导语
Alluxio 是一个面向 AI 以及大数据应用,开源的分布式内存级数据编排系统,随着大数据和 AI 业务向 Kubernetes 等容器管理平台迁移,将 Alluxio 作为中间层,为数据查询及模型训练等场景加速,成为各大厂商的首选方案。
Alluxio 在游戏 AI 离线对局业务中解决的问题可以抽象为:分布式计算场景下的数据依赖问题,传统的数据依赖的解决方式有:
1. 镜像打包。这种方式隔离性比较好。但使用镜像缓存能力有限,数据更新频繁,每次都要重新打包部署镜像,停服务更换容器;
2. 即用即下。整体架构简单。但每次访问数据,都需要从远端拉取,性能较差;
3. 本地部署。数据本地性好,但解决权限问题和运营困难。
这几种方式,都有着各自的优缺点。引入 Alluxio,可以在成本没有增加太多的情况下,显著提升 AI 任务的并发上限,同时 AI 任务程序仍使用原有的 POSIX 方式访问 Alluxio,因此业务对存储系统的改变无感知。本文主要介绍 Alluxio 在算力平台上与游戏 AI 特征计算业务的适配和优化。
作者介绍
郑 兵
腾讯研发工程师
目前主要负责 Alluxio 及 分布式存储相关的开发工作
毛宝龙
腾讯高级工程师,Alluxio PMC成员,Apache Ozone committer,腾讯 Alluxio OTeam 开源协同团队负责人
主要负责腾讯 Alluxio 的研发和落地工作,和 Apache Ozone 的文件系统方向的研发工作。
潘致铮
腾讯高级工程师,开悟游戏AI平台团队成员
主要负责游戏AI场景下,机器学习平台的开发、搭建与运营工作。
背景
游戏 AI 离线训练业务分为监督学习与强化学习两种场景。其中在监督学习场景下,一般分为特征计算、模型训练与模型评估。在强化学习的部分场景下,也会有特征计算的需求。游戏 AI 场景的特征计算中,需要将对局信息进行还原,进而通过统计与计算,生成模型训练所需的特征数据。而对局信息的还原必须通过相应的游戏依赖(游戏本体、游戏翻译器、游戏回放工具等),一般情况下,游戏依赖的大小在 100MB – 3GB 不等。而游戏的版本性决定了特定的对局信息需要特定版本的游戏依赖才能计算。
存储端的 gamecore 即游戏依赖,对应一个游戏版本的 linux 客户端。将 gamecore 放到服务器的本地存储中,可以得到更好的读取性能和稳定性,但是成本高,并且需要本机权限。
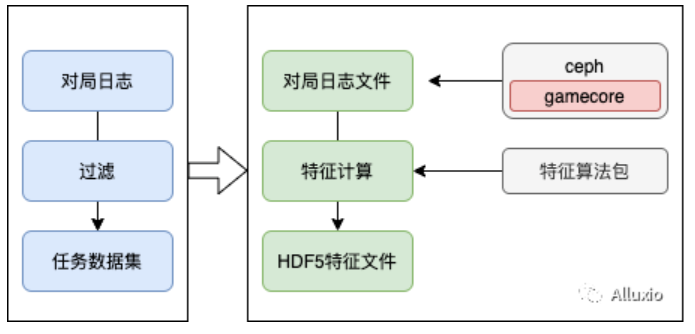
另一个方案是把 gamecore 存储在分布式存储中,例如 ceph,这样数据更新更快, 部署更简单,缺点是 cephfs 的元数据管理服务 MDS 可能会成为瓶颈,通常一次特征计算任务中会调度上千个容器,每个容器会启动若干业务进程,在任务初期会有数千至上万进程对同一个 gamecore 并行访问,每分钟存储端有数百 GB 的读数据量,由于都是小文件,MDS 将承载所有的元数据压力,另外,存储与业务之间的延迟通常较高, 特别是不在同一地域时,有可能导致任务失败率的提升。
综合考量后,我们引入 Alluxio on Ceph 的方案解决业务现状的痛点,在这个过程中,要感谢游戏 AI 团队和运管团队给予的大力支持,游戏 AI 团队给我们介绍了整体业务背景,并协调准线上环境和现网环境,让我们可以对方案进行充分测试后落地到生产环境, 运管团队也在部署架构问题以及资源协调方面提供了大量帮助。
业务支持
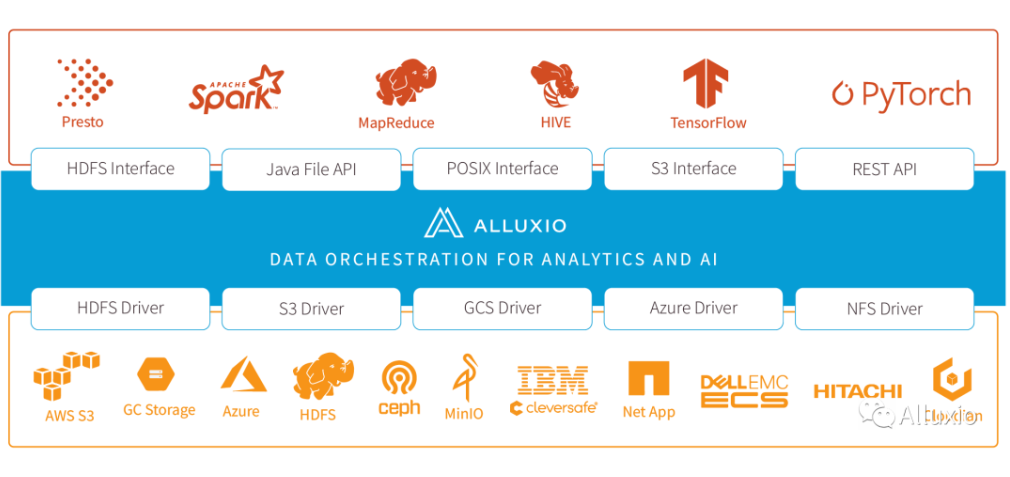
在大数据生态系统中,Alluxio 位于数据驱动框架或应用和各种持久化存储系统之间。Alluxio 统一了存储在这些不同存储系统中的数据,为其上层数据驱动型应用提供统一的客户端 API 和全局命名空间。在我们的场景中,底层存储是 cephfs, 应用是特征计算,将 Alluxio 作为中间层提供分布式共享缓存服务,非常适合对特征计算业务这种一写多读,小文件高并发访问场景进行优化, 主要体现在几个方面:
- Alluxio 提供很好的云上支持,可以方便的在算力平台上对 Alluxio 集群进行部署和扩缩容。
- Alluxio 可以贴近业务部署, 将业务和 Alluxio worker 亲和到同一个 node,利用本地缓存提升 I/O 吞吐。
- Alluxio 的 worker 使用算力平台节点的内存盘,可以提供比较充足的缓存空间,通过 distributedLoad 将底层存储 cephfs 热点数据加载到 worker 中,部分业务直接通过 Alluxio 访问 gamecore,缓解底层存储 cephfs 的压力。
下图展示了 Alluxio 对接业务的架构,本次上线中我们希望支持 4000 核并发的任务稳定运行, 对局特征分析业务每个任务 pod 配置了四核 cpu, 在业务侧提供了 1000 个 pod 的并发。每个 pod 嵌入了 alluxio-fuse sidecar 容器作为客户端,业务的数据读请求直接通过 alluxio-fuse 挂载出来的本地路径,以 POSIX 的形式访问 Alluxio 的数据。
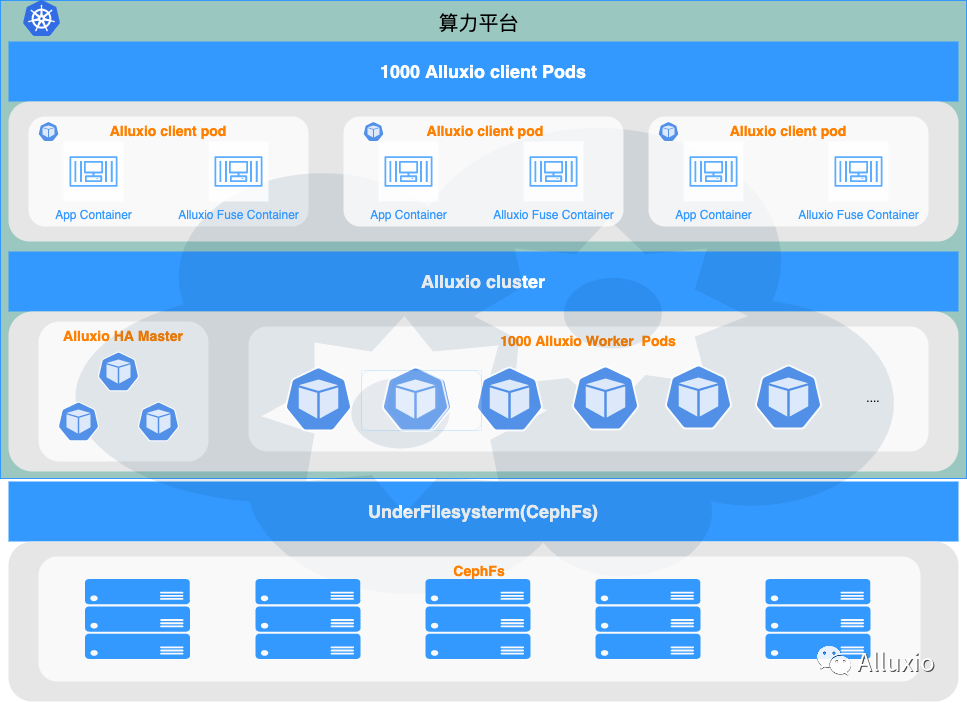
Alluixo 集群 master 节点配置为 HA 模式,worker 的规模为1000 个,我们希望将业务的 pod 和 worker pod 尽可能对应的亲和到一个 node 上,这样做的好处是我们可以利用 domain socket ,进一步提升读取性能。在业务上架之前,通过 distributedLoad 将 cephfs 中的热点版本的 gamecore 版本数据预先加载到 Alluxio worker 进行预热。
研发调优
目前承接特征计算业务的 Alluxio 集群在 AI 和机器学习场景中,属于大规模部署案例(1000 + worker nodes)。业务侧这么大的并发访问对 master 节点的承压能力也是一个挑战, 在上线过程中也经历了多次的调优和新的特性开发达到最佳效果。
开发工作
- 针对本次特征计算 + Cephfs 的使用场景,设计实现了基于 HCFS + cephfs-hadoop + libcephfs 的 cephfs 底层存储实现以及直接基于 libcephfs 的底层存储实现。
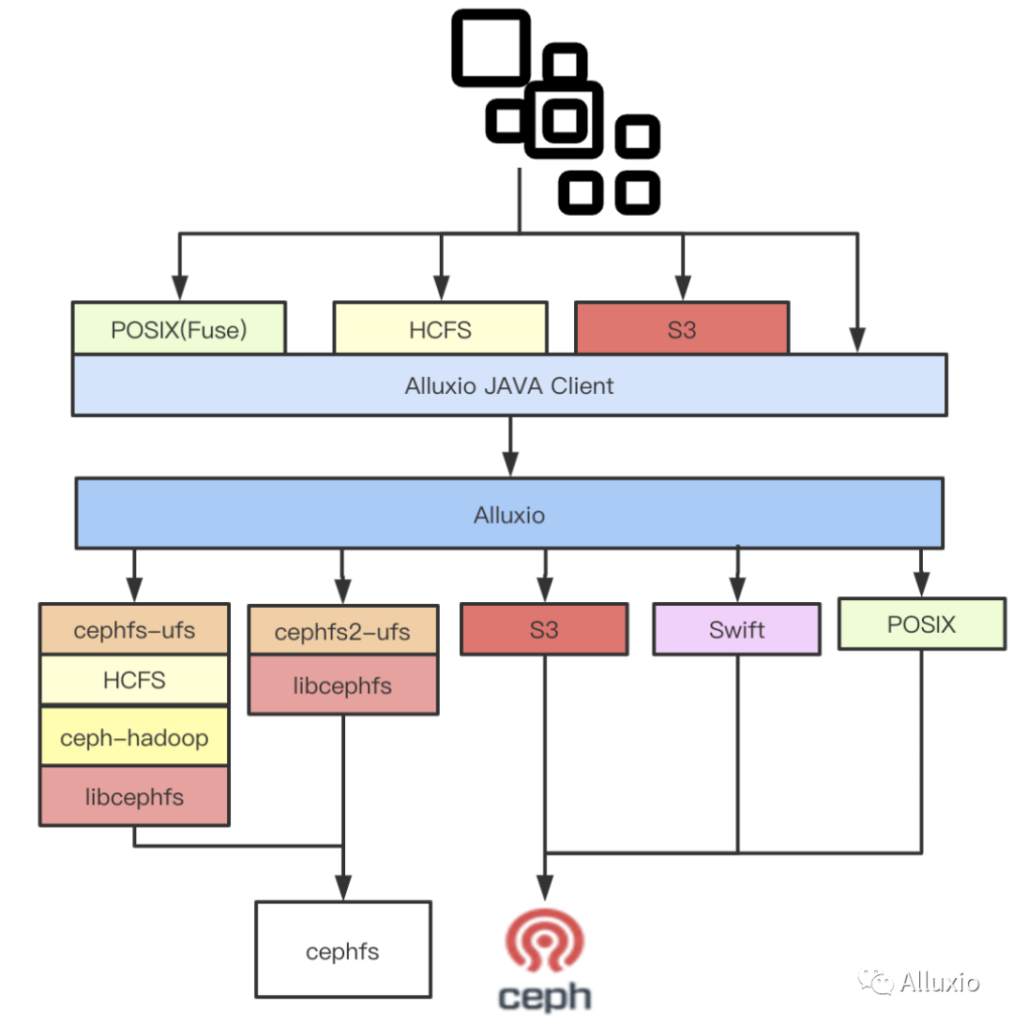
- 与 Alluxio 社区共同设计实现了 HA 切换 leader 到指定 master 节点的功能。
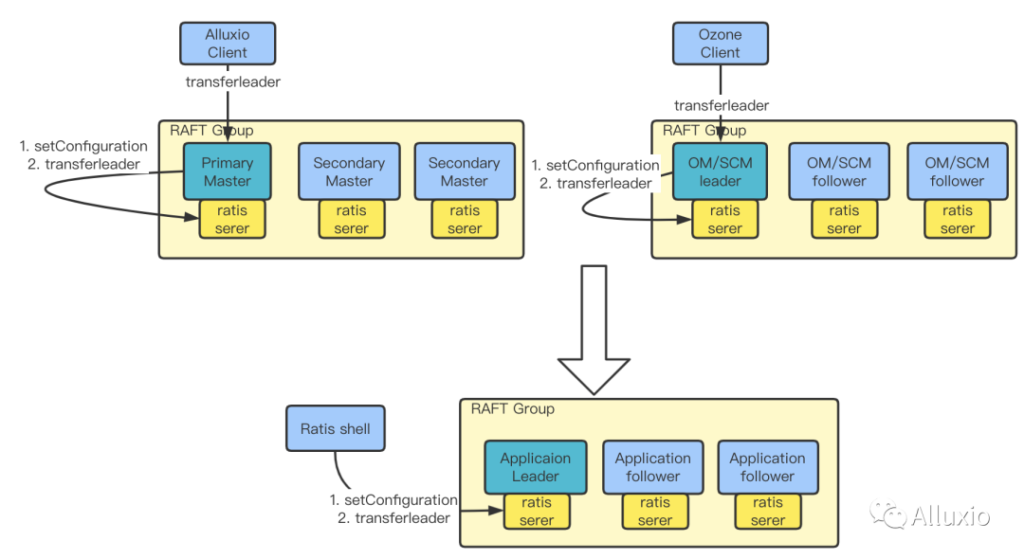
我们将 ratis 相关功能抽象为一个单独的ratis-shell( https://github.com/opendataio/ratis-shell ) 工具,利用 ratis-shell,可以向直接 ratis server 发送 setConfiguration 请求,来设置每个 master 的 priority,紧接着发送 transferleader 请求,确认 leader 切换到了指定的节点上。ratis-shell 适用于 Alluxio 和 Ozone 以及其它所有利用 ratis 的应用。
添加动态更改配置的功能, 可以在线的修改某些集群参数,在尽量不影响业务的情况下优化配置。
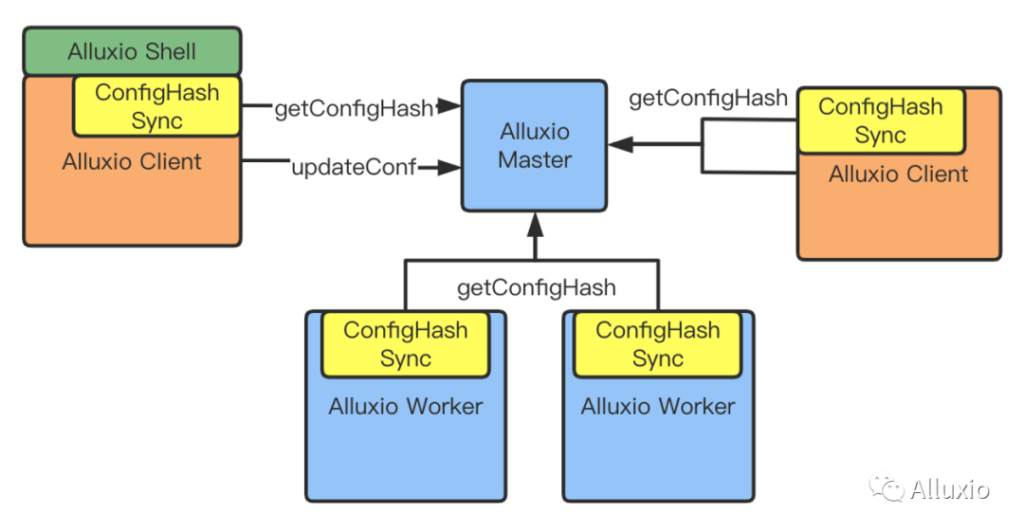
如上图所示,在 Client 和 Master 之间,增加了 updateConf API,通过该 API,可以向 Alluxio Master 发送配置的变更请求,master 把配置更新后,其内部的 config hash 也会变化。其它 Client、worker 等与 Alluxio Master 连接的服务会周期性与 master 同步config hash,也会感知到配置变化,从而同步变化的配置。
- 在 Alluxio fuse client 端,针对业务的这种几乎全读场景,打开 kernel cache 和 Alluxio client 端的 metadata cache 进一步提升提升读性能, 同时对于 metadata cache 的也做了优化, 例如当底层存储元数据改变了,我们可以主动 invalid metadata cache,重新cache,增加灵活性,另外,对 Alluxio FUSE 开启 LocalCache 后,遇到的一些bug进行了修复。
- 增加 master 访问繁忙度指标、ratis 指标、OS、JVM、GC、缓存命中率等等许多有价值的指标,丰富了Alluxio的指标系统。
- 开发查看 Alluxio 关键进程的 stacks 功能, 方便我们跟踪集群状态。
- 充分利用distributedLoad预热功能,期间修复了 Alluxio Job Service 在执行大量 distributedLoad 时出现 OOM 的问题。
配置优化
- worker block 副本数的调整, Alluxio 默认打开了被动缓存功能alluxio.user.file.passive.cache.enabled=true,客户端如果发现数据块不在本地 worker, 则会从远程 worker 拷贝副本到本地,每个 worker 要保存很多副本。这个配置在 1000 个 worker 规模的场景下,会给 Alluxio master 增加巨大的元数据压力,而测试结果表明,这种本地性带来的性能收益实际上很小,因此关闭了这个配置,减轻 master 的压力。
- 使用内部 kona jdk11,并对 master, worker 的 jvm 参数进行了调优,运行同样 workload,使用 konajdk11 + g1gc 没有出现因为 fullgc 导致的 leader master 切换问题。
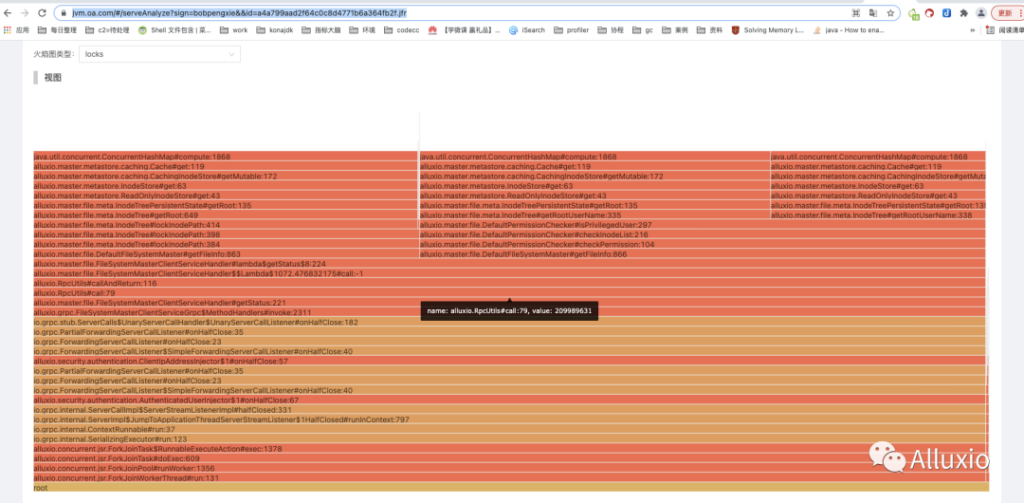
- 通过 jvm 团队的帮助下,我们定位了 auditlog 开启成为了我们纯读场景的瓶颈,通过设置 alluxio.master.audit.logging.enabled=false 关闭审计日志后,吞吐提升7 倍。通过 kona-profiler 抓取的火焰图,发现了使用 ROCKSDB 的元数据管理方式会增加性能开销,下一步我们计划将Alluxio 改用 HEAP 元数据管理方式。
对比测试
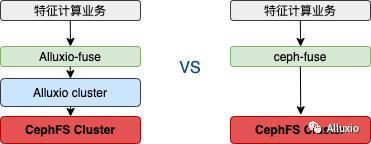
我们将某 moba 游戏,特征计算业务分别对接 Alluxio(UFS为cephfs)和 cephfs 进行对比测试。测试中 Alluxio 的集群信息如下:
- alluxio master: 3 个 master 的 High Availability 方式部署。
- alluxio worker: 1000个 worker, 约 4TB 的存储空间。
- 业务 pod: 1000个,每个 pod 是4个核的并行任务。
- 测试业务:某 moba 游戏 AI 特征计算任务(包含 250000个对局)。
测试结果:

任务直接访问 cephfs, 失败率为2.8%, 任务时长2h40min。任务访问 Alluxio + cephfs, 失败率为0.73%,任务时长 2h46min。
从上述测试结果看,两个方案都能满足业务的需求,失败率均在可接受范围内,使用Alluxio + cephfs 的方案后,业务的失败率更低, 使用 Aluxio 让我们为业务承接更高的并发提供了条件。

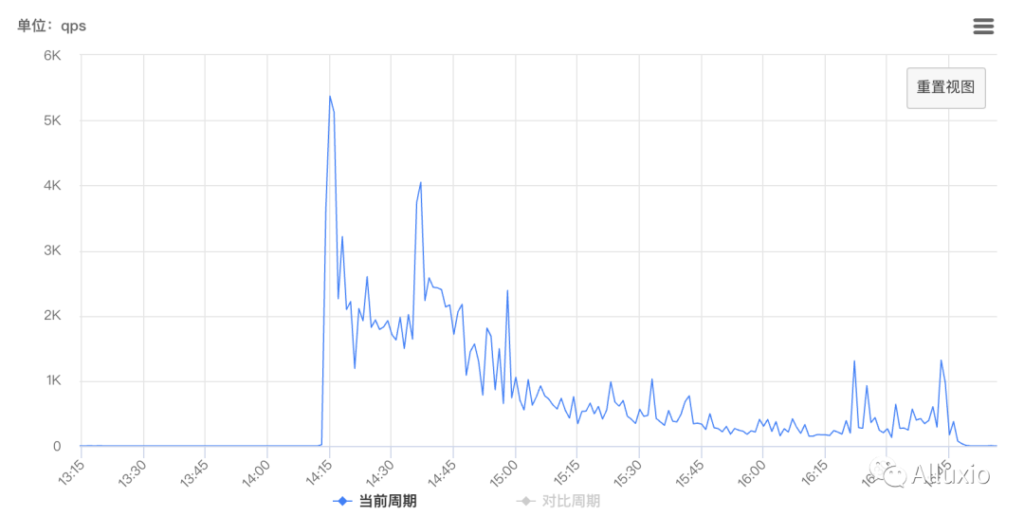
上图是 Alluxio 和 cephfs 的元数据压力指标(rpc count 和 mds 的 qps), 在任务初期会有一个冲击,之后 master 元数据压力逐渐降低。在使用Alluxio 来承接业务的情况下,ceph mds 的 qps 几乎为 0,说明 Alluxio 抵挡了大部分业务压力。
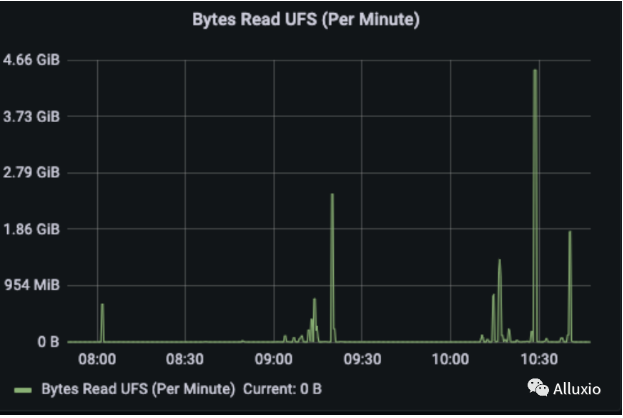
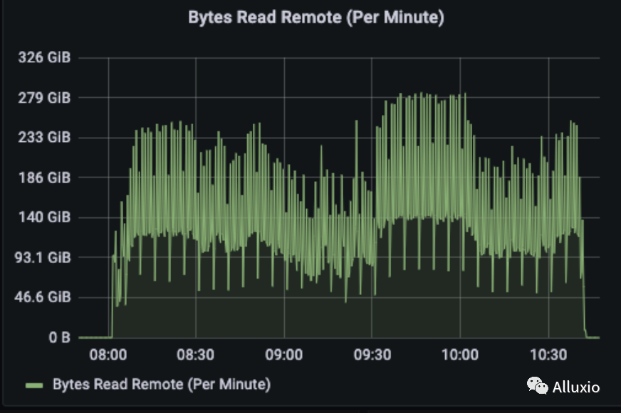
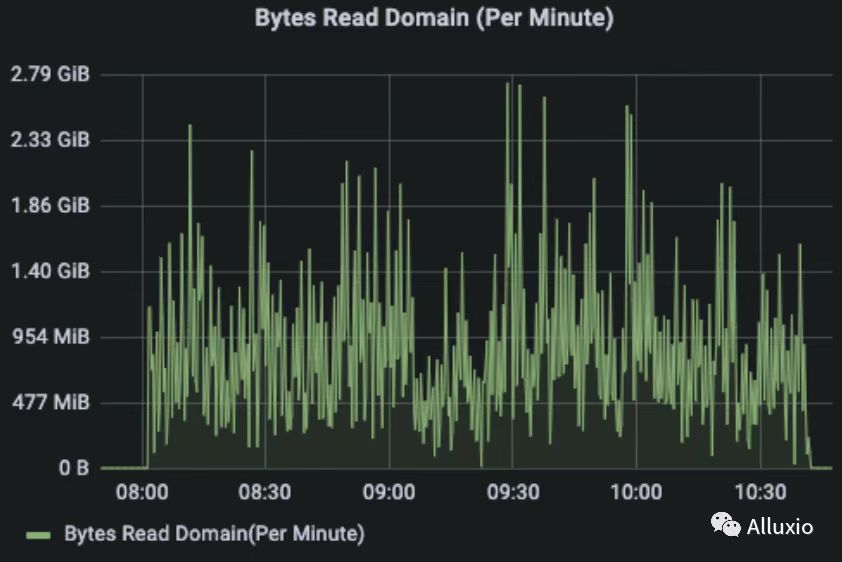
通过 Read Remote, Read UFS, Read Domain 指标观察数据的本地性,可以看到,Remote Read 和 Read Domain 占主要部分, 大部分读流量是 worker 之间的远程读以及本地domain socket读,从 UFS 读的情况非常少。
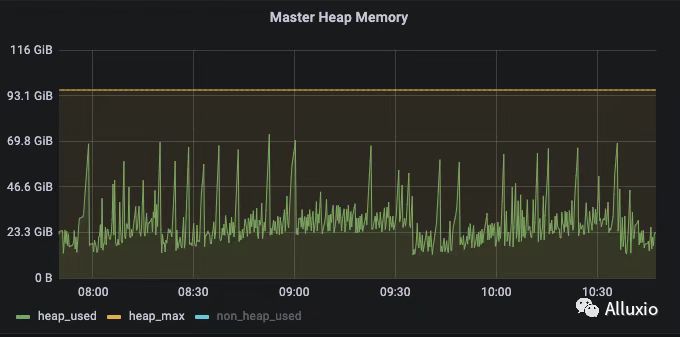
上图为使用了 kona jdk11 后任务执行过程中的heap memory 变化曲线,kona jdk11, 在之前使用官方版本时, master 会出现因为 gc 时间过长,导致 leader 切换问题,在更换 kona jdk11 之后,这种现象没有发生, master 更平稳。
未来工作
- 吞吐上限提升
目前 Alluxio master 在 7000 核并发压力,已经发现 master 的 callqueue 有积压,而且通过 masterStressBench 工具压测出每秒接近 21 万次 rpc 请求的吞吐能力,需要突破上限,最终希望能够提供业务 20000 核的并发。
为了实现 alluxio 集群支持业务无止境的并发访问要求,只做单集群的调优是不够的,还需要设计能够支持更高并发访问的整体架构。
- 利用 Alluxio CSI 解耦业务和 Alluxio FUSE
目前 Alluxio FUSE 是以 sidecar 的形式和业务位于同一个 pod,这样业务方可以独立维护 业务 pod 以及对应的 yaml,而目前的形式,需要和业务团队共同管理业务 pod 中的业务容器和 Alluxio-FUSE 容器。
- 建设 kubernetes 上的 Alluxio 集群管理系统
我们基于 Alluxio 提供的 helm chart 模板,维护了一套用于运维 Alluxio 集群的方案,但是我们希望更进一步,基于 kubenetes API,可以操作每一个 pod 和容器,可以交互式执行需要执行的命令,基于此,我们可以实现底层存储 mount、umount 操作,job service 可视化管理,load free 服务化建设。
总结
在 Alluxio 与游戏 AI 特征计算业务落地过程中,我们支持了业务侧 4000 核并发的稳定运行,从使用效果上看,Alluxio 为底层分布式存储抵挡了绝大部分元数据压力,任务的失败率降低到业务比较满意的范围。另外,业务的高并发大规模场景也暴露出 Alluxio 内核的诸多问题,我们也全部贡献到 Alluxio 开源版本里,同时也增强了 Alluxio 内核的稳定性和可运维能力,可以在未来适配更多场景落地。








