作者简介
a邱 璐:机器学习工程师@alluxio,Alluxio PMC maintainer, 有多年开源贡献经验。Alluxio机器学习、深度学习、POSIX API方向负责人。熟悉Alluxio选举机制、日志、指标系统等核心组件。
孙守拙:毕业于杜克大学计算机系,目前在Alluxio研发团队担任研发工程师,主要负责机器学习场景下的数据供给开发,及Alluxio的容器化应用。
Part 1 Alluxio POSIX API自测性能
使用Alluxio POSIX读文件速度能到多少?
和从云上读取数据相比,使用Alluxio POSIX接口:
① 更快吗?
② 快多少?
上篇中提到了很多Alluxio为了加速读取数据做的各种各样的优化,那么对于用户来说还有一个非常重要的问题——在机器学习训练中使用Alluxio读数据到底有多快? 比如说数据是储存在云上的,那从Alluxio读会不会比直接从云上读更快,具体能快多少?有了比较我们才能判断出使用Alluxio到底能不能获得训练性能提升,能提升多少。
Alluxio自建性能测试工具:StressBench
StressBench:一套Alluxio自带的性能测试,用来测试不同环境下Alluxio各个部分的处理速度。
优点:不依赖外部组件,只需要运行的Alluxio集群
在Alluxio中有一个自己的性能测试工具,叫StressBench,它可以通过在一定时间内进行一系列操作,比如读、写或者元数据操作,来测试不同环境下Alluxio各个部分的处理速度。它的优点在于不依赖外部组件,只需要一个运行的Alluxio集群,这个集群可以是只有一个节点,一个master,一个worker,也可以是一个更大的集群,有更多的节点。
Alluxio POSIX API性能测试工具:Fuse StressBench
Fuse StressBench:测试通过POSIX接口从Alluxio读取文件的速度。
需要额外在每一个Alluxio worker节点将Alluxio通过Fuse挂载到本地文件系统(https://docs.alluxio.io/os/user/edge/en/api/POSIX-API.html)
在StressBench中加入了fuse StressBench,就是一个对于fuse的测试,用来测试通过POSIX接口,从Alluxio中读取文件的速度。那么fuse StressBench除了需要一个Alluxio集群之外,还需要额外在每一个worker节点上都将Alluxio通过fuse挂载到本地文件系统。
既然要测试性能,最主要的一个目的就是可以量化读性能,在有这个测试工具之前,只能说从Alluxio POSIX接口读文件要比从云上读快很多,但是具体有多快,快多少,用户并没有办法测量,现在有了这个工具,就可以拿出数据证明确实快,也可以展示有多快。
Fuse StressBench-单机测试
设置:单节点,一个worker,一个读取挂载点
步骤:
① 将测试文件写进Alluxio worker
② 通过挂载点从Alluxio worker读测试文件
③ 获得读性能数据
最简单情况下,就是Alluxio集群只有一个节点,一个worker和一个读文件的挂载点,在测试中第一步我们将测试文件写入Alluxio worker,第二步通过POSIX API去读它们,测量在一段时间内读了多少字节,就可以返回在这段时间内读的速度。整个过程只需要跑两个命令,就可以看到单机情况下的读性能了。
Fuse StressBench-集群测试
设置:多节点,每个节点一个worker和一个读取挂载点
步骤:
① 将写测试文件写进worker,每个worker存储一部分文件
② 每个节点上都通过挂载点读取测试文件
③ 获得每个节点及集群的读性能数据
相比单机测试,集群测试更贴近实际生产中的机器学习场景。其中有多个节点运行了Alluxio worker,每个节点都通过fuse挂载了Alluxio,每个节点上都有自己从Alluxio中读取文件的任务,当然实际生产环境中训练还有计算的部分,我们这里fuse StressBench只是测试读取数据的行为。
我们利用了Alluxio的job service来模拟这个场景,可以理解为每台机器都有一个程序在读文件,就像实际训练中每个节点上的训练任务,每个节点上的fuse StressBench各自计算一定时间内自己读了多少字节,从而就可以知道每个节点读的速度,进而知道整个集群的速度。同样,整个过程只需要两个命令就可以完成。
Fuse StressBench单节点测试示例
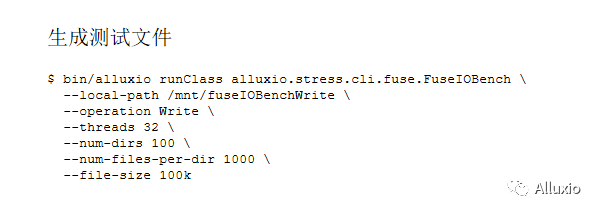
这里用单节点情况做了一个简单的例子,有一个单节点的Alluxio集群,一个worker和一个本地用于读的挂载点,通过bin/alluxio runClass来跑StressBench测试工具,可以看到还同时提供了写的挂载点,这一步用来将测试文件写进Alluxio的路径,然后指定操作为写文件。我们还提供了线程的数量,一共将测试文件写进多少个文件夹,每个文件夹有多少文件,以及每个文件的大小,等待命令返回之后,这些文件就会全部储存到了Alluxio worker里面。

文件写好后进行读操作,在读测试文件时,用相同的这个 bin/alluxio runClass来启动测试。接下来指定读文件的挂载路径、读的方式、线程数量、测试时间,以及和刚才生成文件是一样的,文件夹数量,每个文件夹有多少个文件和文件大小。可能有人发现我们这个测试中读和写的本地路径不一样,是因为在生成测试文件的时候fuse就会有一些缓存,如果再去同一个文件夹读的话,这些缓存会影响测试读性能的准确性,所以用了不同的挂载点来避免这个问题。也就是在开始测试前挂载的时候,将Alluxio挂载到两个不同的路径,一个负责写,一个负责读。这样的话写文件时产生的缓存,就不会影响到读文件了。

这是读测试返回后生成的部分结果。可以看到这个单节点达到了每秒183.1兆的读取速度。我们刚才指定了一些参数,包括路径、文件大小等等,以及如果在测试中出现了任何错误,也会在这里显示。
Fuse StressBench测试限制
① 只支持读性能测试
② 只支持测试读自己生成的文件
目前这个fuse StressBench的测试工具有两个主要的限制,第一个是它只支持读性能的测试,暂时还不支持写数据或者元数据操作的测试。之前的写操作只是为了测试读性能生成的数据,它自己并不能作为一个测试。另外一个就是只支持读用它本身生成的文件,不能使用任意文件来进行测试,否则会报错,主要原因是因为如果用任意文件测试的话,很难保证资源平均分配,可能有些线程很早就结束了它的任务,但是有些线程后面又读了很久,那这样的话这个测试结果就不准确了。
Fuse StressBench官方文档
Fuse StressBench:https://docs.alluxio.io/os/user/edge/en/operation/StressBench.html#fuse-io-stress-bench
StressBench:https://docs.alluxio.io/os/user/edge/en/operation/StressBench.html
想了解更多关于fuse StressBench内容可以查看官方文档中关于fuse StressBench的部分,其中有对如何使用这个工具更为详细的介绍。接下来更为详细的介绍一下如何在Alluxio POSIX API中debug以及性能分析指南。
Part 2 Alluxio POSIX API debug&性能分析指南
故障排查-查看日志
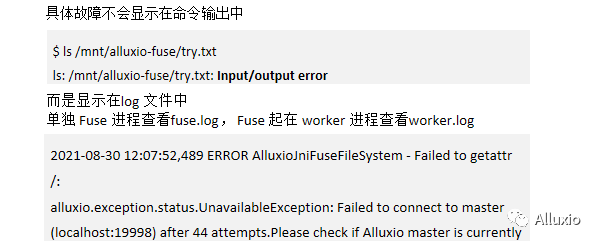
首先故障排除,是fuse有个很大的问题,在于具体的故障原因不会显示在我们的命令输出中,这主要是fuse本身自带的一个限制,我们只能确定错误码是什么,但这个错误码可能翻译给用户之后,它并没有包含那么多的信息。比如说我们这个命令可能ls一个Alluxio fuse中的文件,然后会出现一个I/O报错,但无法具体知道到底是什么样的问题,而具体的问题显示在日志文档中,就包括如果单独起fuse进程的话,你需要查看fuse.log,而如果fuse起在worker进程中的话,你查看worker.log,它里面会显示具体的原因,有可能是因为没有办法去连接master,导致读不到数据之类的种种原因。
故障排查-日志等级修改
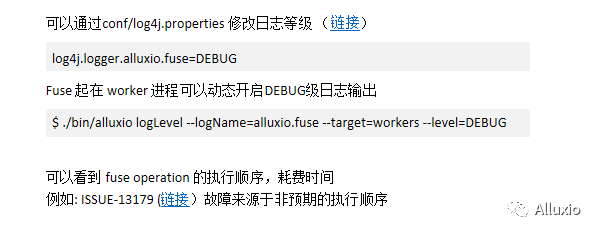
可以对日志进行等级修改,修改等级为debug之后,我们可以获得更加详细的信息。修改日志等级主要有两种方式,一种是通过修改Alluxio的conf/log4j.properties直接修改日志等级,我们可以对任意的包,把它修改成debug这种日志等级。
如果fuse起在worker进程中,可以动态地通过一个Alluxio的CLI的命令,然后开启debug级别的日志输出。比如说logLevel这个命令,它可以把worker中所有Alluxio.fuse包的所有日志变成一个debug级别的日志输出,就可以方便我们更好去排查出现的问题。这些日志通过修改为debug,可以看到fuse各种操作执行顺序以及耗费时间,有助于发现到底是哪一些fuse操作花了比较多的时间,以及是否有一些非预期的执行顺序。曾经有过一些故障就来源于一些非预期的执行顺序。
性能分析:应用,Fuse,Alluxio
当fuse使用了Alluxio POSIX API之后,发现可能性能不如预期,那性能不如预期这个问题到底出现在哪一个方面?
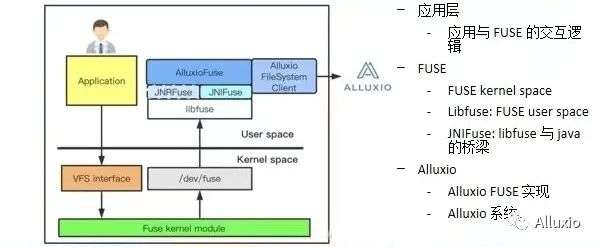
有几个层面:一个是应用,一个是fuse,还有Alluxio。性能不如预期的情况下,就要回过头来看这一整套东西。先了解一下整个fuse的工作流程,当用户发出了一个请求,比如说ls这个请求,它会把这个请求发送到fusekernel端,然后Kernel端进行一定的处理之后,再返回到应用端,发送给Libfuse,然后Libfuse把这些命令变成一个可以自定义的模式,通过实现Libfuse,来实现我们自己的文件系统。
然而Libfuse是写在C++上的,而Alluxio是写在Java里面的,就引入了另外一层抽象叫JNIFuse,通过JNIFuse之后, Alluxio fuse再定义每个操作具体要执行什么样的具体的内容。比如说Alluxio fuse接到底层fuse的一个命令说ok,这个用户做了一个ls操作,已经拿到了一系列的ls的指令相关内容,比如说你要读哪个文件的一些信息,然后Alluxio fuse要决定如何去应对这些操作,我们拿到ls操作之后,就会去Alluxio集群内去问,这个用户要读文件a,能不能给我文件a的信息,而Alluxio fuse拿到这部分信息之后,再通过一系列的fuse返回给用户。
所以这其中其实包含了三个方面,一方面是应用层,应用是与fuse如何进行交互的;另一方面就是 fuse层,包括fuse,kernel,Libfuse以及JNIFuse,这些都统称为fuse层,就是 fuse是如何把一个应用层的命令转化给Alluxio去具体地实现。最后一层就是Alluxio层,包括Alluxio是如何实现fuse的,以及Alluxio整个系统。
01 性能瓶颈来源于Alluxio POSIX API?

首先需要明确性能瓶颈是不是来源于Alluxio POSIX API,因为训练性能不佳,可能是来源于各种各样的原因,包括资源不足,包括算法和训练逻辑比较缓慢,以及包括应用的元数据延时长或者数据吞吐低。而我们就要分析这个性能不佳来源是不是跟数据或者元数据相关,如果与其无关可能性能瓶颈并就不在Alluxio POSIX API这一层,那研究它也就无济于事。
所以,需要先分析性能瓶颈是否来源于Alluxio POSIX API,我们可以对比Alluxio POSIX API与文件系统以及其他数据方案的性能差异,而且可以移除训练逻辑只留下数据相关操作,看看性能如何。
当我们发现可能性能瓶颈来源于Alluxio POSIX API之后,我们需要更多的去了解应用与Alluxio POSIX API之间的互动,比如说这个应用跑了哪些与POSIX API相关的指令,应用是如何呼叫这些指令的,它的呼叫顺序是怎么样的,呼叫的并发度是怎么样的,这些信息都是需要提前了解的。
02 Fuse还是Alluxio是性能瓶颈?

分析到底是fuse还是Alluxio是性能瓶颈,我们先使用了一个stack fuse来分析这部分性能。
Stack fuse是跟Alluxio fuse使用了相同的fuse组件,它也包括fuse kernel,Libfuse和JNIFuse,然而与Alluxio fuse不同的在于,它是直接对本地文件系统进行读写与以及元数据操作,不涉及任何的Alluxio组件。
可以通过一个命令能把本地文件系统mount在另外一个文件夹,然后对这个mount文件夹进行一系列的操作来对比性能,通过对比本地文件夹以及stack fuse,可以了解fuse这个层的性能损耗,通过对比stack fuse以及Alluxio fuse,可以得出Alluxio的性能损耗。
之所以要了解是fuse还是Alluxio的性能瓶颈,也是因为如果是fuse的性能损耗,其实在Alluxio这端是做不了过多的性能提升的,就是任何一个fuse的实现,包括s3 fuse之类的其他实现,它都会带有fuse原生的性能损耗,而fuse这种操作实现方式是很多年前就已经实现了的,近期也没有什么大的改变,也不会因为要把fuse应用在我们的训练中,进行一个大版本的升级。而如果发现是Alluxio的性能损耗,就可以进一步去分析到底是Alluxio中哪一部分出了问题,哪一部分可以进一步的优化来提升训练性能。
03 ALLUXIO FUSE分析
并发度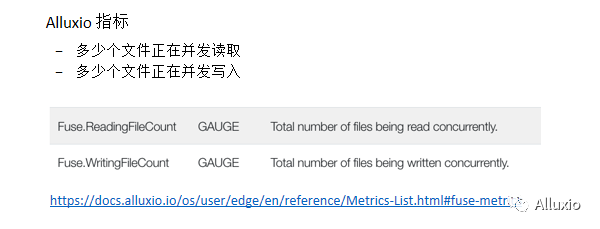
Alluxio fuse的分析包括几个方面,首先可以通过看一些指标,比如说Alluxio fuse的相关指标,发现有多少个文件正在并发读取,多少个文件正在并发写入,性能不好是不是由于有超高量的并发读取和写入的操作,而这个超高量的fuse方面的读取跟写入,可能并没有被Alluxio的线程池或者存储系统很好地支撑起来,这是第一步发现到底是什么性能问题的一个指标。
操作频繁度与耗时

也可以分析fuse相关操作的频繁度以及耗时。对于每个fuse操作都会记录相应的指标,比如说fuse每个读命令都会记录这个读命令被呼叫了多少次,平均的完成时间是多少?超过5%的读操作超过了多少时间?从这些信息中我们可以看出哪个fuse应用被呼叫的最多,而哪个fuse应用耗费了最长的时间,是平均时间长还是偶尔时间长,这些信息都对进一步分析性能瓶颈有非常重要的帮助。比如发现fuse的读操作花费时间最长,那我们可能就专注于在读操作上,看看是哪一步的性能有一定的损耗。如果是平均时间特别长的话,是不是涉及到配置或者涉及到存储系统的连接的问题?那如果是平均时间非常短,但是有1%或者5%的操作花了非常长的时间,是不是就涉及到资源的争夺?就可以进一步的去分析性能瓶颈在哪里了。
[Advanced]追踪性能瓶颈
还有一些更高级的追踪性能瓶颈的方式,可以通过指标系统进行时间追踪,比如fuse读这个操作非常的慢,就可以在fuse读操作里面加上一些timer metrics,然后一步一步的追踪下去,看看到底在哪里花了最长的时间,最后针对那个方面进行性能的提升。
除时间追踪之外,还可以进行CPU资源、内存资源以及锁资源的追踪,有个应用叫Async profiler,它可以帮助进行CPU memory以及锁的瓶颈的分析,可以让我们发现哪一个Alluxio的Java class花了最多的CPU资源或者最多的内存和锁资源,再或者可以对RPC指标进行追踪,目前支持gRPC和s3。
可以发现,比如说这些RPC操作非常的耗时,那究竟是在哪里耗时呢?我们的client对worker发送了一个请求,非常耗时,那到底是这个请求发送途中很耗时还是worker处理这个请求很耗时呢?就可以发现到底是worker处理慢,还是可能存在资源竞争的问题。这一整套分析都是比较有难度的,这里也放了一个性能分析的案例,也就是我们最近在一个百万小文件的场景下,通过性能分析,把最高的吞吐从2400小文件每秒提升到超过13,000小文件每秒。可以通过这个案例来具体看一下,我们是如何做整一套性能分析的,大家谢谢。








