在2021年Alluxio社区活动日第五期活动中,来自MOMO的大数据平台工程师 孔云龙,为我们介绍讲述了Alluxio数据加速在MOMO的实践与应用。

“以下为孔云龙先生在大会中的演讲实录
孔云龙,在MOMO数据基础架构团队担任大数据平台工程师,主要负责方向为分布式存储(HDFS、Alluxio、对象存储、Hbase等)。
我很高兴能够参加Alluxio Day的分享,我是来自陌陌的大数据平台工程师孔云龙,今天我分享的题目是Alluxio数据加速在陌陌的实践与应用。简单介绍一下自己,我是15年北邮毕业,之后加入京东商城,在京东商城主要做kafka、spark、hive,presto的相关的工作, 18年加入陌陌,工作的方向主要是分布式存储,主要参与陌陌大数据平台的建设,提升存储系统的性能稳定性,同时为机器学习推荐等提供一些相关存储服务。
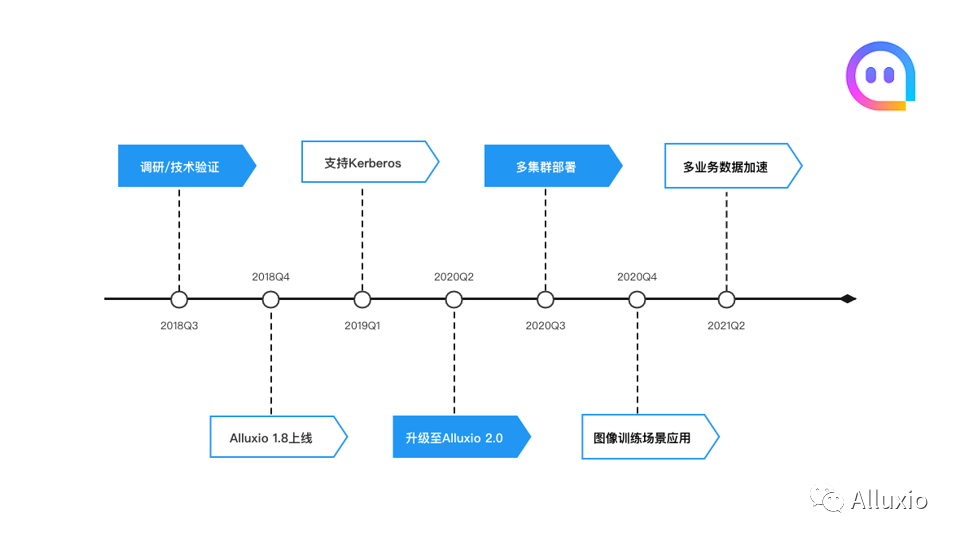
简单说一下Alluxio在陌陌的发展过程。我们是18年开始调研Alluxio,当时还是1.8的版本, 然后在18年的Q4,我们上线了1.8.1版本,当时上线集群规模是300, 之后我们整个大数据平台做了kerberos的认证改造。19年Q1时,我们上线了Alluxio kerberos功能,当时集群的规模达到900台。从去年,也就是20年Q2开始,我们开始调研Alluxio2.0版本,到20年的Q3,我们把我们之前的Alluxio 1.8.1的版本升级到了社区的Alluxio 2.3.0的版本。
当时我们部署了两个集群,一个大的是1200台,然后另一个是400台左右。目前的话我们这两个集群也都是升级到了2.5.0-1的版本。从20年Q4我们开始尝试其他的一些场景,像机器学习的一些训练等场景中开始使用Alluxio。到今年的Q2我们又开始拓展到其他的业务,通过Alluxio提供一些数据的加速,像主要应用在推荐和图像检索,这个在后面会详细介绍。

今天分享的内容主要有两块,一个是Alluxio在陌陌加速数仓查询的工作,另一个是Alluxio加速机器学习的场景应用。
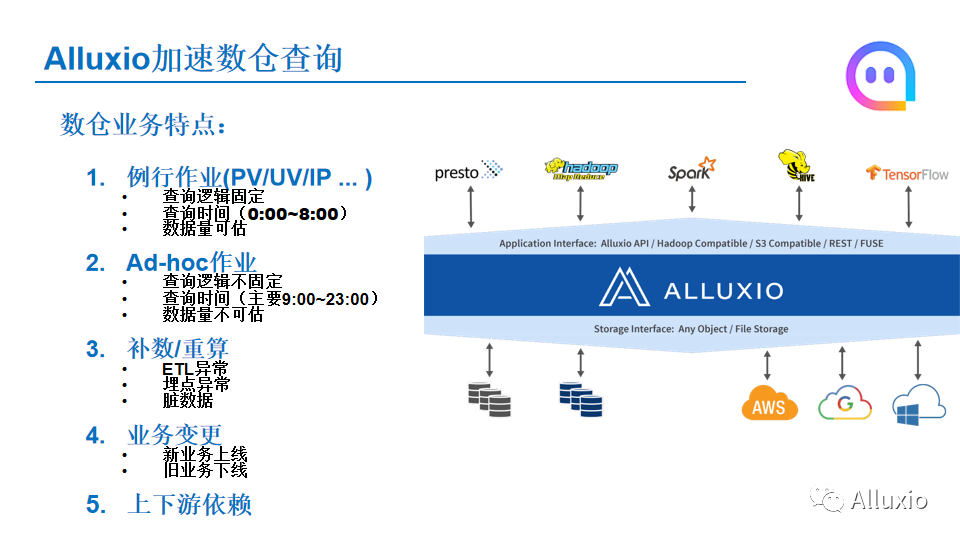
然后说一下就是陌陌这边数据仓库业务的一个特点,我们的数仓主要提供SQL的查询,这些SQL作业,大体上可以分成分为两种类型,一个我们称之为例行作用,就像我们数据分析团队每天要计算一些PV/UV/IP的数据,这些作业都是固定的,他们的的查询时间也是比较固定的,基本在凌晨的2点到第二天的8点,相当于上班之前他们要把这个数据计算出来。因为这些作业是比较固定的,所以他们的数据量也是可以预估的。
第二种的话就是平时比较多的Ad-hoc作业,对于这种作业,负责数据查询的同学需要根据一些新的数据分析,进行一些分析,这种情况下,他们的查询逻辑是不固定的。就查询时间而言,因为Ad-hoc主要集中在白天的9点到晚上11点这个范围内,因为是Ad-hoc机器查询,所以每个查询要读取的数据量的时间是无法预估的。
数仓作业还有几个特点,它存在一些补数/重算的情况,因为整个数据在进入到数仓平台的过程中,像ETL等可能会出现一些异常,前面的埋点等也有一些异常,或者是进来的数据有一些脏数据,这个时候可能数据需要重算或者补数,这种情况下就会涉及之前加载的一些数据,它的元数据或者名字等会发生变更。
另一个就是业务的变更,因为经常会有新业务的上线,旧业务的下线,所以数仓中的表也是在不停的变化,可能过段时间就有新的表要上线,有旧的表要下线。
还有另外一个特点就是很多数仓作业有上下依赖关系。比方说有一个作业要查询b表,而b表的生成可能需要依赖上游的a表,a表产生之后,才能进行下面b表的一些相关操作。

根据这个业务特点,我们提出了两种概念,我们称之为HotTables和PreLoad,什么是HotTables呢?HotTables就是热表,也就是在数仓中被用户频繁访问的表,比如我们有一张表, 里面存储了陌陌所有注册用户的一些信息,比方说手机号,注册时间等,可能有很多其他的业务都依赖这个表,所以这这个表所以在很多SQL中都会出现,所以像这种类型的表我们就称之为热表。如何在数仓平台中获取HotTables呢? 我们通过下面几个步骤来获取HotTables。首先我们数仓上所有的查询记录,都会记录到Phoenix中,包括作业是提交到哪个机房,使用的是哪个查询引擎, SQL的起止时间,查询的库表, 读取的数据量,这些都会进入到Phoenix,然后我们会周期性地查询Phoenix分别针对例行作业和Ad-hoc作业生成对应的热表。最简单的一种方式是,可以根据所有作业中表出现的频次,频次从高到低排序,出现在最前面的那些表就称之为热表。
之后我们会把热表存到zookeeper中的一个znode上,然后我们又做了一个操作,就是根据生成的热表,会有PreLoad,也就是预加载操作,我们会周期性地check当天热表数据有没有产出,如果有产出的话,我们会通过Alluxio的distributed Load,把这个热表加载到Alluxio,加载后,当作业进行查询时,就避免了第一次加载数据到Alluxio的过程。 这时候查询的话, 就会命中Alluxio中的表。还有一个操作,就是我们会定期地更新这个热表,根据我们之前的一个规则,我们会移除旧的热表,同时也会把一些数据从Alluxio中移出。
在数仓中我们还需要考虑的一个问题就是语言数据的同步问题,前面已经说到,会有一些数据的重算的情况,当数据重算之后, Alluxio中保存的一些数据和元数据其实都过期了或者可以理解成脏数据,如果这时候用户再去查的话,整个查询的结果也是错误的。
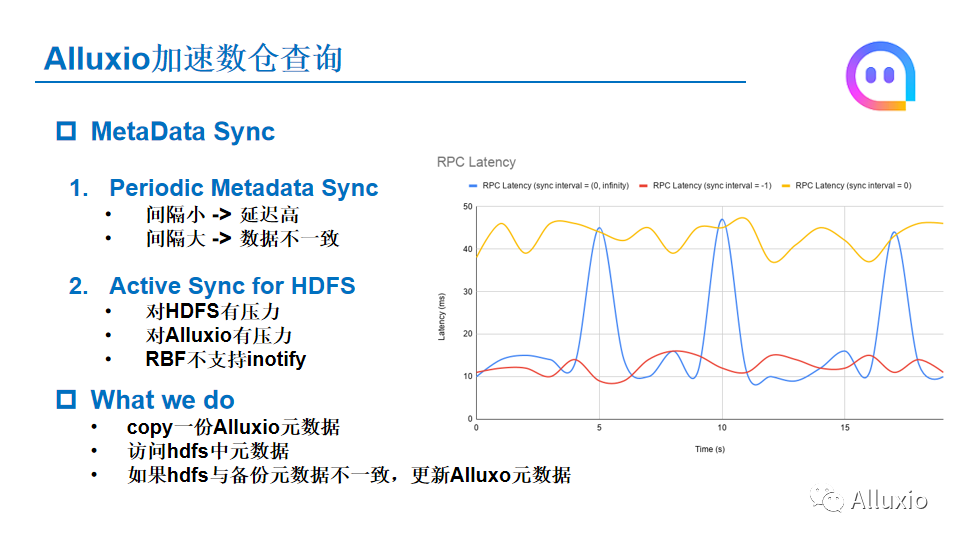
Alluxio有两种元数据同步方案,一个是periodic metadata sync,这种就相当于我们在元数据同步的时候,手动设置元数据多长时间进行同步一次,如果设置的间隔小的话,那么 Alluxio所有的元数据经过一段时间之后都会失效,下次再去查询的时候,Alluxio需要去底层HDFS重新拉取元数据,这样的话就会造成元数据较高的延迟。那么如果把元数据同步设置的比较大,如果在这个较大的间隔范围中,数据产生了重算的话,这时候还是会产生数据不一致的问题。
针对这种情况,Alluxio做了一个优化,就是第二种的Active sync for HDFS,因为HDFS有一个inotify机制,就是说我们可以监听HDFS的inotify的机制来获取HDFS中的event,然后根据这个event,我们可以从中拿到我们要监控的一些目录,如果发生变更的话,我们相应地在Alluxio中也会将元数据重新进行同步。
但是这种inotify有一些弊端,首先,如果直接去监听整个HDFS集群的inotify的话,会对HDFS的集群有一定的压力。
第二,如果Alluxio用来处理inotify的话,对Alluxio也有一定的压力,因为像HDFS集群这种作业产生的话,它有时候会有一些偶发性或者突发性的情况,比如某个时刻它的数据开始要落到HDFS集群,这时候这个表可能有几十万或者上百万的数据过来,相当于几十万上百万的inotify的event,要通过Alluxio进行处理,这时候Alluxio也会有很大的压力。而且对于 HDFS的inotify,没法针对某些目录或某些节点进行inotify,因为inotify一开启,拿到的就是整个HDFS所有元数据变更的event,所以总体来说也不是特别灵活。
第三个没有采用Active sync的原因就是,我们现在的HDFS集群用的是社区的3.2.0版本,而且我们用的是Router-based federation的模式。在Router-based federation模式下,HDFS的Router节点不支持inotify机制,所以针对这种情况我们是怎么做的?我们先拷贝一份Alluxio集群中的元数据,然后去定期访问HDFS中的元数据,如果HDFS的元数据和我们拷贝出来的Alluxio元数据不一致的话,我们就会更新Alluxio的元数据。
其实这里还有一个优化,就是当我们将Alluxio和HDFS元数据进行对比的时候,我们没有必要对所有的元数据进行对比,因为在HDFS上当产生数据重算的时候,这个文件的父目录的last modify time肯定会发生变更,所以这种情况就决定,当HDFS和Alluxio元数据对比不一致的时候,我们只需要访问到HDFS最低一层的那个分区的目录的last modify time就可以了。
比如说我们有一个表的分区是三级分区,是年月日,如果当我们要对比这个表的元数据和和Alluxio的元数据有没有发生变更的时候,其实我们只需要关注HDFS这个表年月日到日期,也就是天级的目录,我们只需要关注天级目录的last modify time即可。当发现我们HDFS天级目录的last modify time,比Alluxio的更新, 也就是数值更大,那就说明这个元数据发生了变更,这时候我们去刷新一下Alluxio的元数据就可以了。

还有一个我们需要关注的就是Alluxio集群中TTL的管理。首先我们需要考虑一下,我们在我们的Alluxio集群中,应该保存多少元数据,就像我们的一个集群的话,我们实际上是大的集群有1500+ worker,每个worker我们给他配置70GB的memory的话,就是整个我们的底层HDFS Blocksize设成128兆,如果按这种算下来的话,其实我们Alluxio如果存满的话,我们只存了84万个block,如果再考虑到小文件,比方说我们把这个有一些小文件,我们再把这个远程再膨胀10倍的话,即便数据存满了,我们的Alluxio集群也只需要保存1000万的元数据就可以。其实Alluxio的每一个file会占用大约1KB的存储,这样1000万的云数据,大约只需要10GB内存就可以了,所以实际上就按这种场景的话,对于Alluxio元数据,我们是采用了heap的方式,而没有用那个rocksdb那种模式。
虽然说存满之后,Alluxio集群只需要1000万个元数据,但是因为有一些数据会过期, 我们如果要保持这种情况, 我们应该管理Alluxio,来保证Alluxio的元数据一直维持在千万级的一个量级。所以针对元数据这种情况,我们需要对它进行一些清理的操作,保证Alluxio存储的元数据,只要有元数据的话,这个元数据对应的数据也是在Alluxio的。这种情况下,针对我们数仓中的表缓存在Alluxio中的情况,我们是给每一个表都是设置了TTL的。
当TTL到期的时候,像Alluxio有两种的TTLAction,一个是free,一个delete,free的话只是把数据释放了,但是它的元数据还是保存在Alluxio集群中,对于这种场景的话,如果你的数据不在,我们后面用到它的元数据,也就是命中它的概率也比较低,这时候其实我们没有必要再把它的元数据保存在Alluxio中。Alluxio另一种的那个TTLAction 是delete,但是Alluxio默认的delete,会把元数据和底层的数据都删掉,这种情况我们是无法接受的,因为正常的话我们的数据,像我们数仓数据持久化到底层的,这个数据是肯定是不能被删除的。
所以针对这种情况,我们是把Alluxio的策略做了一定的更改,就相当于我们删除的时候,我们TTL到期的时候,我们删除数据只是把Alluxio中的数据free掉,然后同时把metadata从Alluxio移除,底层的HDFS我们是不进行任何操作的。同时我们还做了一个优化,就是TTL操作只是作用在表的分区上面,当检测到这个分区的TTL到期之后,我们是递归地去删除,我们设置TTL的时候不是针对所有的数据或者文件都设置TTL,这样的话就相当于Alluxio要处理了TTL的event时间也比较多,所以我们的TTL策略只是落到表的最底层的那个分区上面,然后删除的时候是通过递归的方式来删除。
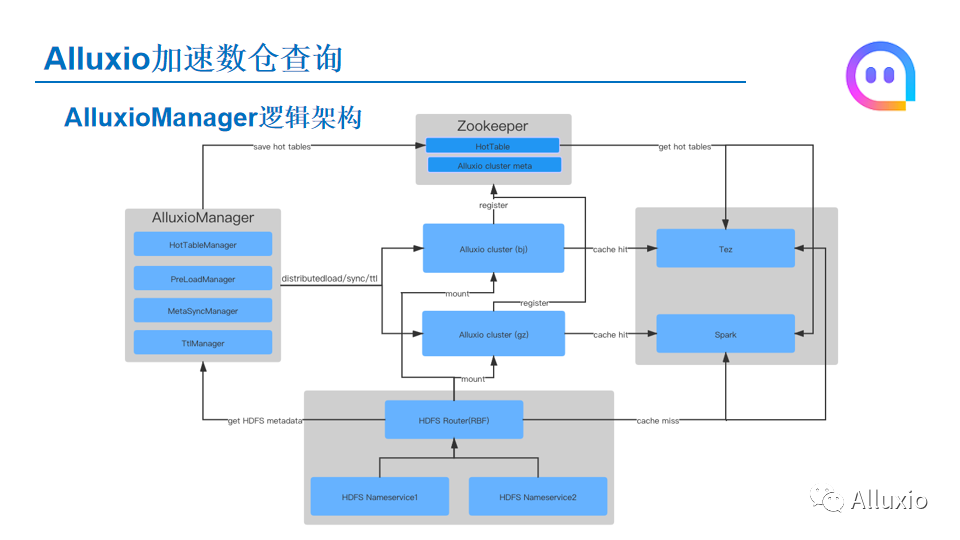
这个就是我们的整个架构,针对我们刚才说的这种场景,我们开发了一个AlluxioManager工具来管理我们说到的这些应用场景,首先这个Alluxio Manager里面有一个HotTableManager,HotTableManager会定期默认按天来生成热表,我们会把这个热表存储到Zookeeper的一个znode上,然后后面的引擎查询的时候,就会从Zookeeper拿HotTable,如果说要查询的数据在HotTable就说明这个数据应该走Alluxio,然后它就会去Alluxio进行查询。HotTable生成之后,我们AlluxioManager里面还有一个PreLoadManager,当我们检测到HotTable的数据生成之后,我们就会通过Alluxio的distribute,把数据load到Alluxio,后面查询的时候就能直接命中了。还有一个模块就是我刚才说的metadata sync manager,如果检测到HDFS上的数据发生了变更,它会同步Alluxio的元数据。
另一个就是刚才说到TTL的管理,我们是通过一个TTLManager来进行管理的,我们下面的存储是使用HDFS 3.2.0的RBF的模式,就是HDFS Router的这种方式。
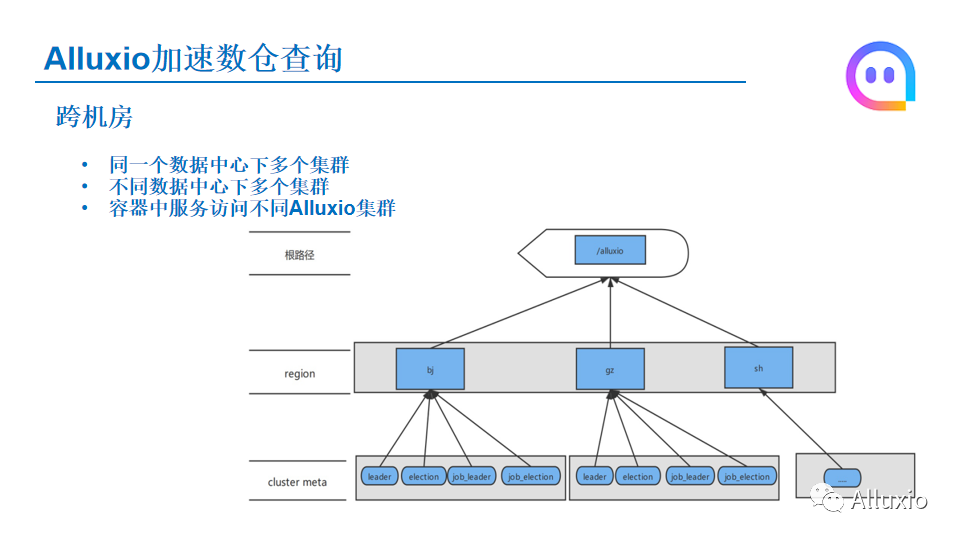
我们还做了其他的一些更改,有一个就是跨机房的功能,考虑到几个场景,我们可能在一个数据中心下边部署多个Alluxio集群,默认Alluxio在那个ZK上注册的时候,节点都是一系列固定的,就是在一个配置的节点下是leader还有job leader的那些界面。那如果我们在同一个机房下有一个ZK集群,而我们两个Alluxio集群同时注册到这一个ZK集群,这样就会发生问题。
还有一种情况是我们有不同数据中心,可能拥有多个集群,也希望可以做统一的管理。
第三种情况是说可能有一些作业是部署在容器中,然后容器中要放Alluxio也需要有一个统一的模式,而不是根据不同的集群来配给这个容器中应用中不同的配置来访问。针对这种情况,我们做了一个Alluxio集群跨机房的改造,默认的话根节点的话就是一个/Alluxio,下一层的话是分Region,也就是不同的地域,比方说北京、广州、上海,然后再下边一层就是每一个地域下边的Alluxio集群提取的一些信息,当你访问的时候,你根据你的Region的信息来访问你对应的下面的Alluxio集群。
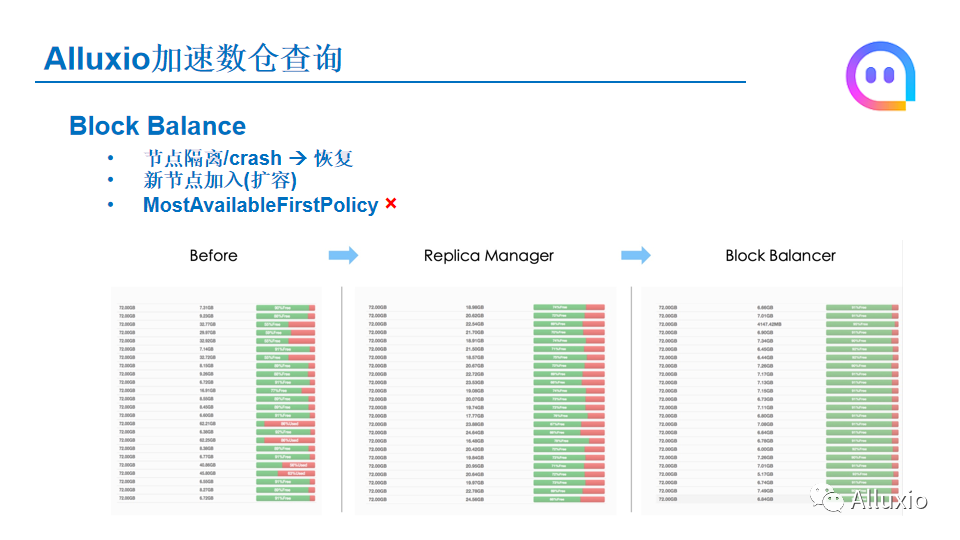
另一个我们做到的改动就是Block Balance这个功能。实际应用中Alluxio worker可是部署在其中,会出现节点的一些隔离,或者是你这个节点crash再到恢复。这时候你加载到再重新加入的话,可能新起的节点它重新加载之后,它保存的数据是可能就是百分百空的。还有一种情况,就是我们要对Alluxio集群进行扩容,新加入的节点的话刚加进去之后,肯定你这个节点worker它的那个使用的情况肯定是0的,这时其他的节点可能它的那个存储的空间已经占用了很多了。针对这种情况下,实际上那个Alluxio有一个Most available first policy,这种情况下,就是说你加载一个数据的时候,会优先选择最空闲的来进行加载。
但是这个策略有一个弊端,就是如果数据量比较大的话,你先加入了几个节点,当你访问一个数据的时候,新加入这几个节点带宽就会被打满,因为他们刚开始他们的使用空间设定,所以这时候你加的数据都会加载到这几个新加入的节点上面,这时候就会造成整个节点的带宽被打满的情况。同样的,如果使用Most available first policy,那今天带宽没有打满,后面去访问的话,因为你刚刚加的数据都在新加入的几个节点上,后面访问的话也会对造成这几个节点的数据的一个热点的问题。同样有一定的隐患。
针对这种情况,我们是开发了一个Block Balance的功能,下面的图就是我们的一个实际使用情况,在不进行Balance之前,各个节点的使用量是不同的,进行Block Balance管理之后发现,整体的使用率就会比较平均。

实际过程中还有几个事情要考虑:一个是滚动升级-如果我们进行版本变更的话,Alluxio默认会有一个check Version功能,如果这时候你进行了版本之间不同的上新话,这种情况是有问题的。另外像load Config这种功能,实际中操作是我们认为是没有必要的,所以我们把这两个功能都做了一些配置化的管理,设置开关,这些功能可以进行关闭。
另一个就是说因为我们的HDFS是基于是RBF的模式,同时从HDFS 3.0开始,它是支持EC的,然后我们这个数据也是上线了EC的功能,Alluxio默认是不支持EC的,这个是我们要修复的,我们提了一个建议。
另外的话就是Alluxio社区的版本是不支持Kerberos的,然后我们的整个数据平台的话需要有适用的Kerberos改造,我们做了一个支持Kerberos这个功能的开发,最后测试看Kerberos的话整体的性能会有大约10%的下降。
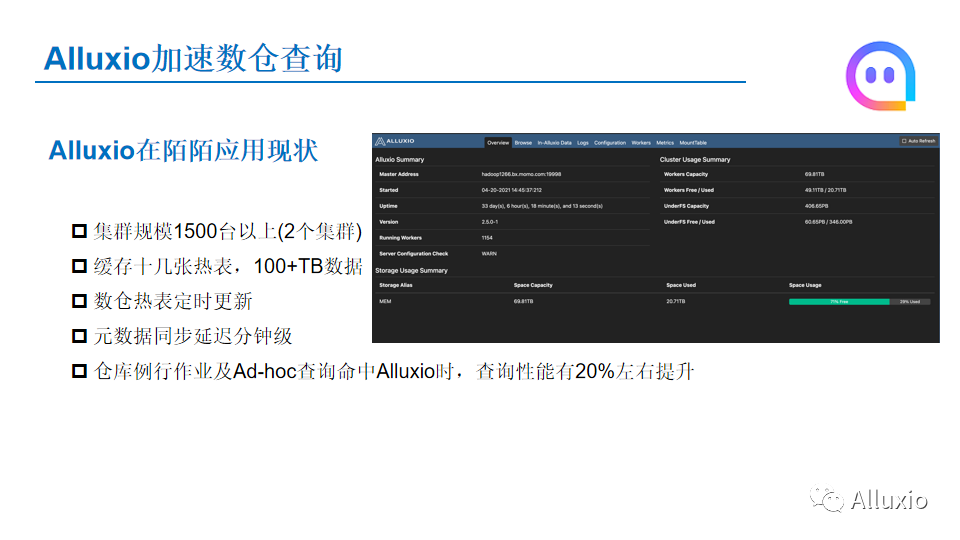
下面就是Alluxio在陌陌数仓应用的现状。在数仓业务方面,我们集群的规模是1500台以上,我们有两个集群,然后每天我们会缓存几十张热表,大概有100多TB的数据,热表是每天都会更新的,我们的元数据发生变更的话延迟可以控制在分钟级别。我们的仓库例行作业和Ad-hoc的作业已经全部开启了Alluxio功能,当他们查询到热点的时候就会直接命中并通过Alluxio进行数据的访问,整体查询系统有20%左右的提升。
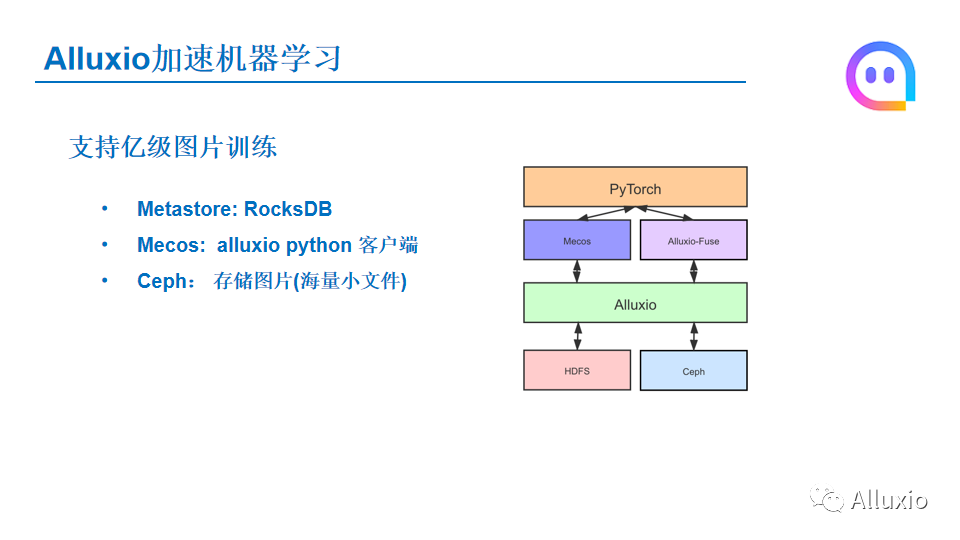
接下来说一下Alluxio在陌陌机器学习场景中的几个应用,一个应用是我们支持亿级图片训练的场景,右边是我们整个训练的架构,最上层我们是通过Pytorch进行训练。那下一层的话是我们通过Mecos,这是我们自己开发的基于Alluxio加PC协议的Python的客户端,它兼容了Alluxio 的gRPC协议,可以直接通过Python的这个客户端来访问Alluxio的集群。然后同时我们也会用AlluxioFuse的模式进行数据的读取。然后底层Alluxio的话,有一部分数据是放在HDFS的,但是大部分我们训练的图片是放在底层的对象存储Ceph上面,然后因为我们这边是支持亿级的训练,所以在图片训练场景下,我们的这个Alluxio集群是到Metastore,我们是通过RocksDB这种模式,目标是最终是能支持我们所有的图片。然后Mecos这块就是刚才说的,是自研的一个Alluxio的一个客户端,然后Ceph的话就是存储海量的图片小文件,这是我们在以及图片训练当中的一个场景。

我们在亿级图片训练过程中遇到的两个问题:一个是底层元数据的交互很慢,上传图片的时候要通过访问Alluxio来判断这个数据有没有已经上传到集群当中。Alluxio访问底层的那个对象存储时是通过一个前缀匹配来判断这个对象有没有存在,这种情况特别耗时,我们发现这种前缀匹配有时候超过10秒钟都没有反应。针对这种情况,我们通过MIME逻辑,就是判断如果是一个规则图片的话,应该有比方说.JPG/.TXT这种后缀,如果是这种后缀我们才认为是一个文件,然后才会去访问底层的对象存储,这样整个的访问的吞吐从原先的就最长十几秒降到了平均一二十毫米左右。
另外就是一个对象存储的ACL控制,Alluxio挂在底层对象存储的时候,它是通过一个的AccessKey和SecretKey这一种身份来挂的,但是我们有很多用户,这个地方我们做了改进,就是当用户访问底层的流程的时候,他们是用自己的AccessKey和SecretKey来访问底层的Ceph,这样可以实现不同用户的ACL的控制。

另外两个Alluxio和我们Mecos在机器学习应用场景,一个是推荐系统模型的拉取,推荐的话会有几十个模型,可能每隔5分钟或10分钟就会更新一下推荐的模型。实际应用的场景是我们把这个推荐模型先上传到HDFS,然后通过Mecos客户端调用Alluxio DistributedLoad,然后把数据加载到Alluxio。默认设置Replias:10,加载完成之后,那个推荐系统后续的线上作业就会通过Mecos从Alluxio去加载已经拉取的数据。
第二个是在ANN系统中拉取索引进行加速。ANN系统是一个近似图像检索的系统,在这个检索系统中会生成一些索引,每过一段时间经过更新后会要重新加载到这个系统中。这时我们也是通过Alluxio提供了一个加速,当它生成索引的时候,也是通过Mecos客户端把这个索引上传到HDFS或者是对象存储,之后数据会加载Alluxio,然后索引系统中所有的 worker节点会通过Mecos从Alluxio拉取索引。

后续主要的工作方向有两个:一个是我们正在做的在线离线混合部署场景,那后面我们会把Presto和Spark部署到在线离线混合部署的集群中,然后通过Alluxio来进行加速;第二个是Alluxio和机器学习的场景,虽然现在我们已经上线了,但是Alluxio Fuse这种模式在速度上能够进一步的提升,目前的实际测试中的图片RPS吞吐速度可以达到6000,希望可以达到8000或者10000的速度。
今天我的分享就到这里,谢谢大家。








