文章为TikTok数据平台团队技术负责人Frank HU使用Alluxio的技术分享演讲。
如今,在已有的Hive数据上,想要将Presto这样的流行的查询引擎与Alluxio相结合不是一件容易的事。尽管社区给出了一些解决方案,如Alluxio Catalog Service或者Transparent URI,但是当被查询的文件不需要被缓存时,这样的做法会给Alluxio的master带来不必要的压力。本次分享将会介绍,TikTok 是怎样将Alluxio用于缓存层,而不引入额外服务。
-TikTok数据平台团队技术负责人 Frank HU
本次将与大家分享我们在TikTok使用Alluxio提升Presto性能的历程。
分为以下三个部分:
· 运行在Presto集群上的作业
· 将Alluxio与Presto结合的方式(不同于社区的做法)
· 缓存和调度策略

Presto Use Case
我们的Presto作业简介如下图所示。我们主要使用Presto来查询储存在HDFS中的Hive表。目前,每天有大概六十多万条只读的interactive SQL。图中也列出了我们的集群规模。

这里面想强调的是——数据源。第一,我们主要的数据源是HDFS上的Hive表;第二,Presto引擎使用Hive表的元数据(Hive Metastore)是共享的,会被其他的引擎或者数据库(如Spark,Clickhouse)使用。因此,当将Presto与Alluxio结合的时候,数据源的特点也是要考虑的重要因素。
为什么需要缓存?
一个基本问题:在优化性能时,为什么缓存是我们第一时间想到的?鉴于Presto是一种MPP模型的查询引擎,对此认为延迟(latency)是在Prseto中的主要优化目标。在分析了我们在Presto上的所有SQL之后,发现出三个问题:
1.最主要的性能瓶颈在于IO。这与之前的另一场分享中的观点也是一致的,那里面提到,如果他们将数据进行缓存,则可以获得10倍到20倍的IO提升。
2.另一个问题是,HDFS datanode慢节点现象。如果你对同一批文件块有非常高的并发读需求,那么有些datanode可能会变得非常慢,使得所有需要从这里读取数据的查询都被阻塞。
3.此外,如果不做缓存(尤其是本地缓存),你的worker节点将竞争网络资源。Presto集群上的网络带宽不仅仅被用于IO,在shuffle阶段,Presto worker之间的大量数据传输也会占用很大的网络带宽。因此,如果我们能在初始表读取阶段就节省下网络开销,就能为其他operator的执行省下网络带宽。
因此,就自然想到了缓存。而缓存是一把令人又爱又恨的双刃剑。我本人经常开玩笑说“最好的缓存就是没有缓存”。因为缓存的实现可能会非常复杂,并带来许多问题。以下我列出了其中一些问题。

在这里不会一一讨论这些问题。如果大家有开发过任何网站应用的经历,那这些问题一定很熟悉。
比如说,我们经常强调数据一致性(consistency)。如果使用缓存,它一定能提升你的IO速度,但是,总需要考虑一个问题:如果缓存与远端的数据不一致怎么办?
另一个问题是数据本地性(data locality),或者说,缓存命中率(cache hit rate)。在Presto中,我们总是希望Presto worker能命中同一台物理机器的缓存,而不是从别的机器中获取数据。
开源的集成方式
既然Alluxio这么好,那我们能不能直接用呢?
那么遇到的第一个问题是,怎样将Alluxio与Presto一起使用。在开源版的代码中,我们发现了两种解决办法:
1.Hardcoded URL Swap
可以直接将Hive MetaStore中的Location属性从hdfs://改为alluxio://。这样,你的Presto就能直接从Alluxio中进行读取了。这种方法很适合于POC或者快速上手,但是如果要用于生产就会有问题。在我们的环境中,Location信息不仅仅被Presto使用,许多查询引擎都会共享Hive MetaStore中的元数据信息。因此,这种方法虽然简单,但是会迫使我们环境上的所有查询引擎都改为从Alluxio中进行读写,这样当然是不可行的。
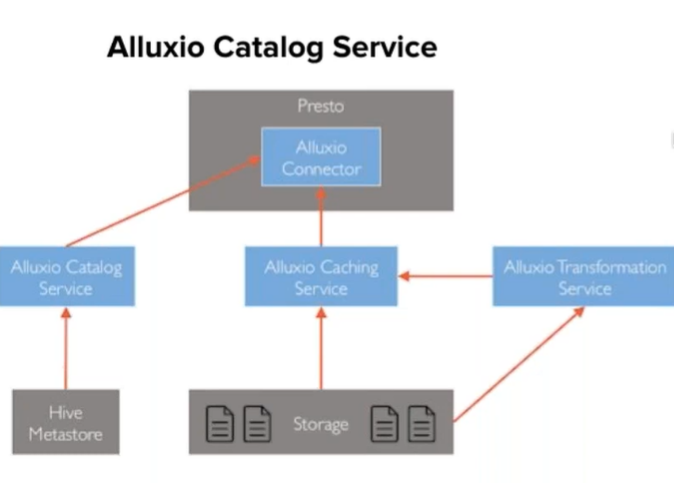
2.Alluxio Catalog Service
另一种方法是使用Alluxio Catalog Service(如下图,来自Alluxio的文档)。简言之,这是在Hive MetaStore上的一层代理,其中也做了些优化catalog layout的设计。但是问题在于,如果我们使用这一服务,每一次请求都得经过它。这种做法可能给Alluxio Master带来巨大的QPS压力。相较于HDFS设施,Alluxio Master可能无法扩容到足够的程度来应对Presto的流量, 因为即使不命中Alluxio缓存的查询, 也面临着额外网络请求开销。举个例子,Alluxio中只缓存部分Hive表,但是对于未缓存的Hive表,还是得与Alluxio Catalog Service进行交互。另一个问题是,每次Hive MetaStore发生改变时,都需要与Alluxio Catalog Service做一次手动同步。
好消息是,Alluxio能很好地帮你应对这些问题。比如,Alluxio提供了active sync机制来处理一致性问题,而对于本地性问题,Alluxio提供了dynamic replica来提高每个数据块的副本数。因此,在经过大量初期调研后,TikTok选择了Alluxio,因为它提供了很多有用的feature,能帮助解决这些问题。
内部的集成方式
下面将介绍TikTok是如何将Presto与Alluxio结合的。
解决方法其实很直接,因为实际上,从Presto这一侧,只需要两个信息:原本的HDFS路径和可选的Alluxio路径。想要在不改变Hive MetaStore api的前提下达到这一效果,一种可行的方法是将Alluxio路径保存在一个单独的table/partition参数中。因此我们在HMS中增加了一个cachePath参数,用来传递Alluxio路径信息。
基于此,我们对Presto进行了一些修改。让Presto Coordinator在加载或传递HiveSplit路径信息时,既加载HDFS路径,也加载一个可选的Alluxio路径,并且在读取时,优先从Alluxio路径中进行读取。这是一个很简单的改动,但是可以让你在不引入额外的第三方服务和额外网络开销的前提下,把部分Hive表缓存在Alluxio中。
我们做的另一个改动是,对Presto中的CachingFileSystem类进行继承,兼容从HDFS和Alluxio两个FileSystem中读取文件。这样,如果对Alluxio的读取超时或者失败,就可以自动fallback转为从HDFS读取。这一改动的出发点在于,TikTok暂时只是将Alluxio作为一个只读的缓存,因此我们希望在有需要的时候,能随时停止使用缓存,并自动回退到使用HDFS进行读取。在实际生产中这种回退并不常见,但是我们必须要有这样一层保险,以应对一些特殊情况(比如Alluxio集群正在重启或升级)。
光有缓存还不够
在完成以上的工作后,我们在一些数据集上快速进行了测试。
初期的结果是不错的,在一些来自生产环境的样例SQL上,可以看到30%的延时下降。但是,当在一些更通用的benchmark(如TPC-DS)上进行测试时,这一收益就降到了17%。
为了搞清楚为什么端到端性能提升不如预期,我们分析了这些SQL。其中一个教训是,你需要能分辨那些IO密集型的SQL,才能最大化利用缓存所带来的收益。如果你的SQL有大量的join或者aggregation这种主要取决于CPU的操作,使用缓存可能只会对执行过程中的某些部分带来优化,而不能给端到端性能带来明显的提升。
定制化缓存策略
因此,我们使用了定制化的缓存策略,为了确定哪些表应该被缓存。我们不希望盲目地把所有表都缓存进来,而Alluxio默认提供的LRU策略对我们来说也不够完善,所以我们根据自己的查询模式设计了优化的缓存策略。
我们在Presto上收集了一些数据。对于每一条SQL,Presto都会生成这样的JSON对象,如下图。其中包含了Presto执行阶段的每一个stage和算子的元数据信息。

目前,与Alluxio相关主要是IO缓存,所以TikTok重点关注两类算子:表扫描算子(TableScanOperator)、扫描过滤投影算子(ScanFilterAndProjectOperator)。这两种算子基本上代表了从远程存储进行初次读取的过程。通过收集到的JSON数据,可以统计分析在这些读取上花费的时间和数据大小,从而设计出我们自己的缓存策略。
一开始的设计还是十分简单直接的。大体上,聚合出过去M天里最耗时的N个partition(M取决于你的Hive表的时间跨度和你的Alluxio缓存大小)。收集这些数据后,我们的策略实际上要解一个背包问题:在给定的Alluxio空间里,找到一个最佳的partition集合来用于缓存。
有了这样的策略,就进一步引入了一个Cache Scheduler模块。这个模块主要做两件事情:
1.Triggering
Cache Scheduler会订阅HMS changelog来监控partition的增删改事件。每次收到相关事件,就根据缓存策略来决定新增的partition是否应该被缓存。一旦决定要进行缓存,Cache Scheduler先将这个partition挂载到Alluxio,再在HMS中修改Alluxio路径。
2.Cleanup
Cache Scheduler还会启动一个后台任务用于清理。我们为缓存对象设置一个TTL,即这个缓存应该在Alluxio中存在多长时间。因此,一个后台任务会周期性地根据缓存策略从HMS和Alluxio中清理缓存。
总体流程
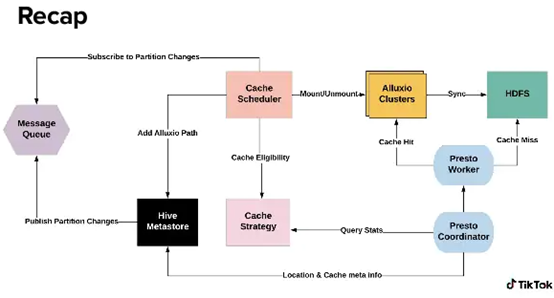
从Presto Coordinator开始,在每次SQL执行阶段,Presto Coordinator会将上文提到的JSON对象传递给Cache Strategy用于计算。在读取数据时,Presto Coordinator会加载HDFS Location信息和Alluxio缓存的元数据信息,并将这些信息传递给Presto Worker。Presto Worker可以灵活切换读取模式:如果设置了Alluxio路径,就从Alluxio读取,但如果出现了缓存不明中的情况,也可以回退到从HDFS读取。
另一方面,Cache Scheduler会持续监控catalog服务中的changelog,并根据缓存策略来决定是否要进行相应操作,比如将某些partition加入缓存并挂载到Alluxio。
总体性能测试结果
最终,总体性能测试的结果在我们看来还是相当好的。
1.Presto查询时延的P95值下降了41.2%。
2.在每周的数据上,缓存的覆盖率(cache coverage)达到了32%,而缓存磁盘的空间占用相比于每天的HDFS增量仅为1%。
3.在TikTok的测试用例中,91.1%的cache hit SQL取得了超过20%的时延下降。
下一步工作
自去年12月开始,TikTok开始使用Alluxio。接下来,会继续加强与社区的合作。
首先,我们会关注“alluxio-as-lib”:
1.关于缓存一致性(issue-13700),在TikTok的环境中,不能认为远程的数据源永远是不变的,然而在目前的实现中却是这样假设的。我们将和社区一起着手解决这一问题,我们正在尝试利用文件的最后修改时间来判断本地缓存是否已经过期;
2.对Presto端的改进。目前的Presto Soft Affinity调度算法是哈希后基于worker数量取模. 这就意味着如果有一个worker掉线了,那么整个缓存的分布都要发生改变,由于重建缓存的操作十分昂贵,可能缓存命中率会一下子下降到0。因此我们希望在这里能做出改进。
3.Alluxio Structure Data这个想法非常好。简而言之,这是一个transform服务,能让你对缓存进行修改,可以对其进行解包并将其转变成更加复杂的结构。不过目前这个功能只在Alluxio的分布式缓存中可用,我们也希望能在”alluxio-as-lib”中支持这一功能。
另一方面,虽然目前主要将Alluxio用于只读缓存,但还是希望能在有些场景下将其用于写缓存。一个典型的需求是,如果你有很多彼此依赖的ETL任务,现在只能将中间结果都写入HDFS中,后续的任务再从HDFS中读取。我们正在尝试在Alluxio中开启写缓存,来作为一个中间结果的服务,从而将多个ETL任务连接起来,而不用通过HDFS这样的远程存储。








