
连接计算层与存储层的桥梁。2021年,“开源”依然是基础软件领域的热门话题。
在中国,大型科技企业加入开源阵营。阿里云发布全新操作系统“龙蜥”并宣布开源,蚂蚁金服开源OceanBase数据库,华为发布“开源雨林”计划。
在北美,HashiCorp、Gitlab与Confluent成功上市,市值都超过百亿美元;在数据库领域,Databricks、MongoDB的估值/市值都比2020年提升了一倍以上,全球开源软件公司IPO热潮已经到来。
在众多的开源公司中,一家名为Alluxio的“分布式超大规模数据编排系统”是一个特殊的存在,其创始人兼CEO李浩源将“数据编排”称为数据世界中缺失的一部分。
Alluxio的名字你可能会感到陌生,但它的来头并不小:
–Alluxio孵化于加州大学伯克利分校AMP实验室。AMP实验室也是孵化出了Spark和Mesos等优秀开源项目的功勋实验室;
–Alluxio联合创始人李浩源在AMP实验室师从分布式系统和网络领域泰斗Ion Stoica教授和Scott Shenker教授。Ion Stoica就是估值380亿美元的大数据独角兽公司Databricks的联合创始人,两人最近一次公开对话是在去年的2021华泰证券金融科技投资峰会上;
–Alluxio也是顶级的风险投资Andreessen Horowitz(即a16z)的投资项目。a16z是整个互联网投资界最为耀眼的明星之一,过去先后投资了Facebook、Groupon、Skype、Twitter、Zynga、Foursquare,在美国仅次于红杉和Accel Partner,排名第三。
-2021年1月,Alluxio中国区总部落地北京中关村,开始加大对中国市场的投入。
本文,「甲子光年」采访了Alluxio创始人兼CEO李浩源,来看下“数据编排”在大数据中所发挥的作用。
1.数据编排——大数据时代的“滴滴打车”
为什么李浩源说Alluxio填补了数据世界缺失的一层?先看一下在大数据和 AI 生态圈里Alluxio所处的位置。
在大数据软件栈里,Alluxio所处的“数据编排层”,向上对接计算应用(比如Spark,Presto,Hive,Tensorflow等),向下对接不同的存储(比如阿里巴巴的OSS对象存储,AWS的S3存储,HDFS等)。
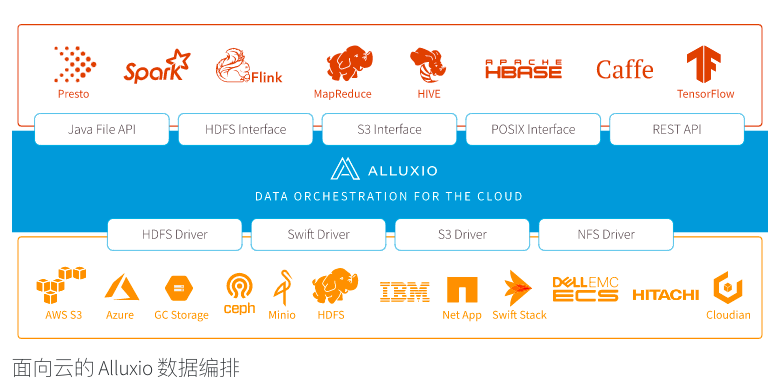
Alluxio创始人兼CEO李浩源告诉「甲子光年」:“这就好比一个打车软件,其核心是如何让打车出行这个事情更加高效,如滴滴或Uber,它的上层是有打车需求的客人,下层是提供服务的司机和汽车,而应用软件可以让上层需求得到更高效的满足,以及下层司机和汽车资源得到更加高效的利用。”
数据编排层本不存在,但大数据时代的发展,让计算与存储之间的数据访问门槛变得越来越高。例如,当开发人员想要将应用程序从本地环境迁移到云环境时,或者当编写 Apache Spark 应用程序的数据科学家想要编写 Tensorflow 应用程序时,需要花费大量精力让应用程序高效且有效地访问数据,而不是专注于算法和应用程序的逻辑。
这是一个大数据行业的普遍挑战,原因主要有两点:一是现代大数据和AI平台的体系架构,随着云计算的出现,正在经历从传统Hadoop架构走向存算分离的趋势,Alluxio在成立之初就公开做过存算分离的趋势判断。
以混合云为例,当企业开始进行数字化转型,使用云服务成为了不二之选。但一步到位的云迁移是不切实际的,使用混合云成为一个过渡方案——计算侧使用云服务的灵活性和敏捷性,存储侧保留在本地从而保持对数据的严格控制;多云则是企业不想被单一的公有云厂商锁定,使用不同云厂商的服务。
混合云和多云都导致了存算分离或者跨地理存储的挑战。在这种的架构趋势下,如何在不损失数据本地性优势的同时,进一步提升I/O效率是一个明确的行业痛点。
其次,大数据带来的数据源爆炸式增长,导致大数据计算栈和厂商越来越多。每隔五到十年,就会出现另一波新的存储系统和计算框架。
从计算的角度来看,近几年大规模数据应用比如机器学习、深度学习已经从试验阶段进入普及阶段。在其模型训练阶段需要输入海量数据——俗称“喂数据”,这就需要数据I/O的高吞吐量。实际上模型训练效率不高的原因,很多是因为I/O的吞吐量不够,而不是用来训练模型的GPU不够快。
从存储的角度来看,数据湖正在崛起,传统的结构化数据正在向新格式演进。李浩源预测,2022 年,包括Apache Iceberg 、 Apache Hudi 在内的开源项目将逐渐取代云原生环境中传统的 Hive数仓,让Presto 和 Spark 等工作负载能够更高效地实现大规模运行。
Alluxio的数据编排平台,就是为解决上述挑战而存在。
正如著名的计算机专家David Wheeler所言,“在计算机领域所有的问题,没有任何一个问题不能通过添加一层抽象来解决”。
通过这一层新加入的数据编排层,可以让计算和存储之间的强关联解耦,从而让计算和存储都可以独立而更敏捷地部署和演进。数据应用可以不必关心和维护数据存储的具体类型、协议、版本、地理位置等,而数据的存储也可以通过数据编排这一层更灵活更高效地被各种不同应用消费。
阿里云高级技术专家车漾曾分享过阿里云在Alluxio的云端AI训练场景实践。如果通过普通的网络从 Object store 传输数据, 大约能支撑 300MB/s, 这远远不能达到充分使用训练资源特别是 GPU 高吞吐的特性。但是一旦利用 Alluxio 构建了一层分布式的数据缓存,负责训练的容器进程和Alluxio worker 容器进程就可以以很高的速率交换数据。比如当两者在同一物理主机上的时候, 可以达到 1-6GB 每秒。
目前,全球十大互联网公司中已经有包括Facebook、Airbnb、Uber、阿里巴巴、腾讯和字节跳动在内的八家企业部署了Alluxio。
2.开源吞噬软件
很长一段时间以来,Alluxio的诞生地加州大学伯克利分校都是开源的摇篮,如大家熟知的Unix/BSD,BSD 是伯克利标准发行版。Unix/BSD的一部分是TCP/IP栈,它驱动着在当今的互联网中占据主导地位的网络协议栈。
在开源文化的影响下,Alluxio也是一家“开源原生”的公司,代码从一开始就是放在Github上,全世界的研究人员和工程师都可以参与。
2015年,Alluxio在成立不久后就获得硅谷顶级风投A16Z的投资,A16Z此前也投资了同样从AMP实验室中孵化出来的Apache Spark和Apache Mesos两家开源项目背后的商业化公司,对开源的商业模式非常熟悉和认可。
值得一提的是,开源不等于免费,而是一种商业模式。开源公司的商业模式大概包括以下3种:
一是提供技术支持及咨询服务,如Red Hat(红帽)。这家成立于1993年的公司主要出售基于开放源代码Linux操作系统的软件和服务,主要盈利方式为红帽免费提供开源软件,但向客户收取维护、支持和安装等服务费用。
不过这种商业模式是项目制,很难规模化,“红帽模式”并不容易复制。
第二种是更为常见的方式Open-Core,即核心代码开源,商业版套件收费。
因为大部分企业客户在下载源代码后都需要购买额外功能才可规模化使用,这种方式相当于用免费的代码吸引开发者,来取代传统软件业的营销投入,再卖付费的其他功能。
这种模式的难度在于构建一个繁荣的开源生态,但一旦构建就意味着比较明显“赢者通吃”的特性。如果一个开源软件,做到了在其生态位上行业标准的地位,那么下一步的商业化其实就是水到渠成的。
最后一种是云服务的Hosting(托管)模式——开源厂商将其服务托管在公有云平台上,开发者付费给IaaS厂商,IaaS厂商再分一部分给开源原厂。数据公司Databricks、开源软件服务公司Acquia都是这种模式。
托管模式是云计算与开源模式相结合的一次商业创新,让开源公司找到了商业落地的完美模式,这是开源模式在近几年高速发展的核心原因之一。李浩源在2022年的大数据发展趋势预测中表示,数据操作的复杂性导致了本地 Hadoop 的消亡,而云服务能够轻松实现架构配置的弹性,并且操作成本很低。2022 年,我们将看到托管服务的出现,它不仅会应用于单一云环境,也会应用于混合云和本地部署,从而进一步降低数据目录、数据治理、计算框架、可视化和交互式分析(Notebooks)等大量组件集成的复杂性。
此外,随着云上 SaaS 和托管服务形成更多数据孤岛,更好的数据治理、增强的数据目录,结合跨服务的数据编织将很好地解决这一问题,实现跨租户、跨云服务厂商之间高效、安全地共享数据,数据交换比以往更容易实现。
Alluxio在商业化上已经初具成果,2021财年营收比2020财年增长3.5倍,并实现正现金流。在这一年中,Alluxio实现了为全球排名前六公有云中的五家提供数据编排层,用于各种环境中的分析和AI工作负载,包括多云和混合云。
开源+数据编排,在一个新的商业模式和一个新的技术趋势的交汇处,正在产生大数据时代新的市场机遇。








