本次分享主要分为以下部分:
离线推理作业的特点
运行大规模推理作业的挑战
系统实现框架与优化
性能评估
未来工作

李镔洋
微软STCA软件工程师。负责Bing内部机器学习训练和推理平台的开发与优化。参与开发和维护微软开源机器学习平台。

张虔熙
微软亚洲研究院高级研究工程师,负责数据库和存储系统的研究和开发工作。拥有多年大数据开发经验,曾负责超万节点大数据平台的架构优化和演进。负责Cache as a Service在公司内的落地。
离线推理作业的特点
这个部分我将介绍离线推理作业的特点。
首先介绍一下离线推理作业的规模。我们使用的离线推理作业中,每个作业都包含超过400个任务。每个任务都读取不同的数据集并且生成对应的输出结果,并且任务之间没有任何交互。每个任务都会读取约2-3GB的数据,生成约7-8GB的数据,所以整个作业读取和输出的数据是很大的,约读入1TB的数据,产生3.5TB的数据。完成一个任务需要花费约2-4个小时,这是一个长时间运行的作业。
离线推理作业的数据获取模式是十分简单的,这类作业仅仅需要顺序读入一次输入数据,并且在作业运行时就可以写输出数据到Azure Blob。这与训练作业不相同,训练作业是在每个回合都将所有的输入数据读取一轮,而离线推理作业仅仅只读取一次。
最后我介绍下我们使用的基础架构。我们使用Azure Blob作为存储系统,使用开源项目OpenPAI作为AI训练的平台,使用开源项目Hived作为调度组件,将每个作业调度到对应的节点上。
运行大规模推理作业的挑战
· 处理大量的输入和输出数据容易造成IO故障。
· 像blob-fuse这样的工具会在运行任务之前下载数据,并且在作业结束后会将结果进行上传到Azure Block云存储中。在我们的例子中,每个作业都包括接近400个任务,这些任务几乎是同时开始运行的,这也就表示几乎同时开始下载数据,这就容易造成较高的IOPS并且容易到达Azure Blob的带宽限制。由于任务的相似性,他们几乎是在同一时间结束,所以他们会在同一时间将输出结果上传到Azure 存储系统中,这也容易到达Azure blob的带宽限制。如果到达了Azure blob的限制,那么这个任务就会失效,此时就需要重新执行作业中的任务,这是非常耗时的。
· 当使用像blob-fuse的工具时,在作业开始时会开始下载数据,当作业完成时会开始上传数据。在下载或上传数据的时候,GPU是处于空闲状态的,这不仅耗时而且还浪费资源。
Prod bed环境
· 使用约200个Azure低优先级虚拟机,每个虚拟机有4个GPU。这里需要注意的是虚拟机是采用的可抢占式的策略,随时会被回收,这也就使得环境不太稳定,我们需要通过一些措施使得训练平台变得更加稳定。
· 使用 Alluxio 2.3.0
· 使用 Kubernetes 1.15.x
· 使用Alluxio运行超过6个月,运行情况良好。
带有Alluxio的系统组织架构
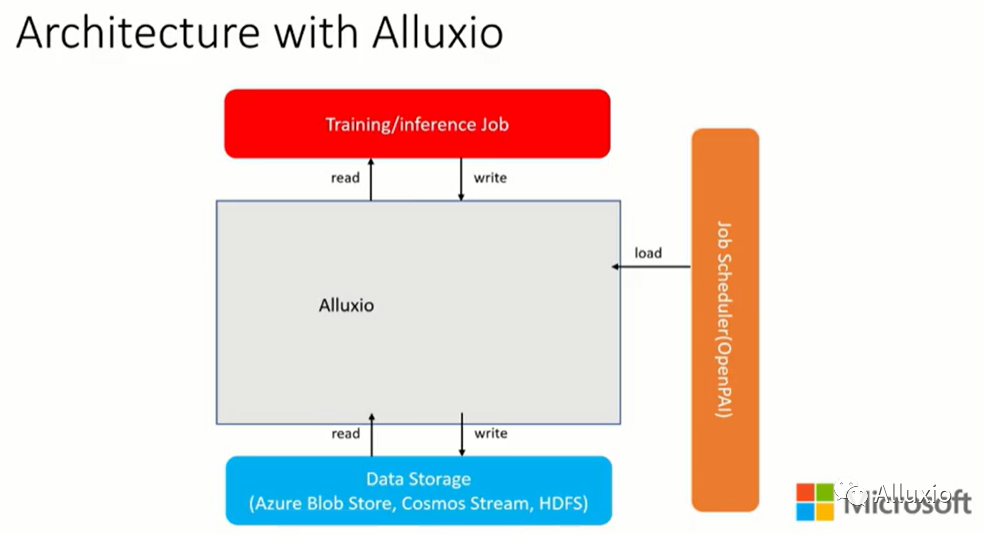
当用户提交一个作业时首先会进入到作业调度器组件中。在作业开始运行之前它会向Alluxio发送一条命令将部分数据预取放到缓存中。当预取好数据之后,作业调度器会将作业调度到对应的节点上。作业可以直接与Alluxio进行读取或者是写入数据而不需要与数据存储组件进行交互。另外,在Alluxio组件中,我们还希望实现自定义数据替换策略使得作业运行更加有效。
优化-基于deployment的CSI
我们从Alluxio社区发现Alluxio有多种部署方式。最基本的部署方式是在每个节点上都部署一个fuse守护进程。所有的作业都与部署在这些节点上的fuse守护进程进行交互,来读取或写入数据。但这种部署方式并不能很好的满足推理任务对读和写的不同需求。
对于推理任务来说,在进行任务读取的时候,所有的任务都需要读取模型文件。我们可以将模型文件缓存在Alluxio中,同时为了使得其运行更加有效,我们需要将模型文件的元数据也进行缓存。所以我们需要打开元数据缓存,设置开启内核缓存,设置比较长的超时时间。而对于输出数据而言,我们需要将数据输出到对应的目录中,因此需要关闭缓存元数据,还需要自定义Alluxio配置文件来确保数据不会丢失。针对读和写的不同需求,我们采用了基于CSI的部署方式。

这是一个如何使用CSI的一个例子,对每个CSI的挂载点都可以提供一个配置文件,可以自定义挂载操作并且自定义Alluxio配置,例如设置挂载在Alluxio中的挂载目录。这对于我们是十分方便的。同时还可以设置一些自定义的挂载选项。
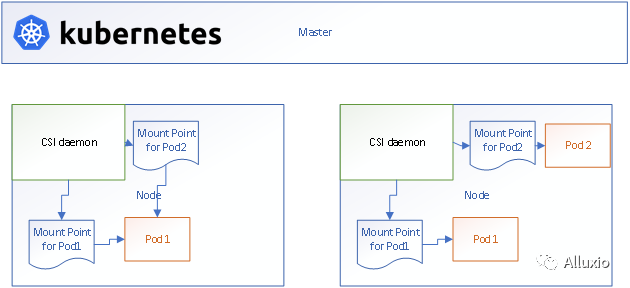
对于每个推理任务而言,我们提供了两个挂载点,一个用于进行读取数据,一个用于进行写入数据。每个挂载点都有一个守护进程与之对应。
基于CSI的部署方式具有以下优势:
· 系统可针对不同的读写场景进行分别配置从而使得任务更加有效。
· 对于每个pod而言都会有属于单独的fuse守护进程,如果一个fuse守护进程失效后,只会影响到与之对应的工作负载,对于其他在相同节点运行的工作负载都不会产生影响,这提高了系统的鲁棒性。
· 每个作业都可以挂载到不同的路径,并且每个路径可以被管理员控制,所以管理员可以提供一些设置配置,给CSI持久卷。对每个作业都选择其中的一个卷。如果管理员不提供对应路径的配置,调度到该节点的作业就不能够使用该路径并修改对应的文件,从而可以确保系统的安全性以及访问控制权限。
优化-Fuse 客户端优化
我们的系统对于fuse客户端也进行了优化。
在我们的例子中主要处理的是离线推理作业,这类作业会产生大量的输出数据,并且这些数据是对于我们和数据科学家都是至关重要的。为了使得输出结果更加安全可靠,我们在fuse 客户端中进行优化。
第一个是flush函数优化。平台用户反馈当作业结束之后产生的输出结果却丢失了。我们对此进行了调研,最后通过在fuse 守护进程中实现flush 函数来避免了这个问题。当一个作业完成之后,系统会自动调用flush函数。通过对flush函数优化,可以确保不丢失输出数据。
第二个是release函数优化。有些用户想要对输出数据进行进一步处理以便进行其他的实验,但是他们进行后续实验时发现输出数据文件不能够被打开,并且在Alluxio日志中发现之前的作业并没有完成。我们对此进行了调查后发现Alluxio中的release 函数是异步的,我们会误以为任务已经完成,但是实际上由于release函数是异步的,所以可能关闭文件的函数是没有完成的。此时由于客户端认为作业已经完成,所以客户端关闭了,由于客户端与服务端的grpc通信无法继续,这使得服务端的关闭操作无法执行完成。优化后在release函数和unmount函数中添加一些逻辑使得在进行解挂载之前确保所有的客户端请求的操作都被Alluxio 服务端处理。
通过解决了这两个问题,我们的系统更加稳定可靠。
预取功能
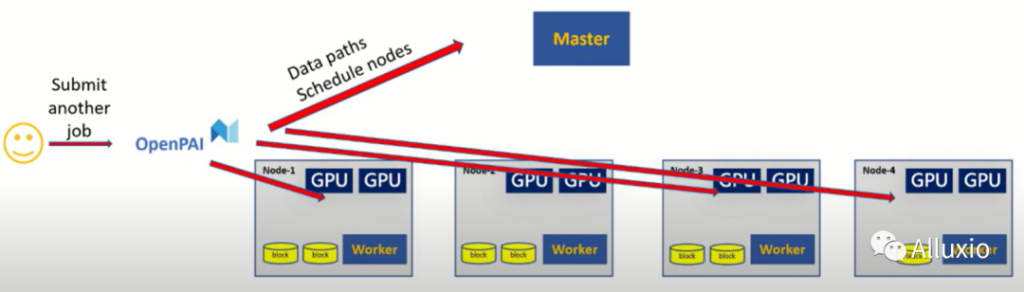
这一部分介绍预取功能。
我们在作业真正开始运行之前将数据通过Alluxio提前缓存在缓存系统中。通过这种操作,作业不需要等待数据进行获取而是可以直接进行执行。
首先当用户提交一个作业到OpenPAI中,然后作业调度器会进行调度。如果在集群中存在一些任务正在运行,此时就需要进行等待一段时间。但是此时OpenPAI可以向Alluxio master发送预取命令,然后数据就会被进行缓存。所以在作业真正运行时,工作负载已经被进行缓存,此时OpenPAI会将作业调度到对应的节点上直接进行运行。
性能评估
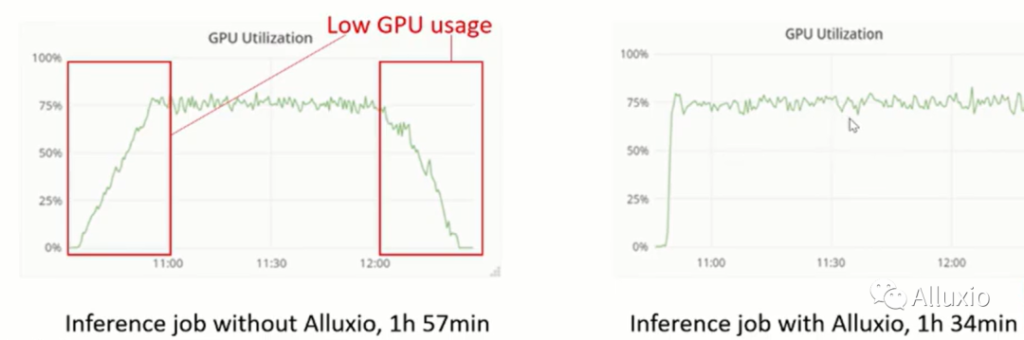
这一部分展示一些实验结果。
从实验结果可以得知,使用了Alluxio进行优化后提升了作业运行速度。上图中左侧是没有使用Alluxio进行加速时GPU利用率变化情况,而右侧则是使用Alluxio的。
如果没有使用Alluxio,可以发现作业需要首先下载数据,然后当任务结束之后需要一段时间将数据进行上传到Azure Blob中。
在使用Alluxio时,我们仍然需要一段时间来下载数据,但由于并不需要把数据全部下载下来,所以这个时间并不需要很长。在作业结束的时候不需要进行等待,这是因为推理作业会在作业运行的过程中输出数据并进行上传。由于作业需要超过两个小时的时间完成,所以这种方式缓解了作业对I/O系统的压力。这使得IO请求更加平滑。
Alluxio还带来其他的一些优势,例如读重试。如果读取失败会自动进行重新读取,从而降低了作业运行的失败率。
通过引入Alluxio,我们优化了推理作业,使得其性能提升了大约18%。
未来工作
1. 写操作失败重试。Alluxio中只对读操作有重试逻辑但是对写操作没有。客户端想要进行写数据时,会首先发送请求给worker节点,然后worker会进行处理相关数据。如果worker节点出错,那么写操作就会失效,进而导致作业的失败。我们使用的环境是Azure Low Priority VM,所以worker节点可能在任何时候被Azure 回收。如果worker节点发生了问题,那么我们的任务就会失败。我们希望添加写重试使得我们的系统更加可靠。
2. 将Alluxio使用在训练作业中。训练作业有着特殊的数据访问模式,每个回合都会读取一次相同的输入数据。我们需要提供新的数据替换策略来使得训练作业更加有效。
引用
· OpenPAI:microsoft/pai:Resource scheduling and cluster management for AI (github.com)
· Hived:microsoft/hivedscheduler:Kubernetes Scheduler for Deep Learning (github.com)
· Alluxio-CSI: Alluxio/alluxio-csi (github.com)








