下,然后看Fluid搭建的Alluxio集群能不能符合你的性能需求,解决你的问题。如果不可以的话,就看一下所提到的种种优化能不能帮助提升Fluid性能,以达到理想的训练要求。
在下篇文章中会继续对以下话题进行探讨:
① Alluxio的自测工具
② Alluxio POSIX API性能指南








