作者:Tyler Crain, Software Engineer @ Alluxio
1. 介绍
Alluxio实现了一套虚拟分布式文件系统,支持Hadoop或Spark等计算引擎通过单一的接口访问独立的大型数据存储。在Alluxio集群内,Alluxio master负责协调并确保稳定地访问底层存储系统(简称UFS)。Master包含文件系统元数据的全局快照,当客户端想要读取或修改文件时会首先与master通信。鉴于master在系统中的核心作用,master必须具有容错性、高可用性、强一致性, 并且能够快速响应。本文将讨论Alluxio master是如何从Zookeeper的复杂多组件系统到更简单有效的Raft系统的演进的。
文件系统的操作可以看作是在系统上执行的一系列命令(如创建/删除/读/写)。文件系统在单一的线程中每次只执行一个命令,为其提供了一个顺序规范,该规范既方便因果推理,也方便在其基础上实现应用程序。尽管该顺序规范十分简单,但Alluxio的虚拟分布式文件系统的实现较为复杂。Alluxio由许多并发执行的可变组件构成,包括协调系统的master、存储文件数据并在客户端和UFS之间充当缓存的worker节点、UFS本身,以及根据master的指令访问系统所有其他部分的客户端。同样地,我们可能希望依据各个组件之间地因果依赖关系,将其梳理成每次只执行一项操作的按序执行命令的单一线程,但实际上,它们各自都在运行着复杂的系统。
因此,我们要解决的核心问题是如何使Alluxio master看起来像是由单节点运行,每次运行单个操作,因此易于实现且容易与其他组件交互,但与此同时仍具备容错性和高可用性。此外,master的响应速度必须足够快,每秒可执行数万次操作,并可扩展到足以支持数亿文件规模的元数据。
2. Alluxio的日志和高可用性
Alluxio master的内部状态由几个表组成,包含文件系统元数据、数据块元数据和worker元数据。文件系统元数据由一张inode表和一张边表组成,前者将每个目录和文件的元数据(其名称、父目录等)映射到一个叫做inode id的唯一标识符上,后者则使用inode id将目录映射到其子目录上。每个文件的实际数据被分割成位于Alluxio worker上的一个或多个数据块,可以通过数据块元数据表和worker元数据表来定位,前者将每个文件映射到一组数据块标识符上,后者将每个worker映射到它所包含的数据块上。
每个修改元数据的操作,例如在虚拟文件系统上创建一个新文件,都会输出一个包含对表所做修改的日志条目(journal entry)。日志条目按照它们在日志中被创建的顺序存储,从而满足我们对master所做的顺序规范。从某一初始状态开始按顺序回放这些日志条目,总可以让元数据到达相同的状态,这就保证了master节点具备在宕机后恢复到宕机前状态的能力。
为了防止日志条目数量过大,Alluxio 会定期对元数据执行快照操作。如果该日志的存储位置具有高可用和容错性,那么就为系统的可靠性打下了基础。例如,我们可以启动某个单节点,并让其作为master节点。之后,如果我们检测到该节点发生了故障,那么就重新启动一个新的节点,新节点会回放日志,并取代原master成为新的master。这样做可能会产生的问题是,启动一个新的节点并回放日志可能需要较长的时间,而系统在此期间是不可用的。为了提高系统的可用性,我们可以让多个master的副本同时运行,其中只有一个master服务于客户端操作(该master 称为 primary master),而其他的master只是在被创建后持续回放日志条目(这些master称为secondary master)。这样的话,当primary master发生故障时,secondary master可以立即接替它成为新的 primary master。
3. 实现初始设计
从基本的系统设计角度,我们还有两个问题需要解决,1:如何确保在任何时候都只有一个primary master在运行;2:如何确保日志本身的一致性、容错性和高可用性。从2013年开始,我们初步对两个问题进行解决。
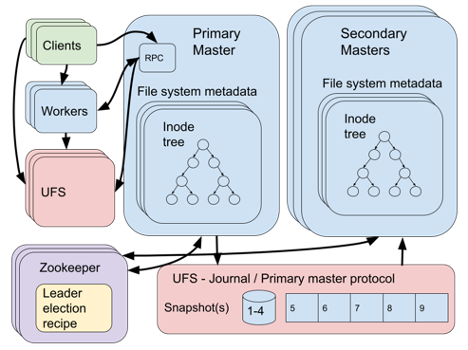
第一个问题是通过Zookeeper [1]解决的。Zookeeper是一个高度可靠的分布式协调服务,提供基于ZAB [2] 共识算法的类似文件系统的接口。Zookeeper具有领导者选举机制 [3] ,可以同时纳入多个节点,其中一个节点会被选为领导者。如果某个领导者在一段时期内不再响应,那么将有一个新的节点被选为领导者。在Alluxio中,所有的master都先以secondary master的角色加入Zookeeper领导者选举机制,当某个secondary master 节点被选为领导者后,该secondary master即晋升为primary master。
为了解决第二个问题并确保日志的高可用性和容错性,日志条目将被存储在底层文件系统(UFS)中。当然,这里的UFS必须具备高可用性和容错性。此外,日志必须是一致的。如前文所述,日志条目应该是一个满足顺序规范的完全有序的事件日志。只要每次运行的primary master不超过一个,它就可以将日志条目追加到UFS中的文件中,即满足一致性要求。但我们的领导者选举机制是否已经可以确保这一点呢?如果我们具备理想的故障检测器或者同步系统,那确实可以,但遗憾的是,我们两者都不具备。当Zookeeper执行领导者选举时,它会在选定新的领导者之前通知原领导者已丧失领导权,但如果原领导者(或网络)响应很慢,当新领导者的选举开始进行时,它可能还在向日志添加条目。因此,可能会出现多个primary master同时向日志添加条目的情况。为了减少此类情况的发生,一套互斥协议会持续运行着,它主要利用由特定的文件命名方案来保障UFS的一致性。
我们来看看该解决方案存在的一些问题。首先,它需要Zookeeper和UFS等几个外部系统与Alluxio master共同运行,这使得系统的设计和分析变得复杂。每个组件都要考虑采用不同的故障和可用性模型。要在不同的UFS之间进行选择也会让系统更加复杂,例如,某个UFS在执行频繁的小型日志追加操作时,可能无法实现高性能。此外,每个UFS可能具有不同的一致性保障机制,当两个并发的Primary Master试图同时写入日志时,情况就会很复杂。鉴于以上原因,我们将HDFS作为UFS的推荐配置。
现在,我们来介绍如何使用Raft进行更简单、有效的设计。
4. 基于多副本状态机(Replicated State Machine)的改良设计
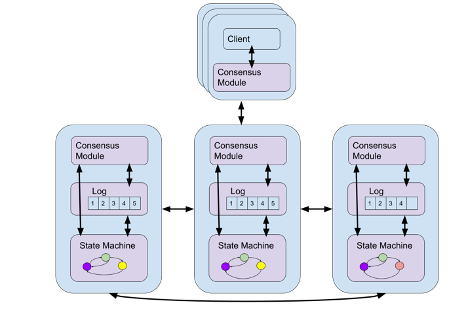
首先我们来介绍下多副本状态机(Replicated State Machine)的基本概念。状态机以一系列命令作为输入,这些命令会改变系统的内部状态,同时会产生一些输出结果。针对我们的应用场景,状态机必须是确定性的,即给定相同的输入命令集,系统会产生相同的输出结果。如果我们把Journal(日志)想象成状态机,那么就可以简单地把它看成是一种只能执行添加(append)命令——即只在尾部添加日志条目的——日志系统。而多副本状态机则是一种具有高可用性和容错性的状态机。它通过在多个节点上创建状态机副本,并运行共识算法来确保相同的命令在每个状态机的副本上以相同的顺序被执行。
Raft[4]正是这样一种多副本状态机协议,该协议只需要用户提供一个确定性状态机作为输入。Raft的重要特性之一是能够满足线性一致性(linearizability)[5]条件。假设客户端在多副本状态机上执行的每个命令都有调用和响应两个步骤,线性一致性能确保任何一项操作在调用和响应两个步骤之间的某一时刻能够被所有客户端所观察到,而这一时刻我们称为该项操作的线性点。所有操作的线性点构成了完整的操作排序,该排序符合正在实现的状态机的顺序规范。因此,尽管我们的状态机是具有多副本的,但对客户端而言是在实时地按序执行操作。
5. 通过Raft实现Alluxio的日志
现在我们只需将日志条目的记录(log)作为状态机,由 Raft进行多副本创建,但其实我们还可以进一步简化系统。之所以用日志条目的记录来表示状态,是为了让master能通过回放日志条目来恢复到最近的状态。由于 Raft 负责容错机制,我们可以对用来表示 master 状态的状态机进行更高层次的抽象化——即抽象成只包含 Alluxio 文件系统元数据状态的表集合。Master将正常执行操作,并向状态机发出修改表的确定性命令。 在发生故障时,Raft 会自行处理状态的日志记录、快照以及状态恢复。 Raft 代码与master节点上的 Alluxio 代码一起运行,可以快速地访问表存储中的元数据。
这些表是使用 RocksDB [6] 来实现的。 RocksDB 是通过日志结构合并树 [7] 来实现的键值磁盘存储,可支持有效的数据更新。通过使用 RocksDB,存储的文件系统元数据大小可以超过master节点上可用的内存。 此外,Alluxio 还可以在 RocksDB 上层额外实现一个内存缓存,确保较快的键读取速度。
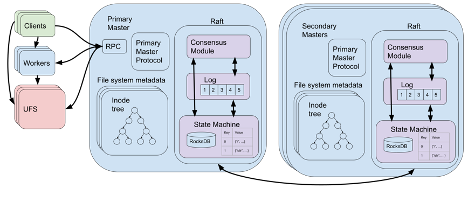
跟之前一样,只有一个的master节点会被指定为primary master,用来响应客户端的请求。这是因为引起日志改动的虚拟文件系统操作只应该由primary master来执行,甚至可能会引起外部状态(如UFS 和worker节点)的改变。Raft 内部会使用共识算法的领导者选举机制,而Alluxio会使用该机制来任命primiary master节点。为了降低两个primary master 同时运行的概率,Alluxio 额外添加了一层同步机制,即在新选出的primary master 开始服务客户端请求前,允许原 primary master 显式地退出或响应超时。
我们通过使用Raft,不仅使系统实现得到极大地简化,而且也使Alluxio的master具备高可用性和容错性,性能和可扩展性也得到显著提升。此外,可以直接在 Alluxio master节点上运行的 Raft 实现库Apache Ratis [8] 也取代了Zookeeper 和 UFS 等外部系统的运行。同时,我们也不再需要在状态恢复后回放底层操作日志,而只需要通过 RocksDB 访问高速的键值存储。而Raft也会高效、一致的对RocksDB进行多副本维护,从而确保高可用性和容错性。
作为参考,我们也建议阅读Confluent 如何通过从 Zookeeper 演进到 Raft的相关文章 [9],该文章介绍了如何简化和提高其在Apache Kafka中的分布式架构的性能。
参考资料
[1] Hunt, Patrick, et al. “{ZooKeeper}: Wait-free Coordination for Internet-scale Systems.” 2010 USENIX Annual Technical Conference (USENIX ATC 10). 2010. https://zookeeper.apache.org.
[2] Junqueira, Flavio P., Benjamin C. Reed, and Marco Serafini. “Zab: High-performance broadcast for primary-backup systems.” 2011 IEEE/IFIP 41st International Conference on Dependable Systems & Networks (DSN). IEEE, 2011.
[3] Apache Curator Leader Election. https://curator.apache.org/curator-recipes/leader-election.html
[4] Ongaro, Diego, and John Ousterhout. “In search of an understandable consensus algorithm.” 2014 USENIX Annual Technical Conference (Usenix ATC 14). 2014. https://raft.github.io.
[5] Herlihy, Maurice P., and Jeannette M. Wing. “Linearizability: A correctness condition for concurrent objects.” ACM Transactions on Programming Languages and Systems (TOPLAS) 12.3 (1990): 463-492.
[6] RocksDB. http://rocksdb.org.
[7] O’Neil, Patrick, et al. “The log-structured merge-tree (LSM-tree).” Acta Informatica 33.4 (1996): 351-385.
[8] Apache Ratis. https://ratis.apache.org.
[9] Apache Kafka Made Simple: A First Glimpse of a Kafka Without ZooKeeper. https://www.confluent.io/blog/kafka-without-zookeeper-a-sneak-peek/.








